
初识CANN:打开昇腾AI计算的黑盒子
本文介绍了华为昇腾AI计算平台的核心软件栈CANN(Compute Architecture for Neural Networks)。CANN作为连接AI应用与昇腾硬件的桥梁,包含硬件抽象层、开发工具链、计算图优化和算子开发体系四大支柱。文章详细解析了AscendCL编程接口、图引擎工作原理和内存管理体系,并提供了模型训练加速、推理服务和自定义算子开发等实战场景示例。最后给出了从基础入门到项目实
初识CANN:打开昇腾AI计算的黑盒子
第一次听说“CANN”时,我以为又是一个深奥的底层框架。但当真正开始学习后,才发现它是开启昇腾AI算力的关键钥匙。
从疑惑到理解:我的CANN认知之旅
初次接触CANN时,面对陌生的术语和全新的概念,我感到有些无所适从——AscendCL、图引擎、AI Core、DVPP……这些到底是什么?直到我开始动手实践,才逐渐发现CANN的独特价值。
如果你也正在准备学习CANN,或许会和我有相似的疑问:
- 什么是CANN?它解决什么问题?
- 昇腾NPU和传统处理器有什么不同?
- 作为一个开发者,我需要掌握哪些核心概念?
这篇文章将分享我的学习心得,帮助你快速建立对CANN的整体认知。
CANN全景图:不只是硬件驱动
CANN(Compute Architecture for Neural Networks),即神经网络计算架构。但这个定义过于简单,容易让人低估它的复杂性。
更准确地说,CANN是**连接AI应用与昇腾硬件的桥梁**,是一个完整的异构计算软件栈。它包含从底层驱动到上层框架适配的完整解决方案。
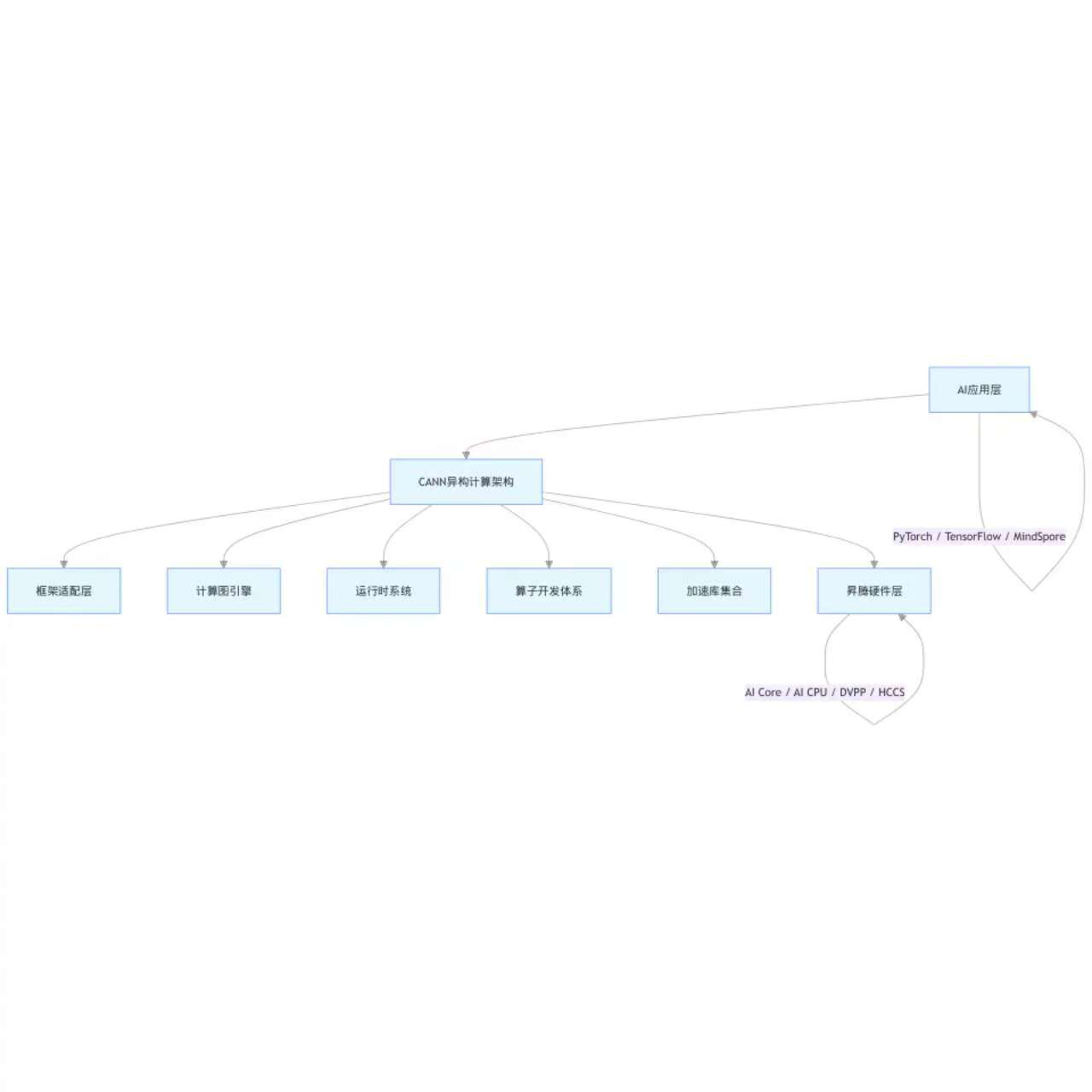
核心定位:CANN的四大支柱
1. 硬件抽象层:让AI计算更简单
CANN的首要任务是**屏蔽硬件复杂性**。昇腾NPU采用了与传统CPU/GPU不同的架构设计:
- **AI Core**:专为矩阵运算设计的计算核心
- **Cube单元**:执行矩阵乘法的专用硬件
- **Vector单元**:处理向量运算
- **DVPP**(Digital Vision Pre-Processing):硬件级图像预处理
CANN通过统一的编程接口,让开发者无需深入了解这些硬件细节。
2. 开发工具链:全流程支持
CANN提供的核心工具
├── MindStudio # 集成开发环境(类似IDE)
├── Ascend-CLI-Toolkit # 命令行工具集
├── msopgen # 算子代码生成器
├── msopst # 算子编译工具
└── msprof # 性能分析工具
```
3. 计算图优化:智能调度引擎
这是CANN最强大的特性之一。计算图引擎可以自动进行:
- **算子融合**:将多个小算子合并,减少内存搬运
- **内存复用**:智能管理Tensor生命周期
- **并行调度**:发现计算图中的并行机会
C
// 图执行的基本流程
aclmdlDesc* modelDesc;
aclmdlDataset* input, *output;
// 1. 加载模型(包含计算图信息)
aclmdlLoadFromFile("model.om", &modelDesc);
// 2. 准备输入输出
input = aclmdlCreateDataset();
output = aclmdlCreateDataset();
// 3. 执行(图引擎自动优化)
aclmdlExecute(modelDesc, input, output);
// 图引擎内部自动执行:
// - 分析算子依赖关系
// - 调度到合适的计算单元
// - 管理内存分配与释放4. 算子开发体系:自定义计算能力
当内置算子无法满足需求时,CANN提供了完整的自定义算子开发方案:
cpp
// 使用Ascend C开发自定义算子的基本结构
class CustomKernel {
public:
__aicore__ void Init(InitParam* param) {
// 初始化tiling参数
tileLength = param->tileLength;
}
__aicore__ void Process() {
// 核心计算逻辑
LocalTensor<float> inLocal = inQueue.DeQue<float>();
LocalTensor<float> outLocal = outQueue.AllocTensor<float>();
// 向量化计算
for (int i = 0; i < tileLength; i += 8) {
// 一次处理8个元素(向量化)
float8_t vecIn = Load<float8_t>(&inLocal[i]);
float8_t vecResult = Compute(vecIn);
Store(&outLocal[i], vecResult);
}
outQueue.EnQue(outLocal);
inQueue.FreeTensor(inLocal);
}
private:
TQue<QuePosition::VECIN> inQueue;
TQue<QuePosition::VECOUT> outQueue;
int tileLength;
};核心组件深度解析
AscendCL:统一编程接口
AscendCL(Ascend Computing Language)是CANN的运行时API,提供了设备管理、内存管理、任务调度等基础能力。
```c
// 典型开发流程
#include "acl/acl.h"int main() {
// 1. 初始化
aclInit(NULL);
// 2. 设备管理
aclrtSetDevice(0);
// 3. 内存管理
void* hostPtr;
void* devicePtr;
size_t size = 1024 * 1024;
// 申请可分页主机内存
aclrtMallocHost(&hostPtr, size);
// 申请设备内存
aclrtMalloc(&devicePtr, size, ACL_MEM_MALLOC_HUGE_FIRST);
// 4. 数据搬运(主机→设备)
aclrtMemcpy(devicePtr, size,
hostPtr, size,
ACL_MEMCPY_HOST_TO_DEVICE);
// 5. 执行计算
// ... 调用算子或模型推理
// 6. 资源释放
aclrtFree(devicePtr);
aclrtFreeHost(hostPtr);
aclrtResetDevice(0);
aclFinalize();
return 0;
}
```
图引擎:智能计算调度
图引擎是CANN高性能的关键。它采用“描述-优化-执行”的三段式工作流程:
1. **描述阶段**:构建计算图,定义算子及其依赖关系
2. **优化阶段**:自动进行算子融合、内存优化、并行化
3. **执行阶段**:高效调度到硬件执行
内存管理体系
CANN采用统一内存架构,但提供了灵活的内存管理策略:
```c
// 内存类型选择
typedef enum {
ACL_MEM_MALLOC_NORMAL_ONLY, // 普通内存
ACL_MEM_MALLOC_HUGE_FIRST, // 大页内存优先
ACL_MEM_MALLOC_HUGE_ONLY, // 仅大页内存
ACL_MEM_MALLOC_DMA_ONLY, // DMA内存
} aclrtMemMallocPolicy;
// 根据应用场景选择合适的内存类型
// 训练场景:大页内存减少TLB miss
// 推理场景:普通内存提高分配速度应用场景实战
场景一:AI模型训练加速
在大型模型训练中,CANN通过以下方式提供加速:
场景二:高性能推理服务
```c
// 高性能推理服务框架
class InferenceService {
public:
void Init(const std::string& modelPath) {
// 加载模型
modelId = 0;
aclmdlLoadFromFile(modelPath.c_str(), &modelId);
// 创建流池(提高并发处理能力)
aclrtCreateStream(&stream);
// 预分配输入输出内存
AllocateBuffers();
}
std::vector<float> Infer(const std::vector<float>& input) {
// 异步推理
aclmdlAsyncExecute(modelId, inputDataset,
outputDataset, stream);
// 流同步
aclrtSynchronizeStream(stream);
// 获取结果
return GetResult();
}
private:
uint32_t modelId;
aclrtStream stream;
aclmdlDataset* inputDataset;
aclmdlDataset* outputDataset;
};场景三:自定义算子开发
实际案例:开发一个融合算子(LayerNorm + Activation)
```cpp
// 融合算子比单独执行两个算子性能提升约40%
class LayerNormActivationKernel {
public:
__aicore__ void Process() {
// 1. 从Global Memory搬运数据到Local Memory
GlobalTensor<float> inputGlobal = GetInput();
LocalTensor<float> inputLocal = inQueue.AllocTensor<float>();
CopyGlobalToLocal(inputGlobal, inputLocal);
// 2. 计算均值方差(向量化)
float mean = ReduceMean(inputLocal);
float var = ReduceVariance(inputLocal, mean);
// 3. LayerNorm计算
LocalTensor<float> normed = ApplyLayerNorm(inputLocal, mean, var);
// 4. Activation(如GELU)
LocalTensor<float> activated = ApplyGELU(normed);
// 5. 写回结果
outQueue.EnQue(activated);
}
};学习路径建议
基于个人学习经验,建议按以下路径逐步深入:
阶段一:基础入门(1-2周)
1. **环境搭建**:安装CANN Toolkit、配置开发环境
2. **概念理解**:掌握算子、Tensor、计算图等基础概念
3. **第一个程序**:运行Hello World示例,理解基本流程
阶段二:API掌握(2-3周)
1. **AscendCL编程**:熟练使用设备管理、内存管理API
2. **模型部署**:学习模型加载、推理执行流程
3. **性能分析**:使用msprof工具进行性能分析
阶段三:深度开发(3-4周)
1. **Ascend C编程**:掌握核函数开发基础
2. **算子开发**:实现自定义算子
3. **性能优化**:学习向量化、双缓冲等优化技术
阶段四:项目实战(持续)
1. **完整项目**:参与实际AI项目开发
2. **性能调优**:深入理解硬件特性,进行极致优化
3. **框架适配**:了解PyTorch/TensorFlow插件开发
开发工具与调试技巧
MindStudio使用技巧
MindStudio是CANN的官方IDE,提供:
- 图形化性能分析
- 算子调试支持
- 内存泄漏检测
- 自动代码生成
调试技巧:
c
// 1. 错误检查
aclError ret = aclrtMalloc(&ptr, size, policy);
if (ret != ACL_SUCCESS) {
const char* errMsg = aclGetRecentErrMsg();
printf("Error: %s\n", errMsg);
return;
}
2. 同步点调试
aclrtSynchronizeStream(stream); // 确保此前操作完成
3. 内存检查
aclrtMemset(ptr, 0xAA, size); // 填充特殊值检测越界
结语:从理解到掌握
学习CANN是一个循序渐进的过程。初期可能会感到概念繁多、难以入手,但通过实际动手编程,你会逐渐发现它的设计哲学和强大能力。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:
https://www.hiascend.com/developer/activities/cann20252?tab=overview

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)