
基于多模态手语与情感识别系统
多模态识别系统,该系统通过MediaPipeHolistic技术实时跟踪人体特征点(面部、手部和姿态),实现手语到文本转换及情感识别功能。系统核心包括三个模块:手语识别模块处理肢体动作特征点,情感识别模块分析面部特征点序列,综合预测模块融合双模型输出。技术架构基于TensorFlow/Keras框架,采用数据增强、早停机制和学习率调整等优化策略。MP_Data数据集提供标准化特征点数据,包含3种手
一、项目概述
本项目是一个多模态识别系统。系统基于 MediaPipe Holistic(MP Holistic)技术,实现实时跟踪人体特征点(包括面部、左右手和身体姿态),并完成手语句子识别与情感识别功能,最终融合两个模型的预测结果,为每一帧提供综合预测。
项目核心目标包括:
- 作为中介辅助工具,实现手语到文本的转换
- 构建情感感知系统,改善人机交互体验
MP_Data 数据集介绍
一、数据集基本信息
MP_Data 是多模态手语与情感识别系统(Multimodal Sign Language & Emotion Recognition)的核心数据集,主要用于训练和验证手语识别与情感识别模型。该数据集基于 MediaPipe Holistic 技术提取的人体特征点数据构建,包含手语动作序列及对应的情感相关信息。

2. 数据文件格式
每个动作序列文件夹(如areyouok/0/)中包含若干以帧编号命名的.npy文件(如0.npy、1.npy等),每个文件存储一帧的特征点数据,具体包含:
- 25 个上半身姿态特征点
- 468 个面部特征点
- 42 个手部特征点(每只手 21 个)
这些特征点数据通过 MediaPipe Holistic 实时跟踪提取,涵盖了手语识别所需的肢体、面部及手部关键动作信息,同时为情感识别提供了面部表情的基础特征。
三、数据规模
- 包含 3 种手语动作类别:
areyouok、idontunderstand、idontknow - 每个动作类别包含 50 个动作序列(编号 0-49)
- 每个序列包含多帧特征点数据(具体帧数由动作时长决定)
四、数据增强
为提升模型泛化能力,数据集在训练阶段会进行增强处理,包括:
- 帧级增强:对单帧特征点应用
augment_landmarks函数进行变换 - 序列级增强:对连续帧序列应用
augment_sequence函数进行时序调整
增强后的数据与原始数据共同组成训练集,且保持标签一致性(增强数据与原始数据属于同一动作类别)。
五、数据用途
- 手语识别模型:基于肢体、手部及面部特征点序列,训练识别 "areyouok"、"idontknow"、"idontunderstand" 等手语句子的能力
- 情感识别模型:基于面部特征点等信息,提取与情感相关的特征,实现情感状态识别
- 多模态融合:为手语与情感的联合识别提供统一的特征输入,支持模型融合与综合预测
该数据集是系统实现 "手语到文本转换" 和 "情感感知人机交互" 核心目标的基础,通过标准化的特征点数据,确保了模型训练与推理的一致性。
二、数据集结构
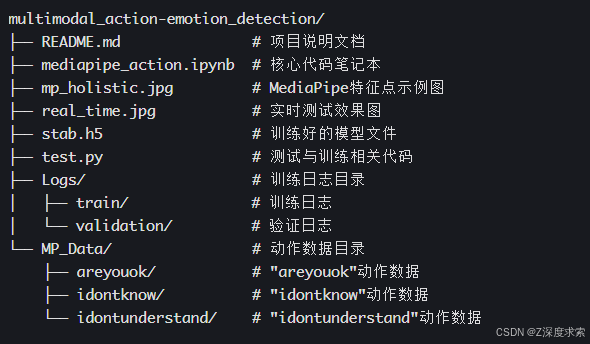
1. 目录组织
数据集采用三级目录结构,整体组织如下:
二、核心功能模块
1. 手语识别模块
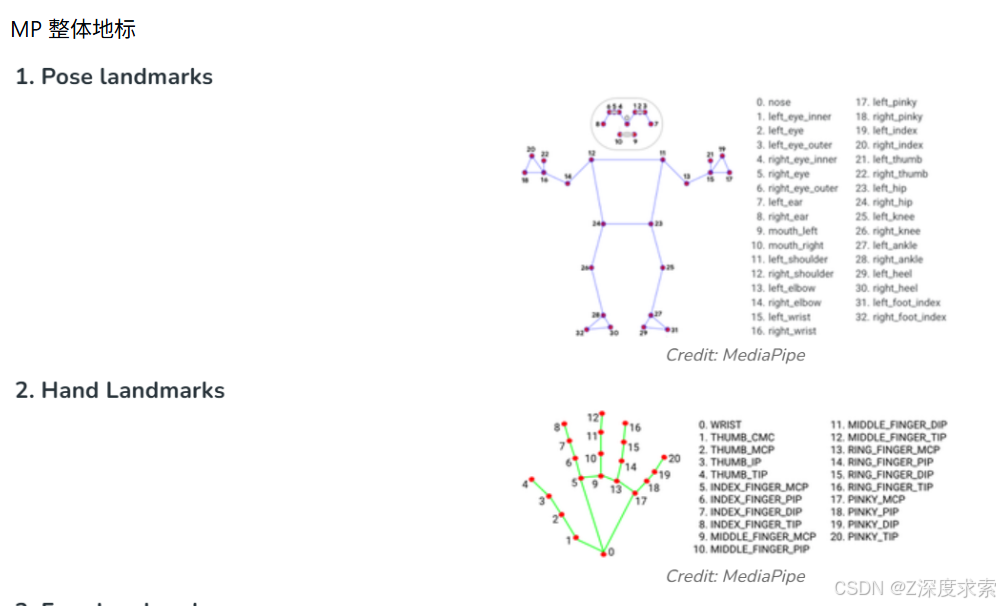
- 跟踪范围:手臂、面部及身体动作
- 特征点数据:
- 25 个上半身姿态特征点
- 468 个面部特征点
- 每只手 21 个特征点(共 42 个手部特征点)
2. 情感识别模块
在该多模态手语与情感识别系统中,情感识别模块主要通过处理面部特征点等多维度信息实现对用户情感状态的识别,其核心逻辑与技术路径可结合项目整体框架推断如下:
1. 核心特征来源
情感识别的核心输入是通过 MediaPipe Holistic 提取的468 个面部特征点,这些特征点涵盖了面部关键区域(如眉毛、眼睛、嘴巴、脸颊轮廓等)的位置信息。这些特征点的动态变化(如嘴角上扬 / 下垂、眉毛抬起 / 皱起、眼睛张开 / 闭合程度等)直接反映了情绪相关的面部表情变化,是情感识别的关键依据。
此外,系统可能结合其他多维度信息辅助识别(如身体姿态特征点中与情绪相关的肢体语言,例如肢体紧绷 / 放松状态等),形成多模态融合的情感特征输入。
2. 特征处理与建模
- 特征预处理:对提取的面部特征点序列进行标准化(如坐标归一化,消除不同人脸大小、距离的影响)、降噪等处理,确保特征稳定性。
- 序列特征提取:由于情感表达是动态的(如微笑的过程、皱眉的变化),系统可能对连续帧的面部特征点序列进行时序特征提取(例如通过循环神经网络 RNN、长短时记忆网络 LSTM 等),捕捉表情的动态变化模式。
- 模型训练:使用标注了情感标签(如开心、悲伤、愤怒、中性等)的数据集训练情感识别模型。训练过程中同样集成了项目中采用的优化策略:
- 结合
EarlyStopping回调函数监控验证损失,防止过拟合并提前终止无效训练; - 通过
ReduceLROnPlateau动态调整学习率,提升模型收敛效果。
- 结合
3. 与手语识别的融合
情感识别模型与手语识别模型的预测结果会被综合融合,最终为每一帧输出统一的预测结果。这种融合可能基于规则(如权重分配)或学习型方法(如通过融合层学习最优组合方式),实现 “手语内容 + 情感状态” 的联合识别,从而更全面地理解用户意图。
3. 综合预测模块
在多模态手语与情感识别系统中,模型融合模块负责整合手语识别与情感识别的输出结果,为视频流每一帧生成统一的综合预测。其核心逻辑是通过多维度信息互补,提升对用户意图的完整理解(手语内容 + 情感状态)。
一、融合基础:双模型输出特征
-
手语识别模型输出针对每一帧对应的动作序列,输出手语语义分类结果(如 “areyouok”“idontknow” 等预设句子类别),通常以概率分布形式呈现(如
[0.92, 0.03, 0.05]表示属于第一类的概率为 92%)。 -
情感识别模型输出基于面部及肢体特征点,输出情感类别概率分布(如 “开心”“中性”“悲伤” 等),例如
[0.85, 0.10, 0.05]表示 “开心” 的概率为 85%。
二、融合策略实现
1. 特征级融合(模型内部融合)
在模型训练阶段,将手语特征(肢体 / 手部关键点序列)与情感特征(面部关键点序列)拼接为联合输入,通过共享层学习跨模态关联:
python
运行
# 示例:特征拼接逻辑
sign_features = sign_model(input_sign) # 手语特征向量(如256维)
emotion_features = emotion_model(input_emotion) # 情感特征向量(如128维)
combined_features = tf.concat([sign_features, emotion_features], axis=-1) # 拼接为384维
final_output = dense_layer(combined_features) # 综合预测层
2. 决策级融合(推理阶段融合)
在实时推理时,对两个模型的输出结果进行加权融合,生成最终预测:
python
运行
# 示例:决策级加权融合
sign_pred = sign_model.predict(frame_data) # 手语预测概率
emotion_pred = emotion_model.predict(frame_data) # 情感预测概率
# 加权融合(权重可通过验证集优化)
weight_sign = 0.7 # 手语内容权重
weight_emotion = 0.3 # 情感状态权重
combined_pred = {
"sign": sign_pred.argmax(), # 最可能的手语类别
"emotion": emotion_pred.argmax(), # 最可能的情感类别
"confidence": (sign_pred.max() * weight_sign + emotion_pred.max() * weight_emotion)
}

三、帧级综合预测输出
对于视频流中的每一帧,综合预测结果以结构化形式呈现,包含:
- 手语语义(如 “areyouok”)
- 情感状态(如 “开心”)
- 综合置信度(融合双模型的可靠性评分)

三、技术架构
1. 技术栈
- 特征提取:MediaPipe Holistic
- 深度学习框架:TensorFlow/Keras
- 数据处理:NumPy、OS(文件操作)
- 可视化工具:TensorBoard(训练日志可视化)
2. 系统架构
- 数据层:存储原始动作序列数据及增强后数据(MP_Data 目录)
- 特征提取层:基于 MediaPipe Holistic 提取多维度人体特征点
- 模型训练层:使用 TensorFlow/Keras 构建模型,结合训练优化策略
- 推理层:实时处理输入数据,输出综合预测结果
- 日志层:记录训练与验证过程数据(Logs 目录)
3. 工作流程
- 实时采集视频流,通过 MediaPipe Holistic 提取人体特征点
- 对特征点序列进行预处理(训练阶段包含数据增强)
- 输入至手语识别模型和情感识别模型进行推理
- 融合两个模型的输出,生成综合预测结果
- 输出最终结果(文本转换或情感状态)
四、关键技术细节
1. 模型训练优化策略
-
早停机制(EarlyStopping):
python
运行
-
early_stop = EarlyStopping( monitor='val_loss', # 监控验证集损失(推荐)或训练集损失 patience=20, # 20个epoch无改善则停止训练 restore_best_weights=True # 恢复最佳权重 ) -
学习率调整(ReduceLROnPlateau):
运行
reduce_lr = ReduceLROnPlateau( monitor='val_loss', # 监控验证集损失(推荐)或训练集损失 factor=0.5, # 学习率变为原来的50% patience=10, # 10个epoch无改善则调整 min_lr=1e-6 # 最小学习率下限 ) -
训练配置:
运行
history = model.fit( X_train, y_train, epochs=500, validation_split=0.1, # 10%数据用于验证(可选) callbacks=[tb_callback, early_stop, reduce_lr] # 集成回调函数 )
2. 数据处理与增强
- 数据加载:从 MP_Data 目录加载动作序列数据,每个动作包含多个序列,每个序列包含指定帧数的特征点数据
- 数据增强:
运行
# 为每个序列添加增强副本 aug_window = [] for frame in window: aug_window.append(augment_landmarks(frame)) # 帧级增强 aug_window = augment_sequence(aug_window) # 序列级增强 - 数据集扩充:原始数据与增强数据共同组成训练集,保持标签一致性
五、项目结构
六、应用展示(主页联系获取代码)
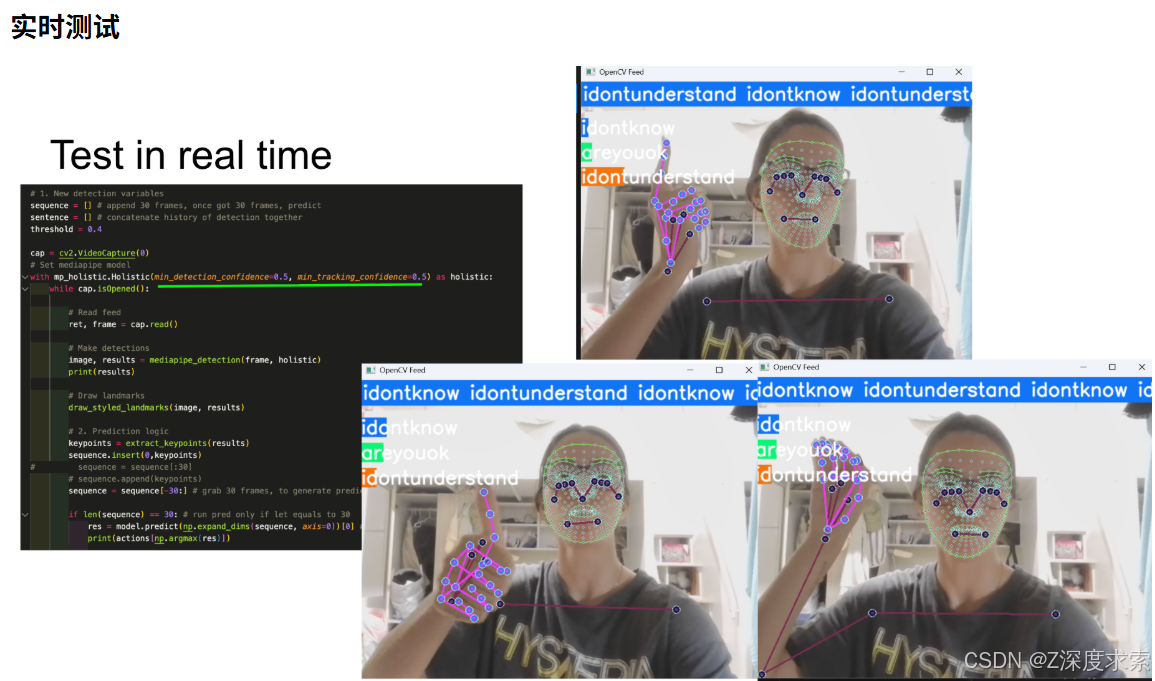
系统支持实时测试功能,可对预设的手语句子进行识别与情感分析,实时测试效果参考 real_time.jpg。


鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)