
初识CUDA和cuDNN
作为运维人员,理解CUDA和cuDNN对于管理GPU训练环境至关重要。安装CUDA工具包2. cuDNN安装下载和安装🐳 在K8s环境中的配置1. 节点准备和检查节点标签和污点安装NVIDIA设备插件2. 容器镜像构建基础Dockerfile示例3. K8s资源定义GPU Pod配置🔧 运维维护指南1. 版本兼容性管理版本兼容性矩阵框架版本CUDA版本cuDNN版本驱动版本PyTorch 2.
·
作为运维人员,理解CUDA和cuDNN对于管理GPU训练环境至关重要。
简介
🔍 CUDA和cuDNN基础概念
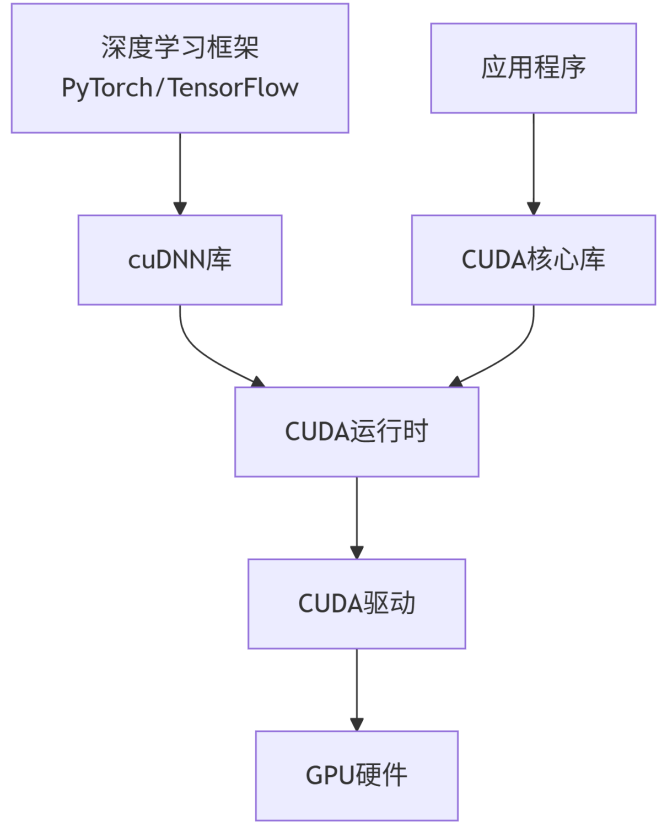
CUDA(Compute Unified Device Architecture)
- 是什么:NVIDIA推出的并行计算平台和编程模型
- 作用:让开发者能够使用GPU进行通用目的计算,而不仅仅是图形渲染
- 核心组件:
- CUDA工具包(编译器、调试器、库)
- CUDA驱动(GPU硬件接口)
- CUDA运行时(执行环境)
cuDNN(CUDA Deep Neural Network library)
- 是什么:NVIDIA提供的深度学习加速库
- 作用:为深度神经网络提供高度优化的基础操作实现
- 核心功能:
- 卷积、池化、归一化等操作的GPU加速
- 与主流深度学习框架深度集成
- 针对不同GPU架构的优化
🏗️ 技术架构关系
🛠️ 安装与配置
1. CUDA安装
检查系统兼容性
# 检查GPU是否支持CUDA
lspci | grep -i nvidia
# 检查当前驱动版本
nvidia-smi
# 检查Linux内核版本
uname -r
# 检查GCC版本
gcc --version
安装CUDA工具包
# 方法1:使用NVIDIA官方包(以Ubuntu 20.04为例)
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
sudo sh cuda_11.8.0_520.61.05_linux.run
# 方法2:使用包管理器
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
sudo apt-get update
sudo apt-get install cuda-11-8
# 配置环境变量
echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
2. cuDNN安装
下载和安装
# 1. 从NVIDIA开发者网站下载对应版本的cuDNN
# 需要注册NVIDIA开发者账号
# 2. 解压并安装(以cuDNN 8.x for CUDA 11.x为例)
tar -xzvf cudnn-11.3-linux-x64-v8.2.1.32.tgz
sudo cp cuda/include/cudnn*.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
# 3. 验证安装
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
🐳 在K8s环境中的配置
1. 节点准备和检查
节点标签和污点
# 为GPU节点打标签
kubectl label nodes <node-name> hardware-type=gpu
kubectl label nodes <node-name> nvidia.com/gpu.present=true
# 检查节点GPU资源
kubectl describe node <node-name> | grep -A 10 "Capacity"
安装NVIDIA设备插件
# 使用Helm安装
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update
helm install nvidia-device-plugin nvdp/nvidia-device-plugin --namespace kube-system --version 0.14.1
# 或者使用DaemonSet
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.14.1/nvidia-device-plugin.yml
2. 容器镜像构建
基础Dockerfile示例
FROM nvidia/cuda:11.8.0-runtime-ubuntu20.04
# 安装cuDNN
RUN apt-get update && apt-get install -y --no-install-recommends \
libcudnn8=8.6.0.*-1+cuda11.8 \
libcudnn8-dev=8.6.0.*-1+cuda11.8 \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# 安装Python和PyTorch
RUN apt-get update && apt-get install -y python3 python3-pip
RUN pip3 install torch==2.0.1+cu118 torchvision==0.15.2+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
# 设置环境变量
ENV CUDA_HOME=/usr/local/cuda
ENV PATH=${CUDA_HOME}/bin:${PATH}
ENV LD_LIBRARY_PATH=${CUDA_HOME}/lib64:${LD_LIBRARY_PATH}
WORKDIR /app
COPY . .
3. K8s资源定义
GPU Pod配置
apiVersion: v1
kind: Pod
metadata:
name: gpu-training-pod
labels:
app: model-training
spec:
containers:
- name: training-container
image: your-registry/gpu-training:latest
resources:
limits:
nvidia.com/gpu: 2 # 申请2个GPU
memory: "16Gi"
cpu: "8"
env:
- name: NVIDIA_VISIBLE_DEVICES
value: "all"
- name: CUDA_DEVICE_ORDER
value: "PCI_BUS_ID"
volumeMounts:
- name: cuda-libs
mountPath: /usr/local/cuda
volumes:
- name: cuda-libs
hostPath:
path: /usr/local/cuda
nodeSelector:
hardware-type: gpu
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
🔧 运维维护指南
1. 版本兼容性管理
版本兼容性矩阵
| 框架版本 | CUDA版本 | cuDNN版本 | 驱动版本 |
|---|---|---|---|
| PyTorch 2.0+ | 11.7/11.8 | 8.5+ | 515.65.01+ |
| TensorFlow 2.12+ | 11.8 | 8.6+ | 520.61.05+ |
| JAX 0.4+ | 11.8 | 8.6+ | 520.61.05+ |
兼容性检查脚本
#!/bin/bash
# check-cuda-compatibility.sh
echo "=== CUDA环境检查 ==="
nvcc --version
nvidia-smi
echo "=== cuDNN版本检查 ==="
find /usr -name "cudnn_version.h" 2>/dev/null | xargs cat | grep CUDNN_MAJOR
echo "=== 驱动兼容性检查 ==="
driver_version=$(nvidia-smi --query-gpu=driver_version --format=csv,noheader,nounits)
cuda_version=$(nvcc --version | grep "release" | awk '{print $6}')
echo "驱动版本: $driver_version"
echo "CUDA版本: $cuda_version"
2. 监控和告警
GPU监控配置
# Prometheus GPU监控配置
apiVersion: v1
kind: ConfigMap
metadata:
name: gpu-monitoring-config
data:
prometheus.yml: |
global:
scrape_interval: 30s
scrape_configs:
- job_name: 'gpu-metrics'
static_configs:
- targets: ['nvidia-gpu-exporter:9100']
- job_name: 'node-exporter'
static_configs:
- targets: ['node-exporter:9100']
GPU资源监控命令
# 实时监控GPU使用情况
watch -n 1 nvidia-smi
# 在K8s中监控
kubectl top node -l hardware-type=gpu
kubectl describe node <gpu-node>
# 使用DCGM exporter
docker run -d --gpus all --rm -p 9400:9400 nvcr.io/nvidia/k8s/dcgm-exporter:3.1.6-3.1.4-ubuntu20.04
3. 日常维护操作
健康检查
#!/bin/bash
# gpu-health-check.sh
# 检查GPU状态
echo "检查GPU状态..."
nvidia-smi --query-gpu=index,name,temperature.gpu,utilization.gpu,memory.used,memory.total --format=csv
# 检查CUDA安装
echo "检查CUDA安装..."
nvcc --version && echo "CUDA安装正常" || echo "CUDA安装异常"
# 检查cuDNN
echo "检查cuDNN..."
if [ -f /usr/local/cuda/include/cudnn_version.h ]; then
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
else
echo "cuDNN未找到"
fi
# 检查设备插件
echo "检查K8s设备插件..."
kubectl get pods -n kube-system | grep nvidia-device-plugin
驱动更新流程
# 1. 排空节点
kubectl drain <gpu-node> --ignore-daemonsets --delete-emptydir-data
# 2. 停止Docker/Kubernetes服务
sudo systemctl stop kubelet
sudo systemctl stop docker
# 3. 安装新驱动
sudo apt-get update
sudo apt-get install nvidia-driver-535
# 4. 重启节点
sudo reboot
# 5. 验证驱动
nvidia-smi
# 6. 恢复节点
kubectl uncordon <gpu-node>
4. 故障排查
常见问题诊断
# GPU无法识别
lspci | grep -i nvidia
dmesg | grep -i nvidia
# CUDA错误诊断
nvidia-debugdump -l
nvidia-bug-report.sh
# 检查设备插件日志
kubectl logs -n kube-system -l name=nvidia-device-plugin
# 验证Pod GPU访问
kubectl exec -it <pod-name> -- nvidia-smi
问题解决清单
# 常见问题及解决方案
#1 问题: "CUDA error: no kernel image is available for execution"
原因: GPU架构与CUDA计算能力不匹配
解决: 检查GPU架构,使用合适的CUDA版本
#2 问题: "Failed to initialize NVML: Driver/library version mismatch"
原因: 驱动版本不匹配
解决: 重启系统或重新安装驱动
#3 问题: "cuDNN status != CUDNN_STATUS_SUCCESS"
原因: cuDNN版本不兼容或安装错误
解决: 重新安装匹配版本的cuDNN
5. 性能优化
GPU资源优化配置
apiVersion: v1
kind: Pod
metadata:
name: optimized-gpu-pod
spec:
containers:
- name: training-container
image: optimized-training:latest
resources:
limits:
nvidia.com/gpu: 1
memory: "8Gi"
cpu: "4"
env:
# 内存优化
- name: PYTORCH_CUDA_ALLOC_CONF
value: "max_split_size_mb:128"
# 性能优化
- name: CUDA_LAUNCH_BLOCKING
value: "0"
- name: TF_GPU_THREAD_MODE
value: "gpu_private"
📊 运维检查清单
每日检查
- GPU节点健康状态
- 驱动和CUDA版本一致性
- 设备插件运行状态
- GPU资源利用率
- 温度监控
每周维护
- 日志文件清理
- 存储空间检查
- 安全补丁评估
- 备份关键配置
版本升级
- 测试环境验证
- 兼容性检查
- 回滚计划准备
- 文档更新
💡 最佳实践建议
- 版本一致性:确保所有GPU节点的CUDA、驱动版本一致
- 渐进式升级:先在一个节点测试,再批量升级
- 监控告警:设置GPU温度、内存使用率告警
- 资源隔离:为不同团队划分GPU资源池
- 文档维护:详细记录每个节点的软件版本和配置
本文来源于我的微信公众号Linux运维小白,我会持续更新文章,欢迎大家关注,互相交流学习。


鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)