
RNN模型扩展
摘要:本文介绍了堆叠RNN和双向RNN的实现方法,展示了PyTorch代码示例。堆叠RNN通过多层LSTM提取特征,最后时间步的隐藏状态作为特征向量。双向RNN通过正向和反向处理拼接输出特征,效果优于单向。文章建议:1)优先使用LSTM而非简单RNN;2)尽可能使用双向结构;3)大数据时堆叠多层;4)小数据时可预训练嵌入层。代码演示了两种RNN的参数设置和前向传播过程,包括隐藏状态初始化和输出处理
堆叠RNN
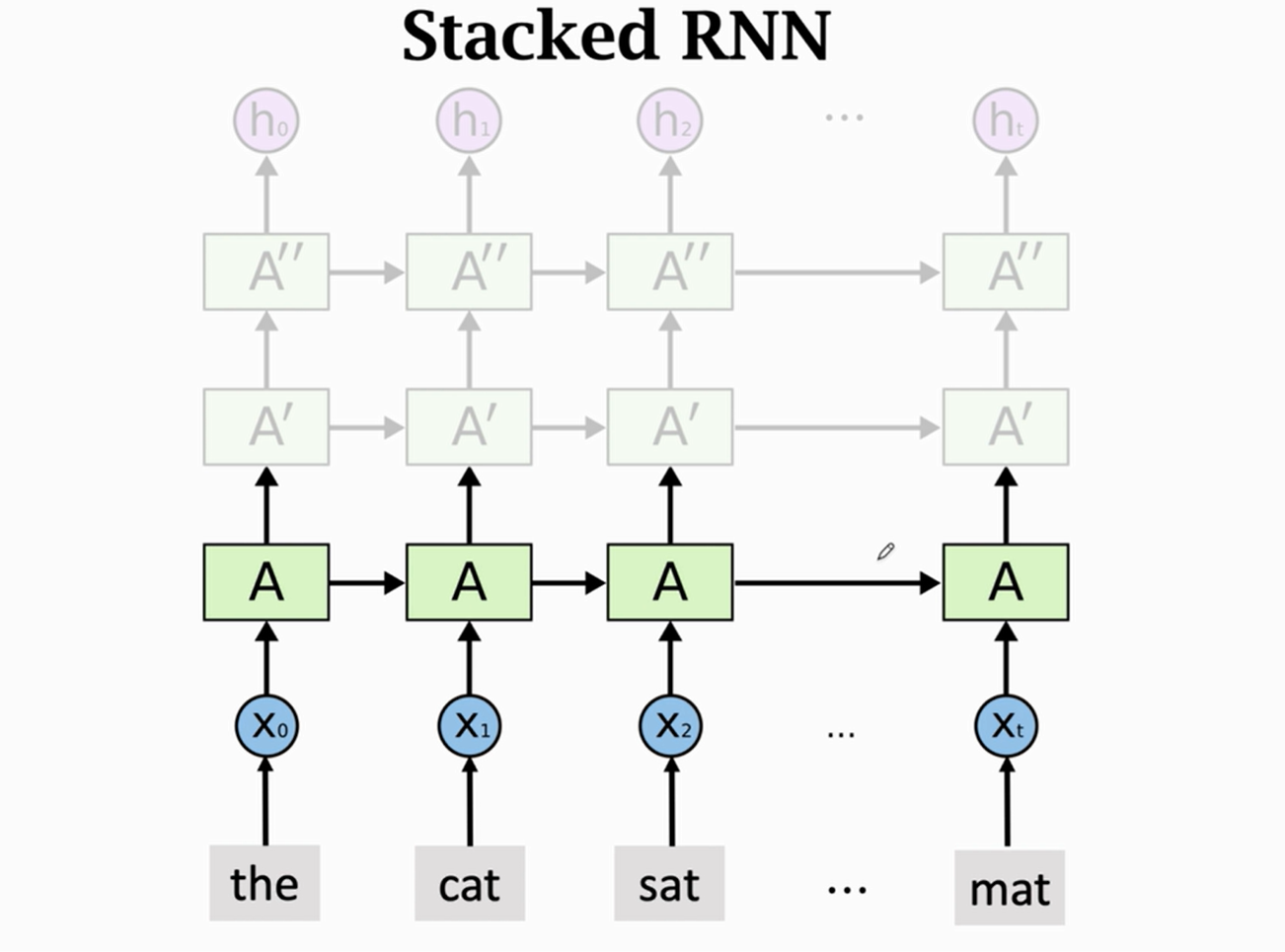 最终的ht可看成从这些词向量中提取的特征向量
最终的ht可看成从这些词向量中提取的特征向量
示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义堆叠LSTM模型
class StackedLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(StackedLSTM, self).__init__()
self.hidden_size = hidden_size # 每个LSTM层的隐藏单元数
self.num_layers = num_layers # 堆叠的层数
# 定义堆叠LSTM层:num_layers指定层数,batch_first=True表示输入形状为(batch, seq_len, input_size)
self.lstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True # 输入/输出的第一维为batch_size
)
# 输出层:将最后一层的隐藏状态映射到目标维度
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# x的形状:(batch_size, seq_len, input_size)
# 初始化隐藏状态和细胞状态(如果不初始化,PyTorch会自动初始化为全0)
# h0形状:(num_layers, batch_size, hidden_size) 隐藏状态
# c0形状:(num_layers, batch_size, hidden_size) 细胞状态(LSTM特有)
batch_size = x.size(0)
h0 = torch.zeros(self.num_layers, batch_size, self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, batch_size, self.hidden_size).to(x.device)
# LSTM前向传播
# out形状:(batch_size, seq_len, hidden_size) 所有时间步的输出(最后一层)
# hn形状:(num_layers, batch_size, hidden_size) 最后时间步的隐藏状态(所有层)
# cn形状:(num_layers, batch_size, hidden_size) 最后时间步的细胞状态(所有层)
out, (hn, cn) = self.lstm(x, (h0, c0))
# 取最后一个时间步的输出(用于序列分类等任务),再通过全连接层
# 如果是序列预测任务,可使用所有时间步的out
out = self.fc(out[:, -1, :]) # 形状:(batch_size, output_size)
return out
# 测试模型
if __name__ == "__main__":
# 超参数
input_size = 10 # 输入特征维度
hidden_size = 32 # 每个LSTM层的隐藏单元数
num_layers = 2 # 堆叠2层LSTM
output_size = 2 # 输出维度(例如二分类)
batch_size = 8 # 批次大小
seq_len = 5 # 序列长度(每个样本包含5个时间步)
# 随机生成输入数据:(batch_size, seq_len, input_size)
x = torch.randn(batch_size, seq_len, input_size)
# 初始化模型
model = StackedLSTM(input_size, hidden_size, num_layers, output_size)
# 前向传播
output = model(x)
print(f"输入形状:{x.shape}")
print(f"输出形状:{output.shape}") # 应为 (8, 2)双向RNN
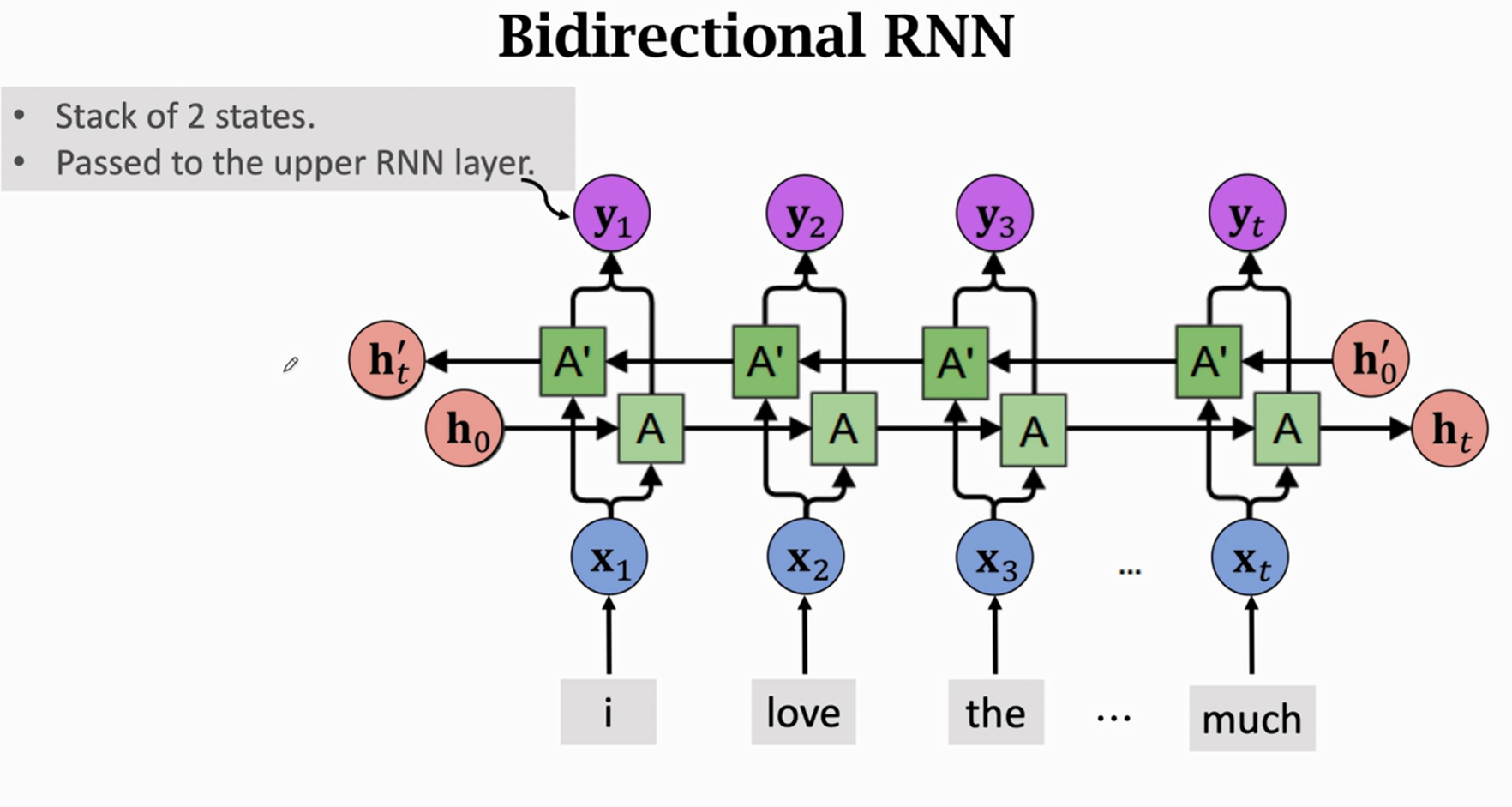
X1和h0拼接,Xt和h0'拼接。
yt是输出向量的拼合在一起的特征向量
ht,ht'也可以看成是最后的输出的特征向量
双向效果比单向的好
示例代码:
import torch
import torch.nn as nn
class BidirectionalLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(BidirectionalLSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.bidirectional = True # 启用双向
# 双向LSTM:bidirectional=True,输出维度会变为hidden_size*2
self.lstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
bidirectional=self.bidirectional, # 核心参数:启用双向
batch_first=True # 输入形状为(batch, seq_len, input_size)
)
# 输出层:输入维度为hidden_size*2(双向拼接)
self.fc = nn.Linear(hidden_size * 2, output_size)
def forward(self, x):
# x形状:(batch_size, seq_len, input_size)
batch_size = x.size(0)
# 初始化隐藏状态和细胞状态:双向模式下,层数需×2(正向+反向各num_layers层)
# h0/c0形状:(num_layers * 2, batch_size, hidden_size)
h0 = torch.zeros(self.num_layers * 2, batch_size, self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers * 2, batch_size, self.hidden_size).to(x.device)
# LSTM前向传播
# out形状:(batch_size, seq_len, hidden_size * 2) 双向输出拼接
# hn/cn形状:(num_layers * 2, batch_size, hidden_size) 最后时间步的隐藏状态(正向+反向)
out, (hn, cn) = self.lstm(x, (h0, c0))
# 序列分类任务:取最后一个时间步的双向输出(也可根据任务取所有时间步)
out = self.fc(out[:, -1, :]) # 输入维度为hidden_size*2
return out
# 测试模型
if __name__ == "__main__":
# 超参数
input_size = 10 # 输入特征维度
hidden_size = 32 # 单向隐藏单元数(双向总输出为64)
num_layers = 1 # 单向层数(双向总层数为2)
output_size = 2 # 输出维度(二分类)
batch_size = 8 # 批次大小
seq_len = 5 # 序列长度
# 随机输入:(batch_size, seq_len, input_size)
x = torch.randn(batch_size, seq_len, input_size)
# 初始化模型
model = BidirectionalLSTM(input_size, hidden_size, num_layers, output_size)
# 前向传播
output = model(x)
print(f"输入形状:{x.shape}") # (8, 5, 10)
print(f"LSTM输出形状(未过全连接):{model.lstm(x)[0].shape}") # (8, 5, 64) 32*2
print(f"最终输出形状:{output. Shape}") # (8, 2)预训练的目的
有可能你的模型需要的参数非常多,但是你的数据集非常小,这时候需要找一个相近的大数据集来进行预训练。(否则小数据集会导致过拟合)
预训练的步骤:
Step 1: Train a model on large dataset.
:Perhaps different problem.
:Perhaps different model.
Step 2: Keep only the embedding layer.
Step 3: Train new LSTM and output layers.
总结:
SimpleRNN and LSTM are two kinds of RNNS; always use LSTM instead of SimpleRNN.
Use Bi-RNN instead of RNN whenever possible.
Stacked RNN may be better than a single RNN layer (if n is big).
Pretrain the embedding layer (if n is small).
1.SimpleRNN和LSTM是两种循环神经网络(RNN);应始终使用LSTM而非SimpleRNN。
2.只要有可能,就使用双向循环神经网络(Bi-RNN)而非单向循环神经网络(RNN)。
3.堆叠循环神经网络可能比单个循环神经网络层更好(如果n较大)。
4.对嵌入层进行预训练(如果n较小)。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)