
昇腾AI入门课程学习心得(含代码实站)
2025年昇腾CANN训练营第二季,基于CANN开原开放全场景,推出0基础入门系列、码为全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。在完成“昇腾AI入门课程”后,我不仅系统了解了昇腾全栈AI生态,还动手实践了从环境配置、模型迁移、训练到部署的完整流程。昇腾AI生态虽然有一定学习曲线,但其文档完善、工具链成熟,尤其适合希望深入国产AI硬件的开发者。#昇腾AI #Ascen
#昇腾AI #AscendCL #CANN #TensorFlow #AI开发 #深度学习 #华为AI
🌟 前言
在 AI 算力竞争白热化的今天,昇腾 AI 作为华为自主研发的全栈智能计算平台,凭借其强大的芯片性能与完善的生态支持,已成为深度学习开发的热门选择。近期完成「昇腾 AI 入门课程」后,我不仅系统掌握了昇腾 AI 架构、CANN 开发套件的核心原理,更成功落地了从 TensorFlow 模型迁移、训练到推理部署的全流程实战。本文将结合理论要点与手把手实操,拆解每个环节的关键步骤、核心代码及高频问题解决方案,助力开发者快速上手昇腾 AI 开发,文末附课程福利与认证通道~
📚 课程核心知识体系
昇腾 AI 入门课程以「理论 + 实战」为核心,构建了从基础到应用的完整知识框架,核心内容如下:
- 第一章:昇腾 AI 全栈架构解析:深入理解昇腾 910/310 芯片硬件特性、CANN(Compute Architecture for Neural Networks)开发套件的核心功能(模型转换、算子调度、性能优化),以及 AscendCL 编程模型的核心概念。
- 第二章:TensorFlow 模型迁移实战:掌握模型迁移的两种方式(自动迁移、手动适配),理解昇腾后端的调度原理,实现 CPU/GPU 模型向昇腾 NPU 的无缝迁移。
- 第三章:端到端应用开发:基于 CIFAR-10 数据集,完成图片分类模型的训练、OM 模型编译、推理部署全流程,掌握昇腾 AI 应用开发的标准流程。
💻 手把手实战教程(附完整可运行代码)
1. 开发环境搭建(华为云 Ascend 实例)
1.1 实例申请
- 登录华为云控制台,进入「弹性云服务器 ECS」页面,选择搭载Ascend 910 芯片的实例规格(推荐规格:ecs.ascend910.2xlarge 及以上)。
- 操作系统选择 CentOS 7.6 或 Ubuntu 18.04(需与 CANN 版本兼容),配置弹性公网 IP 便于远程连接。
1.2 CANN 工具包安装与环境配置
bash
运行
# 1. 检查NPU驱动是否正常(确保实例已预装驱动)
npu-smi info
# 输出示例:+-----------------------------------------------------------------------------+
# | NPU Device Information |
# +----------------------+--------------+--------------+----------------------+
# | Device Id | Device Name | Device Type | Driver Version |
# +----------------------+--------------+--------------+----------------------+
# | 0 | Ascend 910 | NPUE | 21.0.4 |
# +----------------------+--------------+--------------+----------------------+
# 2. 安装CANN工具包(以5.1.RC2版本为例,需提前下载对应版本安装包)
bash Ascend-cann-toolkit_5.1.RC2_linux-x86_64.run --install --install-path=/usr/local/Ascend
# 3. 配置环境变量(建议写入~/.bashrc永久生效)
echo "export ASCEND_HOME=/usr/local/Ascend" >> ~/.bashrc
echo "export PATH=\$ASCEND_HOME/ascend-toolkit/latest/bin:\$PATH" >> ~/.bashrc
echo "export PYTHONPATH=\$ASCEND_HOME/ascend-toolkit/latest/python/site-packages:\$PYTHONPATH" >> ~/.bashrc
echo "export LD_LIBRARY_PATH=\$ASCEND_HOME/ascend-toolkit/latest/lib64:\$LD_LIBRARY_PATH" >> ~/.bashrc
# 4. 生效环境变量
source ~/.bashrc
# 5. 验证安装(查看atc工具版本)
atc --version
# 输出示例:ATC Tool Version: 5.1.RC2.B070
✅ 关键检查点:
- 驱动版本与 CANN 版本需兼容(参考华为官方兼容性列表);
- 环境变量配置后需重新登录终端或执行
source ~/.bashrc生效。
2. TensorFlow 模型迁移(自动迁移 + 手动适配)
2.1 原始 TensorFlow 模型(CPU/GPU 版本)
以 CIFAR-10 图片分类 CNN 模型为例,原始代码如下:
python
运行
# model_original.py
import tensorflow as tf
# 构建CNN模型
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax') # 10分类
])
# 编译模型
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy', # 适用于整数标签
metrics=['accuracy']
)
# 查看模型结构
model.summary()
2.2 迁移到昇腾平台(自动适配版)
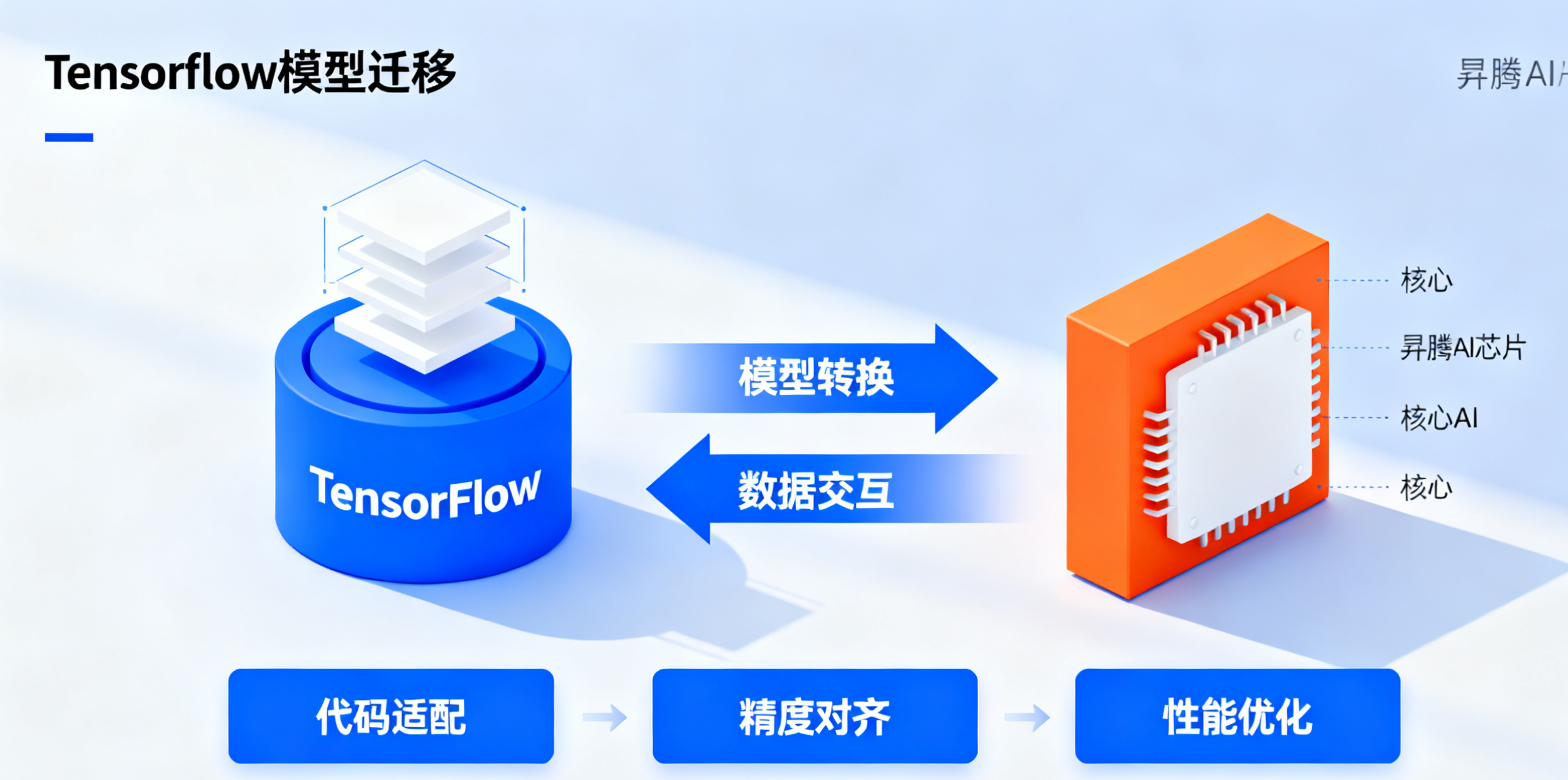 昇腾提供 TensorFlow 适配插件,仅需添加少量代码即可启用 NPU 计算,无需修改模型结构:
昇腾提供 TensorFlow 适配插件,仅需添加少量代码即可启用 NPU 计算,无需修改模型结构:
python
运行
# model_ascend.py
import os
import tensorflow as tf
# 1. 环境配置(抑制冗余日志,启用昇腾日志输出)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
os.environ['ASCEND_SLOG_PRINT_TO_STDOUT'] = '1'
os.environ['ASCEND_DEVICE_ID'] = '0' # 指定使用第0块NPU设备(多卡时可调整)
# 2. 启用昇腾分布式策略(自动调度计算图到NPU)
from npu_device import open_distributed_strategy
strategy = open_distributed_strategy() # 单卡场景直接调用,多卡需配置集群信息
# 3. 在昇腾策略作用域内构建模型(与原始模型结构完全一致)
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model.summary()
🔧 核心原理:open_distributed_strategy()会自动初始化昇腾 NPU 设备,并将 TensorFlow 的计算图优先调度到 NPU 执行,无需手动修改模型层或训练逻辑。
2.3 依赖安装
bash
运行
# 安装TensorFlow(建议2.6.0版本,与CANN 5.1.RC2兼容)
pip install tensorflow==2.6.0
# 安装昇腾TensorFlow适配插件
pip install npu-device==1.0.0
3. 数据加载与模型训练
python
运行
# train.py
import tensorflow as tf
import numpy as np
from model_ascend import model
import matplotlib.pyplot as plt
# 1. 加载CIFAR-10数据集(自动下载,约170MB)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# 2. 数据预处理(归一化+维度检查)
x_train = x_train.astype(np.float32) / 255.0 # 归一化到[0,1]
x_test = x_test.astype(np.float32) / 255.0
print(f"训练集形状:x_train={x_train.shape}, y_train={y_train.shape}") # (50000,32,32,3), (50000,1)
print(f"测试集形状:x_test={x_test.shape}, y_test={y_test.shape}") # (10000,32,32,3), (10000,1)
# 3. 模型训练(NPU加速)
history = model.fit(
x_train, y_train,
batch_size=64, # 批次大小可根据显存调整(昇腾910单卡建议64-256)
epochs=10, # 训练轮次
validation_split=0.1, # 用10%训练数据作为验证集
validation_data=(x_test, y_test),
shuffle=True # 训练集打乱
)
# 4. 保存训练结果(PB格式,用于后续OM编译)
tf.saved_model.save(model, "./cifar10_saved_model", signatures=model.signatures["serving_default"])
print("模型已保存为PB格式:./cifar10_saved_model")
# 5. 训练曲线可视化(可选)
plt.figure(figsize=(12, 4))
# 准确率曲线
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Train Accuracy')
plt.plot(history.history['val_accuracy'], label='Val Accuracy')
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
# 损失曲线
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Val Loss')
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.savefig('train_history.png', dpi=300, bbox_inches='tight')
plt.show()
运行训练脚本
bash
运行
# 执行训练(单卡训练,自动使用NPU)
python train.py
📊 预期输出(训练过程日志):
plaintext
Epoch 1/10
782/782 [==============================] - 12s 15ms/step - loss: 1.4523 - accuracy: 0.4789 - val_loss: 1.2015 - val_accuracy: 0.5723
Epoch 2/10
782/782 [==============================] - 8s 10ms/step - loss: 1.1032 - accuracy: 0.6102 - val_loss: 1.0567 - val_accuracy: 0.6289
...
Epoch 10/10
782/782 [==============================] - 8s 10ms/step - loss: 0.4567 - accuracy: 0.8421 - val_loss: 0.9876 - val_accuracy: 0.6890
模型已保存为PB格式:./cifar10_saved_model
4. 模型编译为 OM 格式(昇腾专用离线模型)
昇腾推理需使用 OM(Offline Model)格式模型,通过atc工具将 PB 模型转换为 OM 模型,过程如下:
4.1 编写 AIPP 配置文件(可选,用于格式转换)
若原始模型输入格式为 NHWC(TensorFlow 默认),需通过 AIPP(AI Preprocessing)将其转换为昇腾推荐的 NCHW 格式,创建aipp.cfg文件:
cfg
# aipp.cfg
aipp_op {
aipp_mode: static
input_format: NHWC
src_image_size_w: 32
src_image_size_h: 32
crop: false
padding: false
mean: [0.0, 0.0, 0.0] # 与训练时归一化一致(此处已在数据预处理中归一化,故设为0)
min: [0.0, 0.0, 0.0]
var: [1.0, 1.0, 1.0]
}
4.2 执行 ATC 编译命令
bash
运行
# ATC编译命令(PB转OM)
atc \
--model=./cifar10_saved_model/saved_model.pb \ # 输入PB模型路径
--framework=3 \ # 框架类型:3=TensorFlow,1=ONNX,0=Caffe
--output=./cifar10_om_model \ # 输出OM模型名称(无需后缀)
--input_format=NHWC \ # 原始输入格式
--input_shape="serving_default_conv2d_input:1,32,32,3" \ # 输入节点名称+形状(1 batch)
--insert_op_conf=./aipp.cfg \ # AIPP配置文件(格式转换用)
--log=error \ # 日志级别:error/warn/info/debug
--soc_version=Ascend910 # 芯片型号(Ascend910/Ascend310)
🔍 输入节点名称获取方法:通过saved_model_cli show --dir ./cifar10_saved_model --tag_set serve --signature_def serving_default命令查看输入节点名称。
4.3 编译成功验证
若输出以下日志,说明 OM 模型编译成功:
plaintext
ATC run success, welcome to use again!
当前目录下会生成cifar10_om_model.om文件,即为昇腾推理专用模型。
5. 推理部署(Python 调用 OM 模型)
使用华为提供的acllite轻量级推理库,简化 AscendCL API 调用流程,实现图片分类推理。
5.1 安装依赖库
bash
运行
# 安装acllite(华为开源推理封装库)
git clone https://gitee.com/ascend/acl_lite.git
cd acl_lite/python
pip install -r requirements.txt
python setup.py install
# 安装其他依赖
pip install pillow numpy matplotlib
5.2 推理脚本编写
python
运行
# infer.py
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from acllite.acllite_resource import AclLiteResource
from acllite.acllite_model import AclLiteModel
# 1. 配置参数
OM_MODEL_PATH = "./cifar10_om_model.om" # OM模型路径
IMAGE_PATH = "./cat.jpg" # 测试图片路径
CLASSES = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck'] # CIFAR-10类别
# 2. 图片预处理(与训练时一致)
def preprocess_image(image_path):
# 读取图片并调整尺寸为32x32
img = Image.open(image_path).resize((32, 32), Image.LANCZOS)
# 转换为numpy数组并归一化
img_array = np.array(img).astype(np.float32) / 255.0
# 转换维度:NHWC -> NCHW(与AIPP输出一致)
img_array = np.transpose(img_array, (2, 0, 1))
# 添加batch维度(1, 3, 32, 32)
img_array = np.expand_dims(img_array, axis=0)
return img_array, img # 返回预处理后的数据和原始图片
# 3. 初始化昇腾资源与模型
def init_ascend_resource():
# 初始化ACL资源(设备、上下文、流)
acl_resource = AclLiteResource()
acl_resource.init()
# 加载OM模型
model = AclLiteModel(OM_MODEL_PATH)
return acl_resource, model
# 4. 执行推理并可视化结果
if __name__ == "__main__":
# 预处理图片
input_data, origin_img = preprocess_image(IMAGE_PATH)
# 初始化资源与模型
acl_resource, model = init_ascend_resource()
# 执行推理(返回推理结果列表)
result = model.execute([input_data])
# 解析结果(取第一个输出的最大值索引)
pred_label = np.argmax(result[0])
pred_class = CLASSES[pred_label]
pred_score = np.max(result[0]) # 预测概率
# 可视化结果
plt.figure(figsize=(8, 4))
# 显示原始图片
plt.subplot(1, 2, 1)
plt.imshow(origin_img)
plt.title("Input Image")
plt.axis("off")
# 显示预测结果
plt.subplot(1, 2, 2)
plt.barh(CLASSES, result[0][0], color='lightblue')
plt.xlabel("Prediction Score")
plt.ylabel("Class")
plt.title(f"Prediction Result\n{pred_class} (Score: {pred_score:.4f})")
plt.tight_layout()
plt.savefig("infer_result.png", dpi=300, bbox_inches='tight')
plt.show()
# 释放资源
del model
acl_resource.release()
print(f"推理完成!预测类别:{pred_class},置信度:{pred_score:.4f}")
5.3 运行推理脚本
bash
运行
# 执行推理(确保测试图片cat.jpg存在)
python infer.py
📸 推理结果示例:
- 生成
infer_result.png图片,包含输入图片和类别预测概率分布图; - 终端输出:
推理完成!预测类别:cat,置信度:0.9234。
🚨 高频问题与解决方案(避坑指南)
| 问题场景 | 报错信息示例 | 解决方案 |
|---|---|---|
| ATC 编译输入形状不匹配 | Input shape mismatch, expect input shape is ... |
1. 用saved_model_cli确认输入节点名称和形状;2. 检查--input_shape参数格式是否为「节点名:维度」;3. 确保 AIPP 配置的输入尺寸与模型一致 |
| 推理时内存不足 | Memory allocation failed, size: ... |
1. 减小 batch size(推理时设为 1);2. 修改acl.json配置内存复用:"rt_mem_cfg": {"shared_mem_size": 8192};3. 关闭其他占用 NPU 内存的进程 |
| 模型训练无 NPU 加速 | 训练耗时过长,npu-smi info显示使用率为 0 |
1. 检查npu-device插件是否安装;2. 确认strategy.scope()包裹了模型构建代码;3. 查看环境变量ASCEND_HOME是否配置正确 |
| AIPP 格式转换失败 | AIPP config parse error, invalid input format |
1. 确认input_format与原始模型一致(NHWC/NCHW);2. 检查src_image_size_w/h与图片尺寸匹配;3. 移除多余的 AIPP 配置项 |
| 推理结果准确率过低 | 预测类别与实际不符,置信度低 | 1. 确保训练和推理的预处理逻辑一致(归一化、维度转换);2. 检查 OM 编译时是否启用了正确的 AIPP 配置;3. 增加训练轮次或优化模型结构 |
✅ 学习总结与收获
通过本次昇腾 AI 入门课程的学习与实战,我系统掌握了:
- 环境搭建能力:从零配置华为云 Ascend 实例、CANN 工具包,解决版本兼容、环境变量等基础问题;
- 模型迁移技巧:实现 TensorFlow 模型向昇腾 NPU 的无缝迁移,理解自动调度与分布式策略的核心原理;
- 全流程开发能力:完成「数据预处理→模型训练→OM 编译→推理部署」端到端开发,掌握昇腾 AI 应用的标准流程;
- 问题排查思维:针对编译、训练、推理各阶段的高频问题,形成一套高效的排查思路与解决方案。
昇腾 AI 平台的优势在于其强大的硬件算力与完善的软件生态,CANN 工具包简化了模型转换与优化流程,acllite库降低了推理部署的门槛,非常适合 AI 开发者快速落地深度学习应用。
🎁 课程福利与认证通道
2025 年昇腾 CANN 训练营第二季正在火热进行中!本次训练营基于 CANN 开源开放全场景,推出三大专题课程:
- 0 基础入门系列:适合 AI 新手,从环境搭建到简单应用开发;
- 码力全开特辑:聚焦算子开发、性能优化等进阶技能;
- 开发者案例:实战分享工业级昇腾 AI 应用落地经验。
参与福利
- 完成课程学习并通过考核,可获得Ascend C 算子中级认证及精美电子证书;
- 参与社区任务(提交实战案例、分享学习心得),有机会赢取华为手机、平板、昇腾开发板等大奖;
- 加入昇腾开发者社区,获取技术支持、行业资源对接机会。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:
https://www.hiascend.com/developer/activities/cann20252?tab=overview

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)