
KeepAlived高可用
文章摘要:本文介绍了高可用(HA)集群的核心概念和实现方式。主要内容包括:1) 三大集群类型(LB负载均衡、HA高可用、HPC高性能计算);2) 系统可用性指标SLA的计算方法(A=MTBF/(MTBF+MTTR))及其等级划分;3) 通过冗余机制实现高可用的解决方案;4) VRRP协议原理及其在网络层的实现;5) Keepalived软件架构,详细解析了其VRRP协议栈、健康检查、IPVS负载均
HA高可用集群
集群类型
LB:Load Balance 负载均衡
- LVS/HAProxy/nginx(http/upstream, stream/upstream)
HA:High Availability 高可用集群
-
数据库、Zookeeper、Redis
-
SPoF: Single Point of Failure,解决单点故障
HPC:High Performance Computing 高性能集群
系统可用性
SLA(服务等级协议)的核心是服务可用性指标,通过公式 A = MTBF / (MTBF + MTTR) 计算(A 为可用性,MTBF 为平均无故障时间,MTTR 为平均修复时间),不同百分比对应明确的每月 / 每年允许停机时间,用于界定服务品质标准
- MTBF:平均无故障时间,指服务连续正常运行的平均时长,越长说明服务越稳定。
- MTTR:平均修复时间,指服务故障后从发现到恢复正常的平均时长,越短说明故障处理效率越高。
- 可用性百分比:服务全年 / 全月正常运行的时间占比,百分比越高,允许的停机时间越短,服务等级越高
核心可用性指标换算(按每月 30 天、每年 365 天统计)
| 可用性等级 | 每月允许停机时间 | 每年允许停机时间 | 核心特点 |
|---|---|---|---|
| 99.9% | 43.2 分钟 | 8.76 小时 | 基础可用,适合普通网站 / 非核心服务 |
| 99.95% | 21.6 分钟 | 4.38 小时 | 中等可用,如你示例所示,适合常规业务系统 |
| 99.99% | 4.32 分钟 | 52.56 分钟 | 高可用,适合电商、支付等核心服务 |
| 99.999% | 25.92 秒 | 5.26 分钟 | 超高可用,适合金融、医疗等关键系统 |
| 99.9999% | 2.59 秒 | 31.54 秒 | 顶级可用,仅用于核心交易、政务等极端重要场景 |
指标选择:根据业务重要性确定 SLA 等级,例如普通博客选 99.9%,银行转账系统选 99.999%。
架构支撑:要达成高等级 SLA,需通过技术架构优化 —— 比如 Keepalived+Nginx 高可用(减少 Nginx 层故障)、Web 集群(避免单节点故障)、MySQL 主从复制(降低数据库故障影响),本质都是延长 MTBF、缩短 MTTR。
责任界定:SLA 是服务提供方与客户的契约,若实际停机时间超出对应指标,需按协议承担违约责任(如赔偿、服务延长等)
系统故障
硬件故障:设计缺陷、wear out(损耗)、自然灾害……
软件故障:设计缺陷 bug
实现高可用
提升系统高用性的解决方案:降低MTTR- Mean Time To Repair(平均故障时间)
解决方案:建立冗余机制
-
active/passive 主/备
-
active/active 双主
-
active --> HEARTBEAT --> passive
-
active <–> HEARTBEAT <–> active
VRRP
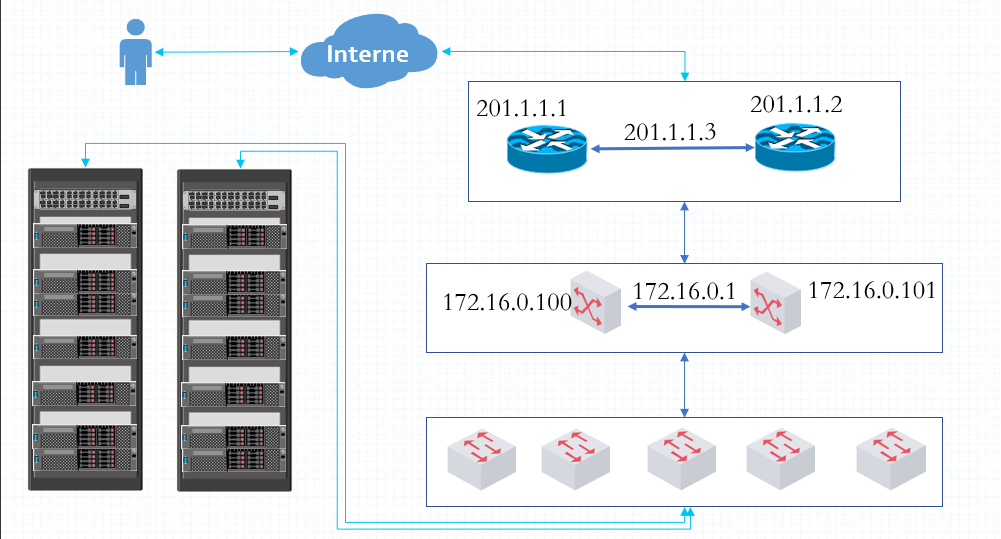
VRRP:Virtual Router Redundancy Protocol,虚拟路由冗余协议,解决静态网关单点风险
- 物理层:路由器、三层交换机
- 软件层:keepalived
VRRP网络层硬件实现
VRRP相关术语
-
虚拟路由器:Virtual Router
-
虚拟路由器标识:VRID(0-255),唯一标识虚拟路由器
-
VIP:Virtual IP
-
VMAC:Virutal MAC (00-00-5e-00-01-VRID)
-
物理路由器:
master:主设备
backup:备用设备
priority:优先级
VRRP相关技术
通告:心跳,优先级等;周期性
工作方式:抢占式,非抢占式
安全认证:
-
无认证
-
简单字符认证:预共享密钥
-
MD5
工作模式:
-
主/备:单虚拟路由器
-
主/主:主/备(虚拟路由器1),备/主(虚拟路由器2)
Keepalived
概述
Keepalived 是一款基于 Linux 系统的 高可用解决方案软件,核心作用是通过冗余机制和故障自动切换,避免单点故障,保障关键服务(如 Nginx 负载均衡、数据库)的持续可用,是集群架构中实现高可用的核心组件
定位
本质:高可用保障 的工具
目标:通过主备 / 双主冗余、心跳检测、自动切换,缩短故障修复时间(MTTR),提升系统可用性(SLA),避免因单个节点故障导致整体服务中断
核心功能
VRRP 协议实现(核心)
- 基于虚拟路由冗余协议(VRRP),通过 “虚拟 IP(VIP)” 作为服务访问入口,主备节点共享同一 VIP。
- 主节点(active)定期发送心跳通告(默认间隔 1 秒,对应
advert_int 1),备节点(passive)监听心跳,故障时自动抢占 VIP 并接管服务
架构
官方文档
https://keepalived.org/doc/
http://keepalived.org/documentation.html
VRRP 协议核心组件
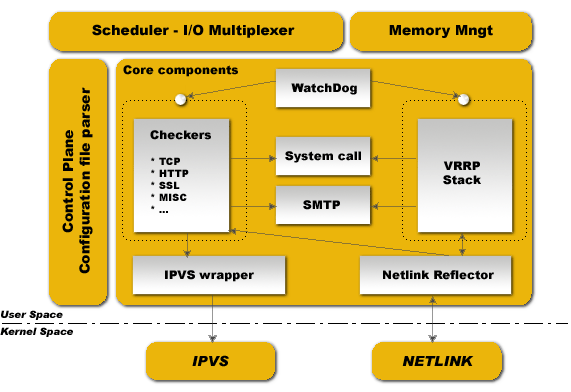
vrrp stack(VRRP 协议栈)
- 核心作用:实现 VRRP 协议的核心逻辑,负责主备节点间的 “心跳通信” 和 VIP 管理。
- 具体工作:主节点按
advert_int间隔(如你配置的 1 秒)生成 VRRP 通告报文(包含优先级、虚拟路由 ID 等),通过组播发送给备节点;备节点通过该组件监听报文,判定主节点状态,触发故障切换。
Netlink Reflector(网络接口交互器)
- 核心作用:作为用户空间与内核网络模块的 “桥梁”,负责 VIP 的绑定 / 解绑、网络接口状态监听。
- 具体工作:当主节点正常运行时,通过 Netlink 调用将 VIP 绑定到主节点的物理网卡;主节点故障后,备节点通过该组件将 VIP 从原主节点解绑,绑定到自身网卡,实现 “VIP 漂移” 对用户透明
健康检查与服务管控组件
checkers(健康检查器)
- 核心作用:监测后端真实服务器(Real Server,如你的 Web 节点 10.0.0.103/10.0.0.104)或本地服务(如 Nginx)的可用性。
- 检查方式:支持 TCP 端口检测(如检测 80 端口是否存活)、HTTP 状态码检测(如访问
/health接口返回 200)、自定义脚本检测(如你可能配置的check_nginx.sh)。
IPVS wrapper(IPVS 规则生成器)
- 核心作用:当 Keepalived 与 LVS(IPVS 内核模块)配合时,自动生成并加载 IPVS 负载均衡规则。
- 具体工作:根据配置文件中
virtual_server块的定义(如后端 RS 地址、负载策略、端口映射),在主节点持有 VIP 时,将规则写入内核 IPVS 模块,实现四层负载均衡。。
system call(系统调用接口)
- 核心作用:在 VRRP 状态转换(如主→备、备→主)时,触发自定义脚本执行,实现业务联动。
- 具体工作:通过调用
vrrp_script配置的脚本(如/etc/keepalived/failover.sh),可在切换时执行启动 / 停止服务、发送告警、更新 DNS 等操作。
自身稳定性与配置组件
WatchDog(看门狗进程)
- 核心作用:监控 Keepalived 主进程的运行状态,防止自身进程崩溃导致高可用失效。
- 具体工作:定期检测 Keepalived 进程的 “心跳”,若进程无响应(如死锁、崩溃),WatchDog 会强制重启进程,确保高可用机制不中断。
- 关键价值:避免 Keepalived 自身成为单点故障(如进程挂掉后无人管,导致主节点故障时无法切换)。
控制组件(配置解析器)
- 核心作用:解析
keepalived.conf配置文件,将用户定义的参数(如 VRRP 实例、健康检查规则、脚本路径)转换为各组件可执行的指令。 - 具体工作:加载配置时进行语法校验(如
nginx -t类似),若配置错误则拒绝启动;运行中动态加载修改后的配置(部分参数支持热重载)。 - 与你的关联:你配置的
state BACKUP、authentication、virtual_ipaddress等,均通过该组件解析后传递给 vrrp stack、Netlink Reflector 等组件生效。
IO 复用器(IO 多路复用引擎)
- 核心作用:优化网络 IO 处理,支持同时监听多个网络事件(如 VRRP 心跳报文、健康检查请求、本地服务状态),提升并发处理能力。
- 具体工作:基于 epoll/kqueue 等内核机制,实现 “单线程 / 多线程” 高效处理多网络连接,避免因 IO 阻塞导致心跳丢失或检查延迟。
- 关键价值:在高并发场景(如 Web 集群每秒 thousands 级请求)中,确保健康检查和心跳通信不延迟。
内存管理组件
- 核心作用:提供统一的内存分配、释放、复用接口,确保各组件高效使用内存,避免内存泄漏或碎片化。
- 具体工作:为 VRRP 报文缓冲区、健康检查结果、配置参数等数据提供内存管理,在高负载下保持稳定性能。
告警与通知组件
-
SMTP(邮件告警组件)
-
核心作用:当发生故障切换、后端节点不可用等事件时,通过 SMTP 协议发送邮件告警,通知运维人员。
-
配置示例(在global_defs中):nginx
global_defs { notification_email { admin@csq.xyz; } # 接收告警的邮箱 notification_email_from keepalived@csq.xyz # 发件人 smtp_server 127.0.0.1 # 邮件服务器地址 smtp_connect_timeout 30 # 连接超时 } -
当 Nginx 主节点故障切换时,自动发送邮件告知 “VIP 已漂移至备节点”,便于及时排查原主节点问题。
-
Keepalived进程树
Keepalived <-- 父进程监控子进程
\_ Keepalived <-- VRRP 子进程
\_ Keepalived <-- Healthchecking 子进程
Keepalived相关文件
-
软件包名:keepalived
-
主程序文件:/usr/sbin/keepalived
-
主配置文件:/etc/keepalived/keepalived.conf
Keepalived安装
yum安装
#红帽系列
yum install -y keepalived
#debian系列
apt install -y keepalived
编译安装
官网下载安装包:https://www.keepalived.org/download.html
#1.安装编译依赖
yum install -y gcc gcc-c++ make automake autoconf openssl-devel lrzsz wget
#2.下载keepalived最新安装包
wget https://keepalived.org/software/keepalived-2.3.4.tar.gz -P /download
#3.解压
tar -zxvf /download/keepalived-2.3.4.tar.gz -C /download
#4.编译
cd /download/keepalived-2.3.4
#检查环境 + 生成 Makefile
./configure --prefix=/usr/local/keepalived-2.3.4
#读取 Makefile,编译源码生成可执行程序
make -j `nproc`
#按 Makefile 规则,将程序 / 配置文件拷贝到指定目录
make install
#5.做软链接简化路径
ln -s /usr/local/keepalived-2.3.4/etc/keepalived/ /etc/keepalived
#6.配置环境变量
ln -s /usr/local/keepalived-2.3.4/sbin/keepalived /sbin/keepalived
#查看keepalived版本
keepalived -v
#7.默认会自动生成unit文件
systemctl cat keepalived
# /usr/lib/systemd/system/keepalived.service
[Unit]
Description=LVS and VRRP High Availability Monitor
After=network-online.target syslog.target
Wants=network-online.target
Documentation=man:keepalived(8)
Documentation=man:keepalived.conf(5)
Documentation=man:genhash(1)
Documentation=https://keepalived.org
[Service]
Type=forking
PIDFile=/run/keepalived.pid
KillMode=process
EnvironmentFile=-/usr/local/keepalived-2.3.4/etc/sysconfig/keepalived
ExecStart=/usr/local/keepalived-2.3.4/sbin/keepalived $KEEPALIVED_OPTIONS
ExecReload=/bin/kill -HUP $MAINPID
[Install]
WantedBy=multi-user.target
#8.修改配置文件
cp /etc/keepalived/{keepalived.conf.sample,keepalived.conf}
#9.清空默认配置文件
>/etc/keepalived/keepalived.conf
#10.启动keepalived
systemctl enable --now keepalived
KeepAlived配置说明
配置文件组成部分
/etc/keepalived/keepalived.conf
| /etc/keepalived/keepalived.conf配置文件结构 | 全局定义部分 |
|---|---|
| global_def | 全局定义部分 |
| vrrp_instance | vrrp协议配置,vip,主备,网卡…经常改动部分 |
| 用于管理与配置lvs的部分 | virtual_server部分用于管理控制lvs的 |
全局配置
[root@lb01 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
#全局定义部分
global_defs {
#每个keepalived的名字,当前网络中唯一
router_id lb01
}
#发邮件的地址
notification_email_from keepalived@localhost
#邮件服务器地址
smtp_server 127.0.0.1
#邮件服务器连接timeout
smtp_connect_timeout 30
##每个keepalived主机唯一标识,建议使用当前主机名,但多节点重名不影响
router_id ka1.example.com
#对所有通告报文都检查,会比较消耗性能,启用此配置后,如果收到的
#通告报文和上一个报文是同一个路由器,则跳过检查,默认值为全检查
vrrp_skip_check_adv_addr
#严格遵守VRRP协议,启用此项后以下状况将无法启动服务:
#1.无VIP地址
#2.配置了单播邻居
#3.在VRRP版本2中有IPv6地址,开启动此项并且没有配置vrrp_iptables时会自动开启iptables防火墙规则,默认导致VIP无法访问,建议不加此项配置
vrrp_strict
#报文发送延迟,0表示不延迟
vrrp_garp_interval 0
#unsolicited NA messages (不请自来)消息发送延迟
vrrp_gna_interval 0
#指定组播IP地址范围:224.0.0.0到239.255.255.255,默认值:224.0.0.18
vrrp_mcast_group4 224.0.0.18
#此项和vrrp_strict同时开启时,则不会添加防火墙规则,如果无配置vrrp_strict项,则无需启用此项配置
vrrp_iptables
配置虚拟路由器
#vrrp实例配置部分 用于配置VIP 设置主备 virtual_ipaddress
#vrrp设置名字
#vrrp实例名字 在同1对主备之间要一致.在当前keepalived软件中唯一
vrrp_instance vip_3 {
#当前节点在虚拟路由器上的初始状态,主/备 MASTER主 BACKUP备 大写
state MASTER
#绑定为当前虚拟路由器使用的指定网卡
interface ens33
#每个虚拟路由器唯一标识,范围0-255,每个虚拟路由器此值必须唯一,否则无法启动
#同属一个虚拟路由器的多个keepalived节点必须相同,同1对主备之间这个ID要一致
virtual_router_id 51
##当前物理节点在此虚拟路由器的优先级 数字越大优先级越高
#范围:1-254,值越大优先级越高,每个keepalived主机节点此值不同
#设置建议:主>备 100 50 相差50
priority 100
#vrrp通告的时间间隔,默认1s
advert_int 1
#认证机制
authentication {
#简单密码认证
auth_type PASS
#预共享密钥,仅前8位有效
#同一个虚拟路由器的多个keepalived节点必须一样
auth_pass 1111
}
#虚拟IP,生产环境可能指定上百个IP地址
virtual_ipaddress {
#指定VIP,不指定网卡,默认为eth0,注意:不指定/prefix,默认为/32
192.168.200.100
#指定VIP的网卡
192.168.200.101/24 dev ens33
#指定VIP的网卡label
192.168.200.102/24 dev ens33 label ens33:0
}
}
track_interface { #配置监控网络接口,一旦出现故障,则转为FAULT状态实现地址转移
eth0
eth1
…
}
启用keepalived日志功能
#1.修改 keepalived 服务的启动参数
vim /usr/local/keepalived-2.3.4/etc/sysconfig/keepalived
#添加如下内容
KEEPALIVED_OPTIONS="-D -S 6"
#-D:表示 keepalive 以 “守护进程(daemon)” 方式运行(后台运行,不占用终端)
#-S 6:指定 keepalive 的日志输出到 syslog 的 local6 设备
#2.rsyslog 把 keepalive 输出到local6的日志
vim /etc/rsyslog.conf
#添加如下内容
local6.* /var/log/keepalived.log
#3.重启让两个服务生效
systemctl restart keepalived rsyslog
#4.查看keepalived日志
tail -f /var/log/keepalived.log
实现独立子配置文件
当生产环境复杂时, /etc/keepalived/keepalived.conf 文件中内容过多,不易管理,可以将不同集
群的配置,比如:不同集群的VIP配置放在独立的子配置文件中
利用include 指令可以实现包含子配置文件
include /path/file
Keepalived企业应用
实现master/slave的keepalived单主架构
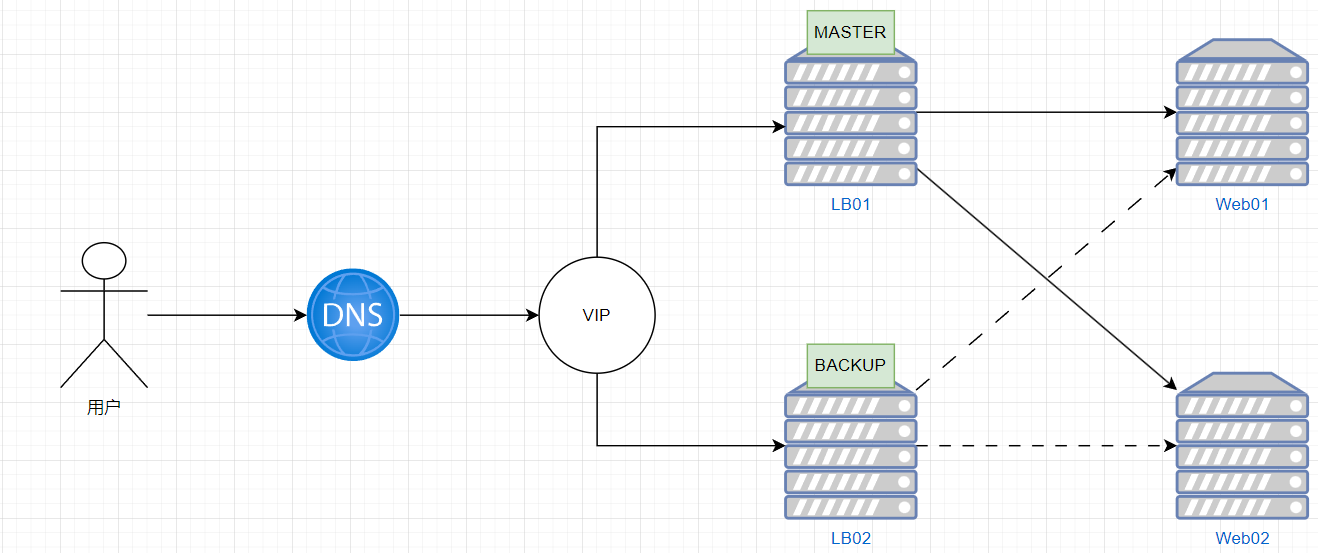
MASTER配置
! Configuration File for keepalived
global_defs {
router_id lb01
}
vrrp_instance vip_3 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.5/24 dev ens33 label ens33:0
}
}
#记得firewalld放行vrrp协议
BACKUP配置
! Configuration File for keepalived
global_defs {
router_id lb02
}
vrrp_instance vip_3 {
state BACKUP
interface ens33
virtual_router_id 51
priority 50
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.5/24 dev ens33 label ens33:0
}
}
#记得firewalld放行vrrp协议
抢占模式和非抢占模式
非抢占模式nopreempt
默认为抢占模式preempt,即当高优先级的主机恢复在线后,会抢占低先级的主机的master角色,造成
网络抖动,建议设置为非抢占模式 nopreempt ,即高优先级主机恢复后,并不会抢占低优先级主机的
master角色
非抢点模块下,如果原主机down机, VIP迁移至的新主机, 后续也发生down时,仍会将VIP迁移回原主机
注意:要关闭VIP抢占,必须将各keepalived服务器state配置为BACKUP
#主机1配置
vrrp_instance VI_1 {
state BACKUP #都为BACKUP
interface ens33
virtual_router_id 66
priority 100 #优先级高
advert_int 1
nopreempt #添加此行,都为nopreempt
#主机2配置
vrrp_instance VI_1 {
state BACKUP #都为BACKUP
interface ens33
virtual_router_id 66
priority 80 #优先级低
advert_int 1
nopreempt #添加此行,都为nopreempt
抢占延迟模式 preempt_delay
抢占延迟模式,即优先级高的主机恢复后,不会立即抢回VIP,而是延迟一段时间(默认300s)再抢回VIP
preempt_delay #指定抢占延迟时间为s,默认延迟300s
注意:需要各keepalived服务器state为BACKUP,并且不要启用 vrrp_strict
#主机1配置
vrrp_instance VI_1 {
state BACKUP #都为BACKUP
interface eth0
virtual_router_id 66
priority 100 #优先级高
advert_int 1
preempt_delay 60 #抢占延迟模式,默认延迟300s
#主机2配置
vrrp_instance VI_1 {
state BACKUP #都为BACKUP
interface eth0
virtual_router_id 66
priority 80 #优先级低
advert_int 1
VIP单播配置
默认keepalived主机之间利用多播相互通告消息,会造成网络拥塞,可以替换成单播,减少网络流量
注意:启用 vrrp_strict 时,不能启用单播
#在所有节点vrrp_instance语句块中设置对方主机的IP,建议设置为专用于对应心跳线网络的地址,而非使用业务网络
#指定发送单播的源IP
unicast_src_ip <IPADDR>
unicast_peer {
#指定接收单播的对方目标主机IP
<IPADDR>
......
}
Keepalived通知脚本配置
当keepalived的状态变化时,可以自动触发脚本的执行,比如:发邮件通知用户
默认以用户keepalived_script身份执行脚本,如果此用户不存在,以root执行脚本
可以用下面指令指定脚本执行用户的身份
global_defs {
......
script_user <USER>
......
}
通知脚本类型
- 当前节点成为主节点时触发的脚本
notify_master <STRING>|<QUOTED-STRING>
- 当前节点转为备节点时触发的脚本
notify_backup <STRING>|<QUOTED-STRING>
- 当前节点转为“失败”状态时触发的脚本
notify_fault <STRING>|<QUOTED-STRING>
- 通用格式的通知触发机制,一个脚本可完成以上三种状态的转换时的通知
notify <STRING>|<QUOTED-STRING
- 当停止VRRP时触发的脚本
notify_stop <STRING>|<QUOTED-STRIN
脚本的调用方法
在 vrrp_instance VI_1 语句块的末尾加下面行
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
案例:实现Keepalived状态切换的通知脚本
创建通知脚本
#执行此脚本前提配置了邮件
#安装s-nail和postfix,记得开启服务
yum install s-nail postfix
systemctl enable --now postfix.service
vim /etc/s-nail.rc
###################SMPT设置####################
set v15-compat #版本所必须,v15版本的配置格式
set smtp-auth=login #验证方式为登陆
##############################################
#设置发件人,昵称<邮箱完整格式>
set from="csq<chenshiren2025@163.com>"
#配置发送邮件服务器,SSL加密,端口465或587
#设置smtp服务器端口465
#用户名为邮箱地址,密码为授权码
#端口465配置 163使用
set mta=smtps://chenshiren2025:授权码@smtp.163.com:465
###############################################
#创建通知脚本(不要把脚本放在链接目录里面,脚本会不执行)
cat > /scripts/notify.sh <<'EOF'
#!/bin/bash
#
contact='2033717617@qq.com'
notify() {
mailsubject="$(hostname) 成为${1},vip漂移"
mailbody="$(date +'%F %T'): vrrp 切换, $(hostname) 切换为 $1"
echo "$mailbody" | s-nail -s "$mailsubject" $contact
}
case $1 in
master)
notify master
;;
backup)
notify backup
;;
fault)
notify fault
;;
*)
echo "Usage: $(basename $0) {master|backup|fault}"
exit 1
;;
esac
EOF
配置文件中调用此脚本
! Configuration File for keepalived
global_defs {
router_id lb01
#以root身份执行脚本
script_user root
}
vrrp_instance vip_3 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.5/24 dev ens33 label ens33:0
}
#MASTER和BACKUP都添加如下内容
notify_master "/scripts/notify.sh master"
notify_backup "/scripts/notify.sh backup"
notify_fault "/scripts/notify.sh fault"
}
模拟master故障
[root@lb01 ~]# pkill keepalived
查看邮箱收到邮件
实现Keepalived双主架构
master/slave的单主架构,同一时间只有一个Keepalived对外提供服务,此主机繁忙,而另一台主机却
很空闲,利用率低下,可以使用master/master的双主架构,解决此问题。
master/master 的双主架构:
即将两个或以上VIP分别运行在不同的keepalived服务器,以实现服务器并行提供web访问的目的,提高服务器资源利用率
#主机1
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb01
}
vrrp_instance VI_1 {
state MASTER #在另一个主机上为BACKUP
interface ens33
virtual_router_id 66 #每个vrrp_instance唯一
priority 100 #在另一个主机上为80
advert_int 1
authentication {
auth_type PASS
auth_pass 12345678
}
virtual_ipaddress {
10.0.0.10/24 dev ens33 label ens33:1 #指定vrrp_instance各自的VIP
}
}
vrrp_instance VI_2 { #添加 VI_2 实例
state BACKUP #在另一个主机上为MASTER
interface ens33
virtual_router_id 88 #每个vrrp_instance唯一
priority 80 #在另一个主机上为100
advert_int 1
authentication {
auth_type PASS
auth_pass 12345678
}
virtual_ipaddress {
10.0.0.20/24 dev ens33 label ens33:1 #指定vrrp_instance各自的VIP
}
}
#主机2
[root@lb02 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb02 #修改此行lb02
}
vrrp_instance VI_1 {
state BACKUP #此修改行为BACKUP
interface ens33
virtual_router_id 66
priority 80 #此修改行为80
advert_int 1
authentication {
auth_type PASS
auth_pass 12345678
}
virtual_ipaddress {
10.0.0.10/24 dev ens33 label ens33:1
}
}
vrrp_instance VI_2 {
state MASTER #修改此行为MASTER
interface ens33
virtual_router_id 88
priority 100 #修改此行为100
advert_int 1
authentication {
auth_type PASS
auth_pass 12345678
}
virtual_ipaddress {
10.0.0.20/24 dev ens33 label ens33:1
}
}
实现IPVS的高可用性
IPVS相关配置
虚拟服务器配置结构
virtual_server IP port {
...
real_server {
...
}
real_server {
...
}
…
}
virtual server (虚拟服务器)的定义格式
virtual_server IP port #定义虚拟主机IP地址及其端口
virtual_server fwmark int #ipvs的防火墙打标,实现基于防火墙的负载均衡集群
virtual_server group string #使用虚拟服务器组
虚拟服务器组
将多个虚拟服务器定义成一个组,统一对外服务,如:http和https定义成一个虚拟服务器组
#参考文档:/usr/share/doc/keepalived/keepalived.conf.virtual_server_group
virtual_server_group <STRING> {
# Virtual IP Address and Port
<IPADDR> <PORT>
<IPADDR> <PORT>
...
# <IPADDR RANGE> has the form
# XXX.YYY.ZZZ.WWW-VVV eg 192.168.200.1-10
# range includes both .1 and .10 address
<IPADDR RANGE> <PORT># VIP range VPORT
<IPADDR RANGE> <PORT>
...
# Firewall Mark (fwmark)
fwmark <INTEGER>
fwmark <INTEGER>
...
}
虚拟服务器配置
virtual_server IP port { #VIP和PORT
delay_loop <INT> #检查后端服务器的时间间隔
lb_algo rr|wrr|lc|wlc|lblc|sh|dh #定义调度方法
lb_kind NAT|DR|TUN #集群的类型,注意要大写
persistence_timeout <INT> #持久连接时长
protocol TCP|UDP|SCTP #指定服务协议,一般为TCP
sorry_server <IPADDR> <PORT> #所有RS故障时,备用服务器地址
real_server <IPADDR> <PORT> { #RS的IP和PORT
weight <INT> #RS权重
notify_up <STRING>|<QUOTED-STRING> #RS上线通知脚本
notify_down <STRING>|<QUOTED-STRING> #RS下线通知脚本
HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK { ... } #定义当前主机健康状
态检测方法
}
}
#注意:括号必须分行写,两个括号写在同一行,如: }} 会出错
应用层监测
应用层检测:HTTP_GET|SSL_GET
HTTP_GET|SSL_GET {
url {
path <URL_PATH> #定义要监控的URL
status_code <INT> #判断上述检测机制为健康状态的响应码,一般为 200
}
connect_timeout <INTEGER> #客户端请求的超时时长, 相当于haproxy的timeout server
nb_get_retry <INT> #重试次数
delay_before_retry <INT> #重试之前的延迟时长
connect_ip <IP ADDRESS> #向当前RS哪个IP地址发起健康状态检测请求
connect_port <PORT> #向当前RS的哪个PORT发起健康状态检测请求
bindto <IP ADDRESS> #向当前RS发出健康状态检测请求时使用的源地址
bind_port <PORT> #向当前RS发出健康状态检测请求时使用的源端口
}
范例
virtual_server 10.0.0.10 80 {
delay_loop 3
lb_algo rr
lb_kind DR
protocol TCP
sorry_server 127.0.0.1 80
real_server 10.0.0.7 80 {
weight 1
HTTP_GET {
url {
path /monitor.html
status_code 200
}
connect_timeout 1
nb_get_retry 3
delay_before_retry 1
}
}
real_server 10.0.0.17 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 1
nb_get_retry 3
delay_before_retry 1
}
}
}
TCP检测
传输层检测:TCP_CHECK
TCP_CHECK {
connect_ip <IP ADDRESS> #向当前RS的哪个IP地址发起健康状态检测请求
connect_port <PORT> #向当前RS的哪个PORT发起健康状态检测请求
bindto <IP ADDRESS> #发出健康状态检测请求时使用的源地址
bind_port <PORT> #发出健康状态检测请求时使用的源端口
connect_timeout <INTEGER> #客户端请求的超时时长, 等于haproxy的timeout server
}
范例
virtual_server 10.0.0.10 80 {
delay_loop 6
lb_algo wrr
lb_kind DR
#persistence_timeout 120 #会话保持时间
protocol TCP
sorry_server 127.0.0.1 80
real_server 10.0.0.7 80 {
weight 1
TCP_CHECK {
connect_timeout 5
nb_get_retry 3
delay_before_retry 3
connect_port 80
}
}
real_server 10.0.0.17 80 {
weight 1
TCP_CHECK {
connect_timeout 5
nb_get_retry 3
delay_before_retry 3
connect_port 80
}
}
}
实现其他应用的高可用性VRRP Script
keepalived利用 VRRP Script 技术,可以调用外部的辅助脚本进行资源监控,并根据监控的结果实现优先动态调整,从而实现其它应用的高可用性功能
#参考配置文件
cat /etc/keepalived/samples/keepalived.conf.vrrp.localcheck
VRRP Script配置
分两步实现:
-
定义脚本
vrrp_script:自定义资源监控脚本,vrrp实例根据脚本返回值,公共定义,可被多个实例调用,定
义在vrrp实例之外的独立配置块,一般放在global_defs设置块之后。
通常此脚本用于监控指定应用的状态。一旦发现应用的状态异常,则触发对MASTER节点的权重减
至低于SLAVE节点,从而实现 VIP 切换到 SLAVE 节点
vrrp_script <SCRIPT_NAME> {
script <STRING>|<QUOTED-STRING> #此脚本返回值为非0时,会触发下面OPTIONS执行
OPTIONS
}
-
调用脚本
track_script:调用vrrp_script定义的脚本去监控资源,定义在VRRP实例之内,调用事先定义的vrrp_script
track_script {
SCRIPT_NAME_1
SCRIPT_NAME_2
}
定义 VRRP script
#定义一个检测脚本,在global_defs 之外配置
vrrp_script <SCRIPT_NAME> {
#shell命令或脚本路径
script <STRING>|<QUOTED-STRING>
#间隔时间,单位为秒,默认1秒
interval <INTEGER>
#超时时间
timeout <INTEGER>
#默认为0,如果设置此值为负数,当上面脚本返回值为非0时,会将此值与本节点权重相加可以降低本节点权重
#即表示fall. 如果是正数,当脚本返回值为0,会将此值与本节点权重相加可以提高本节点权重
#即表示 rise.通常使用负值
weight <INTEGER:-254..254>
#执行脚本连续几次都失败,则转换为失败,建议设为2以上
fall <INTEGER>
#执行脚本连续几次都成功,把服务器从失败标记为成功
rise <INTEGER>
#执行监测脚本的用户或组
user USERNAME [GROUPNAME]
##设置默认标记为失败状态,监测成功之后再转换为成功状态
init_fail
}
调用VRRP script
vrrp_instance VI_1 {
…
track_script {
chk_down
}
}
实现单主模式的Nginx负载均衡的高可用
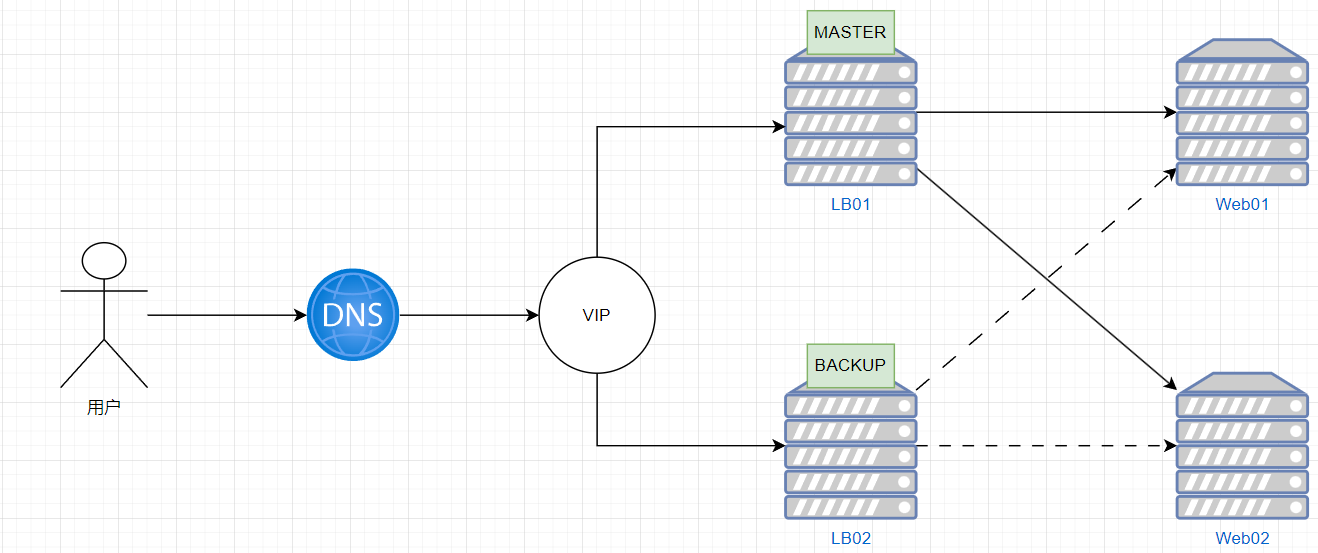
web01/02配置
server {
listen 80;
server_name test.csq.xyz;
access_log /var/log/nginx/access-test.csq.xyz.log main;
error_log /var/log/nginx/error-test.csq.xyz.log notice;
location /{
root /app/code/test;
index index.html;
}
}
lb01/lb02配置
#反向代理
upstream web01_web02_lb01{
server 10.0.0.103:80 weight=1;
server 10.0.0.104:80 weight=1;
}
server {
listen 80;
server_name test.csq.xyz;
error_log /var/log/nginx/error-lb.csq.xyz.log notice;
access_log /var/log/nginx/access-lb.csq.xyz.log main;
location / {
proxy_pass http://web01_web02_lb01;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Real-Ip $remote_addr;
}
}
#keepalived配置实现nginx故障,自动切换到lb02
#MASTER
! Configuration File for keepalived
global_defs {
router_id lb01
}
vrrp_script check_nginx {
script /server/scripts/check_nginx.sh
interval 2
weight -60
user root
}
vrrp_instance vip_3 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.5/24 dev ens33 label ens33:0
}
notify_master "/scripts/notify.sh master"
notify_backup "/scripts/notify.sh backup"
notify_fault "/scripts/notify.sh fault"
track_script {
check_nginx
}
}
#BACKUP
! Configuration File for keepalived
global_defs {
router_id lb02
}
vrrp_script check_nginx {
script /server/scripts/check_nginx.sh
interval 2
weight -30
user root
}
vrrp_instance vip_3 {
state BACKUP
interface ens33
virtual_router_id 51
priority 50
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.5/24 dev ens33 label ens33:0
}
notify_master "/server/scripts/notify.sh master"
notify_backup "/server/scripts/notify.sh backup"
notify_fault "/server/scripts/notify.sh fault"
track_script {
check_nginx
}
}
#lb01/lb02设置通知脚本(记得安装psmisc软件包,脚本中使用了killall命令)
#发送邮件的前提是你配置好了发送邮件的功能
cat > /server/scripts/check_nginx.sh <<EOF
#!/bin/bash
killall -0 nginx || systemctl restart nginx
EOF
#设置执行权限
chmod +x /server/scripts/check_nginx.sh
#创建通知脚本(不要把脚本放在链接目录里面,脚本会不执行)
cat > /server/scripts/notify.sh <<'EOF'
#!/bin/bash
#
contact='2033717617@qq.com'
notify() {
mailsubject="$(hostname) 成为${1},vip漂移"
mailbody="$(date +'%F %T'): vrrp 切换, $(hostname) 切换为 $1"
echo "$mailbody" | s-nail -s "$mailsubject" $contact
}
case $1 in
master)
notify master
;;
backup)
notify backup
;;
fault)
notify fault
;;
*)
echo "Usage: $(basename $0) {master|backup|fault}"
exit 1
;;
esac
EOF
#赋予通知脚本执行权限
chmod +x /server/scripts/notify.sh
#允许VRRP协议
firewall-cmd --add-protocol=vrrp --permanent
firewall-cmd --reload
#重启生效
systemctl restart keepalived
模拟master节点故障
#修改nginx配置文件,随便修改错一下
#然后进行重新加载nginx
systemctl restart nginx
Job for nginx.service failed because the control process exited with error code.
See "systemctl status nginx.service" and "journalctl -xe" for details
查看邮件

nginx重新启动成功后

同步组
LVS NAT 模型VIP和DIP需要同步,需要同步组
vrrp_sync_group VG_1 {
group {
VI_1 # name of vrrp_instance (below)
VI_2 # One for each moveable IP
}
}
vrrp_instance VI_1 {
eth0
vip
}
vrrp_instance VI_2 {
eth1
dip
}

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)