
Ascend C算子开发心得:告别CPU思维,拥抱Cube核心的并行计算之美
参加2025昇腾CANN训练营,对我而言,不只是一次学习,更是一场思维的“格式化”。作为一名习惯了在CPU上用for循环解决一切问题的开发者,我曾以为AI算子开发不过是换个平台写代码。然而,当我第一个算子的性能数字出来时,我被深深刺痛了——我用着最先进的NPU,却写出了比CPU还慢的代码。这篇心得,就是记录我如何从“CPU思维”的牢笼中挣脱,真正理解并拥抱昇腾Cube核心并行计算之美的过程。

写在前面:
参加2025昇腾CANN训练营,对我而言,不只是一次学习,更是一场思维的“格式化”。作为一名习惯了在CPU上用for循环解决一切问题的开发者,我曾以为AI算子开发不过是换个平台写代码。然而,当我第一个算子的性能数字出来时,我被深深刺痛了——我用着最先进的NPU,却写出了比CPU还慢的代码。这篇心得,就是记录我如何从“CPU思维”的牢笼中挣脱,真正理解并拥抱昇腾Cube核心并行计算之美的过程。
一、CPU思维的“牢笼”:一个朴素的矩阵乘法
我们先来看一段典型的CPU式矩阵乘法代码,它完美体现了我们的思维定式——顺序、精确、控制到每一个元素:
// CPU思维:三重循环,微操每一个元素的计算
void matrix_mul_cpu(float* A, float* B, float* C, int M, int K, int N) {
for (int i = 0; i < M; ++i) {
for (int j = 0; j < N; ++j) {
float sum = 0;
for (int k = 0; k < K; ++k) {
sum += A[i * K + k] * B[k * N + j];
}
C[i * N + j] = sum;
}
}
}
这种代码在NPU上是灾难性的。NPU的强大不在于快速执行单条指令,而在于其成百上千的计算单元能够“同时”处理海量数据。我们的任务,不再是设计这个循环,而是为这个庞大的计算阵列“喂饱”数据。
二、解码NPU心脏:Cube核心的“肌肉记忆”
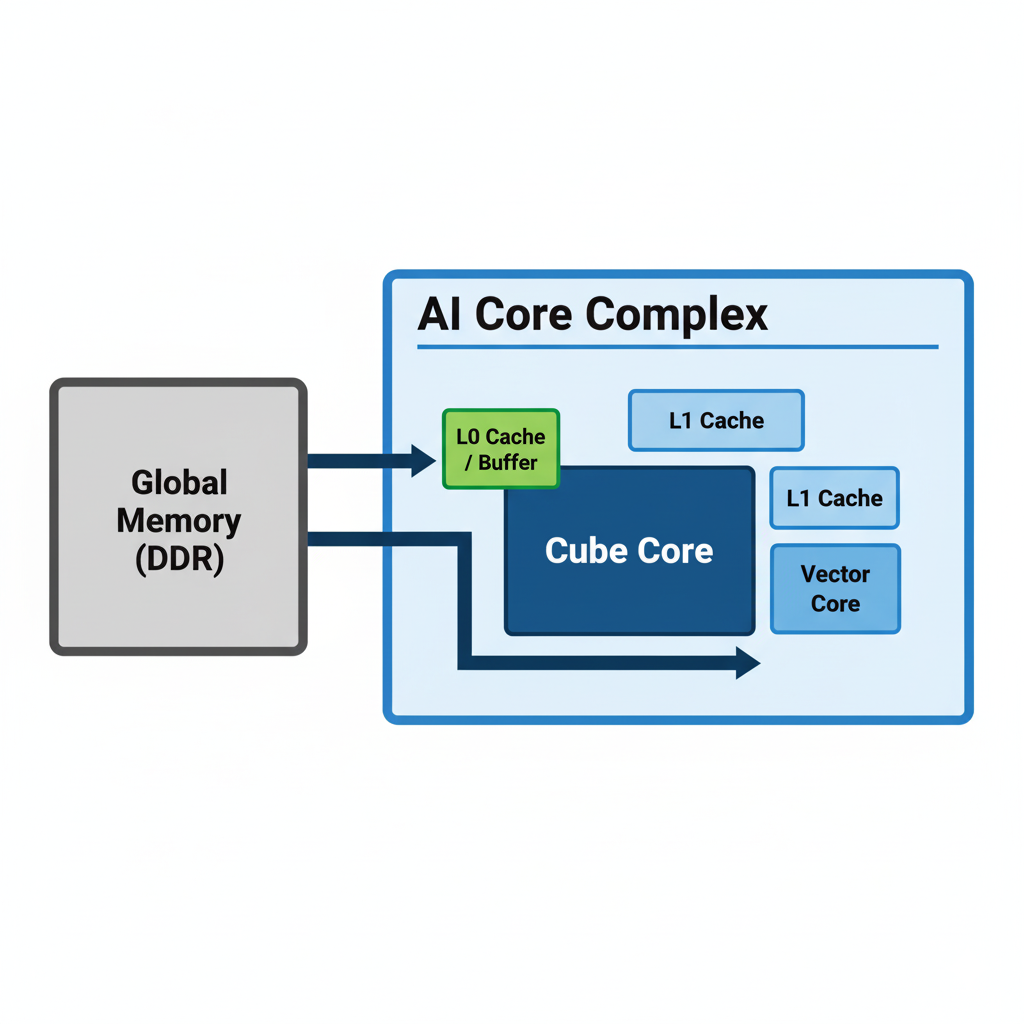
昇腾AI核心(Da Vinci架构)的心脏是Cube单元,它专为一件事而生:大规模矩阵乘法(MMA)。它不像CPU那样灵活,但它拥有恐怖的“肌肉记忆”。
- 硬件规格: Cube核心物理上就是一个
16x16的矩阵计算单元(以FP16为例),它能在单周期内完成C[16][16] = A[16][16] * B[16][16] + C[16][16]的运算。 - 高速缓存: 它拥有自己专属的、速度极快的本地内存(L0 Buffer)。这是它的“餐盘”,所有计算必须在这里发生。数据从DDR(Global Memory)到L0 Buffer的路途遥远且昂贵。
我的第一个顿悟: 我要服务的不是一个CPU,而是一个食量巨大但饭桌很小(L0 Buffer有限)的“大胃王”。我的工作核心从“设计算法”转变为“设计数据流”。
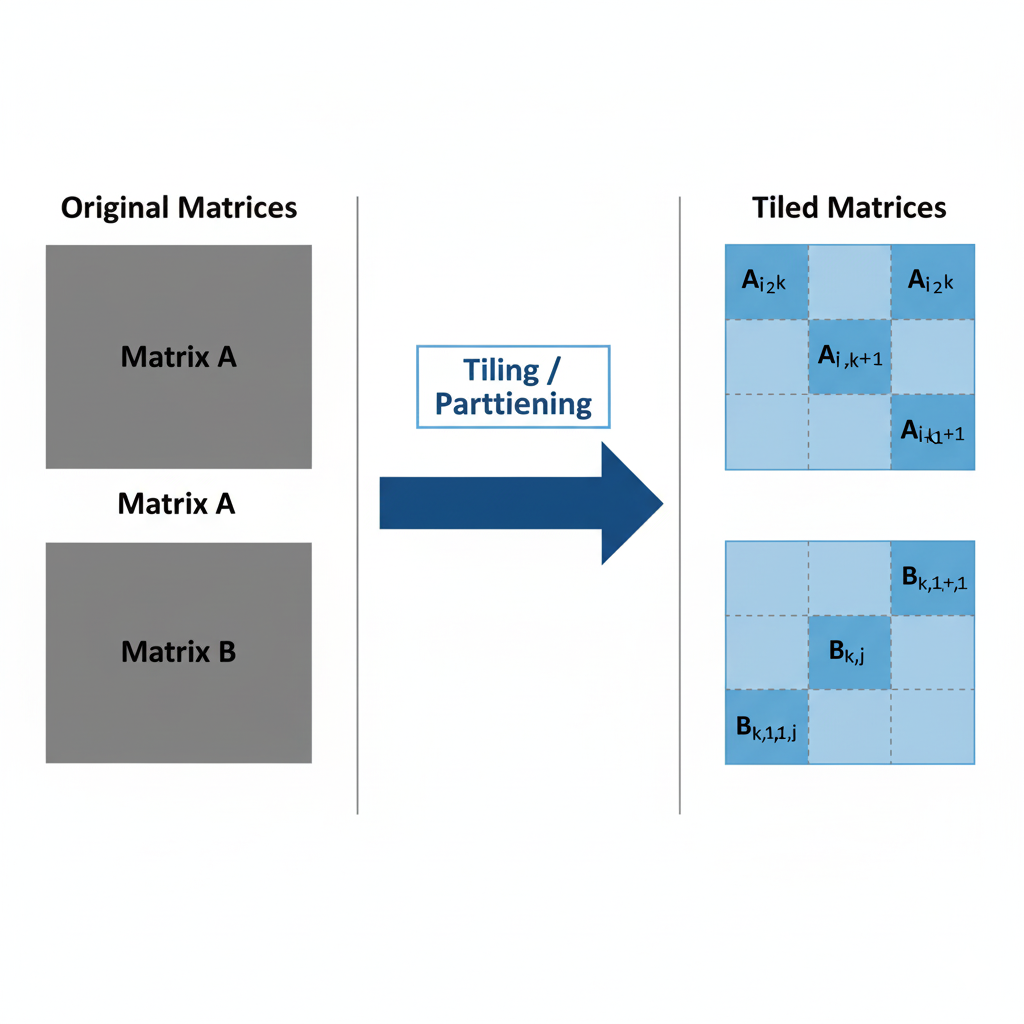
三、第一重觉醒:用Tiling(分块)喂饱“大胃王”
既然“饭桌”(L0 Buffer)小,而“食材”(整个矩阵)大,唯一的办法就是把食材切成小块(Tile),一块一块地喂。这就是Tiling。
假设我们要计算C(1024x1024) = A(1024x512) * B(512x1024),而我们的硬件一次只能处理64x64的块。
- 逻辑切分: 我们需要将A、B、C在逻辑上切分成多个
64x64的小块。 - 数据搬运: 通过DMA(直接内存访问),将A和B的对应小块从Global Memory搬运到L1 Cache,再到L0 Buffer。
- 核心计算: Cube核心对L0 Buffer中的小块执行矩阵乘法。
- 结果写回: 将计算结果从L0 Buffer搬运回Global Memory。
这个过程需要精密的循环控制,但思考的维度已经完全不同。我们关心的是数据块的索引和依赖关系,而不是单个元素的索引。
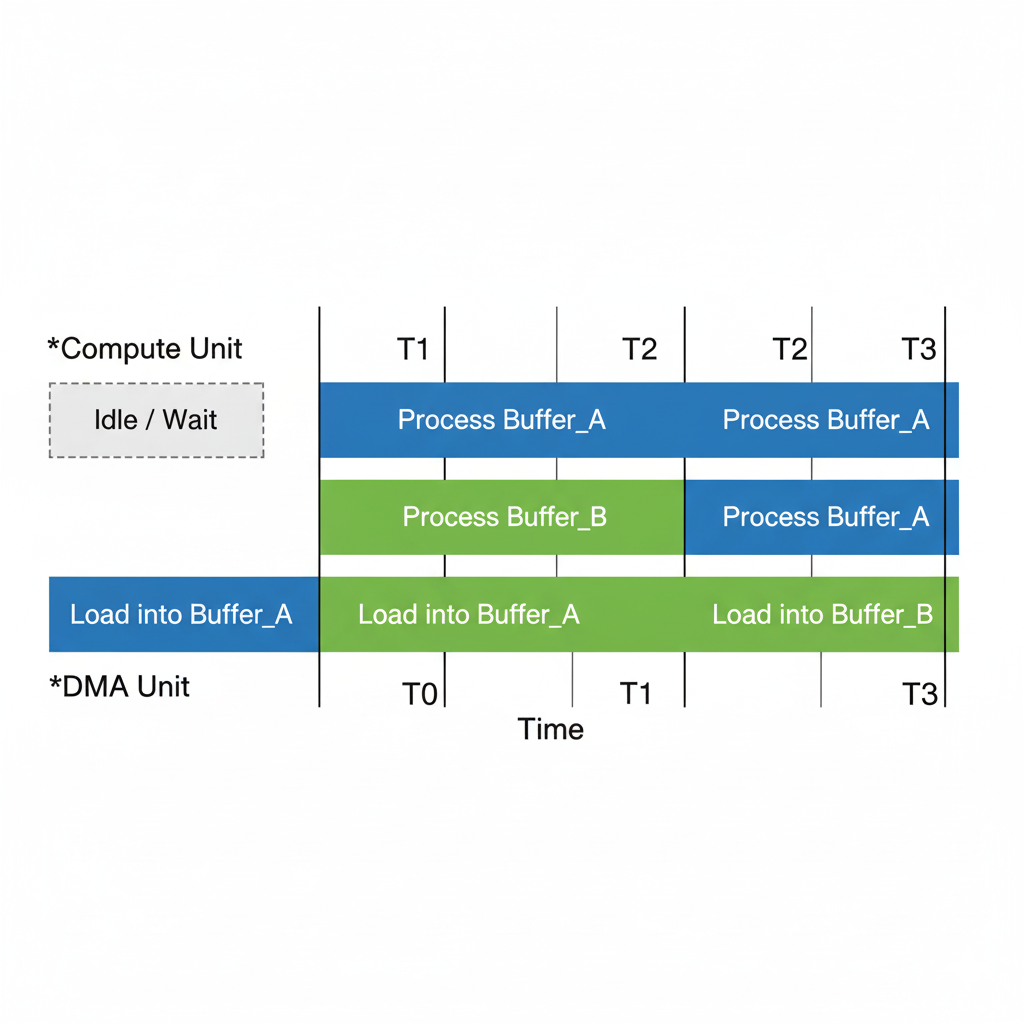
四、第二重飞跃:双缓冲(Double Buffering)流水线的艺术
仅仅会Tiling还不够,我们很快会遇到新的瓶瓶颈:Cube核心在计算时,DMA在等待;DMA在搬运数据时,Cube核心在空闲。这就像一个只有一个厨师和一个服务员的餐厅,效率极低。
解决方案是流水线(Pipeline),而实现它的关键技术是双缓冲(Double Buffering)。
我们在L0/L1中开辟两块缓冲区,比如buffer_A和buffer_B。
- Step 1: DMA将第1个数据块加载到
buffer_A。 - Step 2: Cube核心开始处理
buffer_A中的数据。与此同时,DMA开始将第2个数据块加载到buffer_B。 - Step 3: Cube核心处理完
buffer_A,开始处理buffer_B。与此同时,DMA开始将第3个数据块加载到buffer_A(覆盖旧数据)。 - 循环往复…
通过这种方式,数据搬运(I/O)和核心计算(Compute)被完美地重叠起来,极大地隐藏了内存延迟,让Cube核心始终处于“忙碌”状态。
五、从命令到宣言:用Ascend C原语“表达意图”
Ascend C的精髓在于,它让我们从繁琐的底层实现中解脱出来,用更高级的“原语(Primitives)”来表达计算意图。
下面的伪代码展示了这种思维转变:
[代码块:简化的Ascend C Kernel伪代码结构]
// Ascend C思维:表达数据流和计算意图
class MyMatmulKernel {
public:
// 构造函数:初始化Tiling信息、IO队列等
MyMatmulKernel(...) { ... }
// 主流程
void Process() {
// 1. 定义Global Memory和Local Memory的Tensor
Tensor<float> A_global, B_global, C_global;
Tensor<float> A_local, B_local, C_local; // 在L0 Buffer上
// 2. 双缓冲的第一个数据块预取
DataCopy(A_local, A_global.GetTile(0, 0));
DataCopy(B_local, B_global.GetTile(0, 0));
// 3. 循环处理所有Tile,构建流水线
for (int i = 0; i < num_tiles; ++i) {
// 同步,等待上一轮的DMA搬运完成
Sync();
// 预取下一轮的数据到另一个buffer(双缓冲逻辑)
if (i < num_tiles - 1) {
DataCopy(A_local_next_buffer, ...);
DataCopy(B_local_next_buffer, ...);
}
// 对当前buffer的数据执行计算
MatMul(C_local, A_local, B_local); // <-- 这就是意图表达!
// 同步,等待计算完成
Sync();
// 将结果写回Global Memory
DataCopy(C_global.GetTile(...), C_local);
}
}
};
看,我们不再关心三重for循环,而是像指挥官一样,调度DataCopy和MatMul这两个“兵种”,让它们在流水线上协同作战。这才是NPU编程的正确打开方式。
结语:这不止是技术,更是一场思维革命
从CPU到NPU,最大的挑战不在于学习新的API,而在于彻底颠覆我们对“计算”的认知。我们必须从一个关注过程的“工匠”,转变为一个规划全局的“架构师”。当你不再纠结于单个元素的命运,而是开始享受调度海量数据洪流的快感时,你就真正领悟了并行计算的壮丽与美妙。
加入我们,一起在CANN的世界里“码力全开”!
训练营简介:
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
昇腾训练营报名链接:
https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)