
神经网络学习笔记
本文介绍了神经网络的基本原理与应用。神经网络由输入层、隐藏层和输出层构成,通过权重连接和激活函数实现非线性变换。核心内容包括神经元计算、正向传播过程和典型应用场景(需求预测、人脸识别、手写数字识别)。文章详细演示了使用TensorFlow和NumPy实现神经网络的步骤,比较了向量化与循环计算的性能差异,并简要介绍了CNN、RNN等进阶方向。
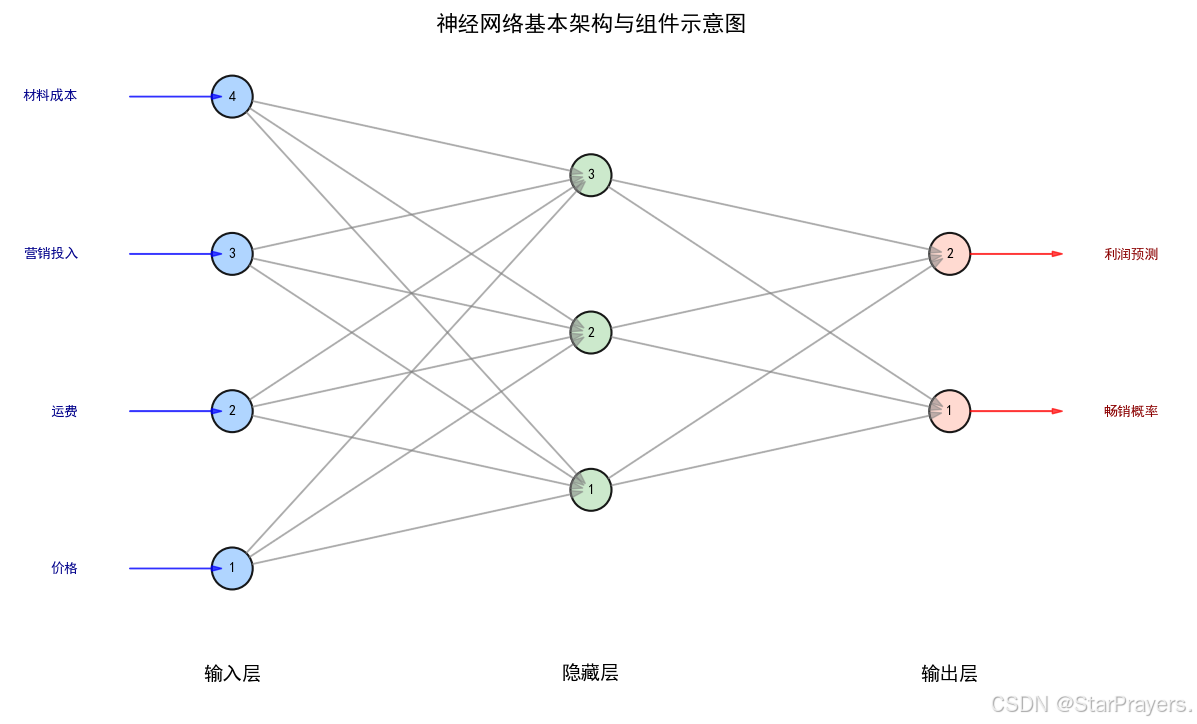
一、神经网络的基本架构与组件
神经网络是模仿生物神经元的计算模型,核心由输入层、隐藏层、输出层组成,每层包含多个神经元(neuron),神经元间通过权重(weight, w)连接,并有偏置(bias, b)调整输出。
- 输入层:接收原始数据,如图片像素、商品属性(价格、运费、营销投入、材料等)。
- 隐藏层:对输入数据进行多层变换,提取特征。隐藏层数量≥1,多个隐藏层的网络称为深度神经网络(DNN)。
- 输出层:输出预测结果,如分类概率(是否为畅销品、手写数字类别)、回归数值等。
二、神经元的运算与激活函数
单个神经元的运算可总结为:a=g(w1x1+w2x2+⋯+wnxn+b)其中 g(⋅) 是激活函数,作用是给线性变换加入非线性,让网络能拟合复杂关系。
- sigmoid 函数:
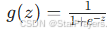 ,输出在 (0,1) 之间,常用于二分类问题的输出层(如 “是否畅销”“是否为类别 1”)。
,输出在 (0,1) 之间,常用于二分类问题的输出层(如 “是否畅销”“是否为类别 1”)。 - 激活函数的意义:若没有激活函数,多层神经网络会退化为单层线性模型,无法学习复杂模式。
三、神经网络的符号表示与正向传播
为了规范描述多层网络的运算,需要明确符号系统:
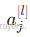 :第 l 层第 j 个神经元的激活值(即该神经元的输出)。
:第 l 层第 j 个神经元的激活值(即该神经元的输出)。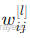 :第 l 层第 i 个神经元与第 l−1 层第 j 个神经元之间的权重。
:第 l 层第 i 个神经元与第 l−1 层第 j 个神经元之间的权重。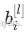 :第 l 层第 i 个神经元的偏置。
:第 l 层第 i 个神经元的偏置。
正向传播(Forward Propagation)是数据从输入层到输出层的计算过程,公式为: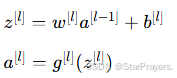
其中![]() 是第 l 层的加权和,
是第 l 层的加权和,![]() 是第 l 层的激活函数。
是第 l 层的激活函数。
四、典型应用场景与案例
这些图片覆盖了多个神经网络的实际应用,我们逐一分析:
1. 需求预测(Demand Prediction)
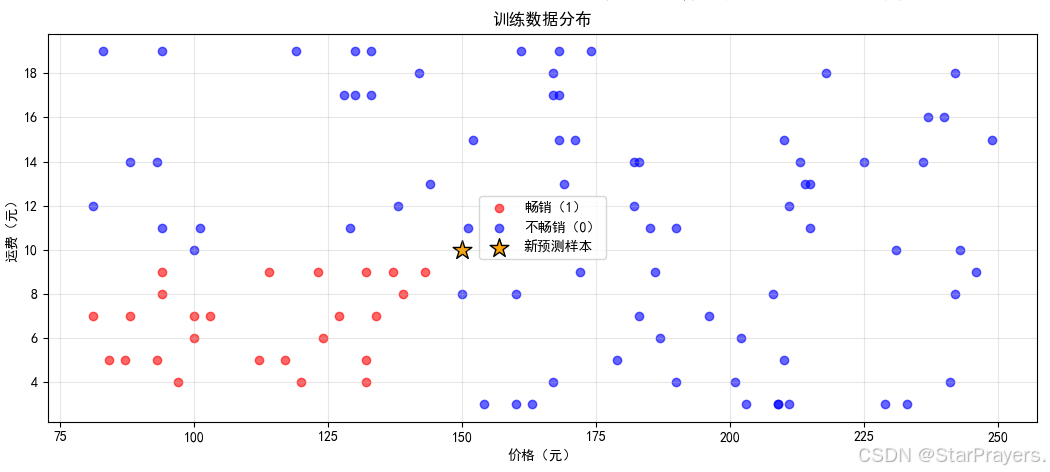
以 “商品是否畅销” 为例,输入层是商品属性(价格、运费、营销、材料等),隐藏层提取这些属性的组合特征,输出层通过 sigmoid 函数输出 “是畅销品” 的概率。
- 意义:帮助企业预判商品市场表现,优化生产、库存和营销策略。
2. 人脸识别(Face Recognition)
图片展示了将人脸图像转化为像素矩阵(如 100×100 像素),再展开为一维向量(长度 10000)输入神经网络。网络学习人脸的特征模式(如五官位置、轮廓),实现身份识别。
- 技术延伸:实际应用中,常采用卷积神经网络(CNN)提取空间特征,效果比全连接网络更优。
3. 手写数字识别(Handwritten Digit Recognition)
手写数字图像(如 28×28 像素)被处理为高维向量,输入神经网络后,输出层预测是 0-9 中某数字的概率。
- 经典数据集:MNIST,包含大量手写数字样本,是入门深度学习的 “Hello World” 级任务。
五、工具实现:TensorFlow 与 NumPy
展示如何用TensorFlow(深度学习框架)和NumPy(数值计算库)搭建神经网络:
1. TensorFlow 实现示例
以二分类任务为例,步骤如下:
import tensorflow as tf
import numpy as np
# 定义输入数据
x = np.array([[200., 17.], [120., 5.], ...]) # 输入特征
y = np.array([[1], [0], ...]) # 标签(1表示畅销,0表示不畅销)
# 搭建网络:1个隐藏层(3个神经元,sigmoid激活)+ 输出层(1个神经元,sigmoid激活)
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=3, activation='sigmoid', name='layer1'),
tf.keras.layers.Dense(units=1, activation='sigmoid', name='layer2')
])
# 编译与训练模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(x, y, epochs=100)
# 预测新数据
x_new = np.array([[150., 10.]])
prediction = model.predict(x_new)
print("是否畅销的概率:", prediction[0][0])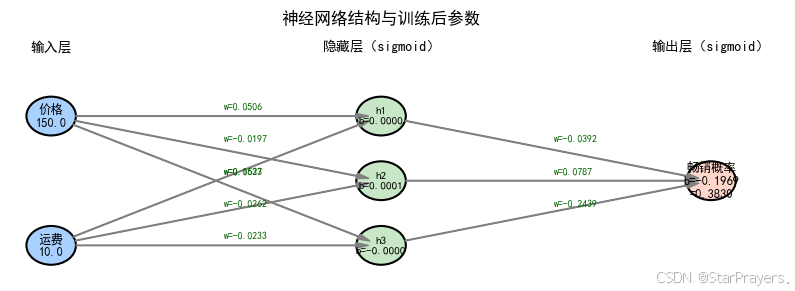
①导入库
import tensorflow as tf
import numpy as nptensorflow:谷歌开发的深度学习框架,提供搭建和训练神经网络的工具(这里用的是高层 APItf.keras)。numpy:用于数值计算的 Python 库,处理输入数据的数组格式。
②定义输入数据
x = np.array([[200., 17.], [120., 5.], ...]) # 输入特征
y = np.array([[1], [0], ...]) # 标签(1表示畅销,0表示不畅销)-
输入特征
x:二维数组,每行代表一个样本,每列代表一个特征。例如:[200., 17.]可能表示 “价格 200 元,运费 17 元” 的商品;[120., 5.]可能表示 “价格 120 元,运费 5 元” 的商品;...表示还有更多样本(实际使用时需要足够多的数据才能训练出有效的模型)。
-
标签
y:二维数组,与输入特征一一对应,用于告诉模型 “这个样本的正确答案是什么”:1表示该商品 “畅销”;0表示该商品 “不畅销”;- 这是二分类问题的典型标签格式(非此即彼)。
③搭建神经网络
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=3, activation='sigmoid', name='layer1'),
tf.keras.layers.Dense(units=1, activation='sigmoid', name='layer2')
])-
tf.keras.Sequential:序贯模型,是最基础的神经网络结构,层与层之间按顺序连接(前一层的输出作为后一层的输入)。 -
第一层(隐藏层,
layer1):Dense(units=3, activation='sigmoid')表示全连接层:units=3:该层有 3 个神经元(与前面绘制的神经网络图中的隐藏层对应);activation='sigmoid':使用 sigmoid 激活函数,将神经元的输出压缩到(0,1)之间,为网络引入非线性能力(否则多层网络会退化为线性模型);- 输入:接收来自输入层的特征(这里输入层有 2 个特征,与
x的列数一致); - 输出:3 个经过 sigmoid 变换的数值,作为下一层的输入。
-
第二层(输出层,
layer2):Dense(units=1, activation='sigmoid'):units=1:该层只有 1 个神经元,因为我们需要的输出是 “是否畅销” 的概率(一个数值);activation='sigmoid':输出值在(0,1)之间,可直接解释为 “畅销的概率”(例如 0.8 表示 80% 概率畅销);- 输入:接收隐藏层的 3 个输出值;
- 输出:最终的预测概率。
④编译模型(配置训练参数)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])在训练前需要配置 3 个核心参数:
-
优化器(
optimizer='adam'):负责调整网络中的权重(w)和偏置(b),以减小预测误差。adam是目前最常用的优化器之一,它能自适应调整学习率,训练效率高。 -
损失函数(
loss='binary_crossentropy'):衡量预测值与真实标签的差距(误差)。对于二分类问题(标签为 0 或 1),binary_crossentropy(二元交叉熵)是最佳选择,公式为: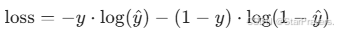 其中
其中 y是真实标签(0 或 1),\hat{y}是预测概率。误差越大,损失值越高,优化器的目标就是最小化这个损失。 -
评估指标(
metrics=['accuracy']):训练过程中监控的指标,accuracy(准确率)表示 “预测正确的样本数 / 总样本数”,用于直观判断模型效果。
⑤训练模型
model.fit(x, y, epochs=100)x和y:训练数据(特征和标签);epochs=100:训练轮次,即整个数据集被模型 “学习” 100 遍。每一轮训练中,模型会:- 用当前的权重和偏置对
x做预测(正向传播); - 计算预测值与
y的损失(binary_crossentropy); - 通过反向传播算法调整权重和偏置,减小损失;
- 用当前的权重和偏置对
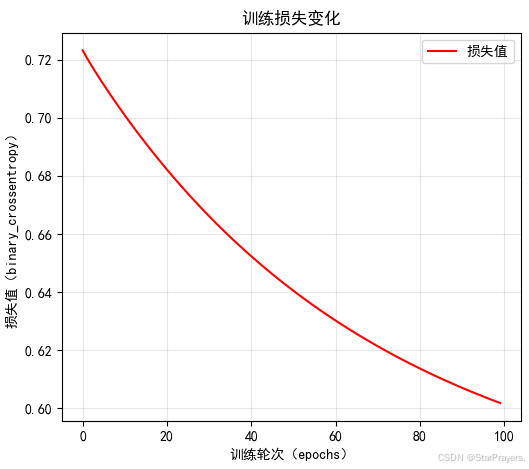
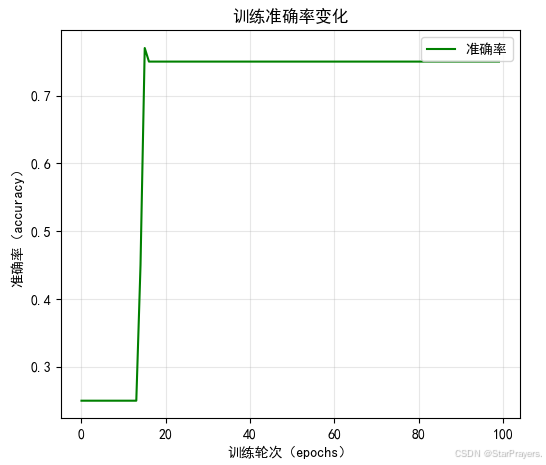
- 训练过程中会输出每一轮的损失(
loss)和准确率(accuracy),通常损失会逐渐下降,准确率逐渐上升(表示模型在进步)。
⑥预测新数据
x_new = np.array([[150., 10.]]) # 新商品:价格150元,运费10元
prediction = model.predict(x_new)
print("是否畅销的概率:", prediction[0][0])x_new:需要预测的新样本(格式与训练数据x一致,必须是二维数组,即使只有一个样本);model.predict(x_new):用训练好的模型对新样本做预测,输出结果是一个二维数组(形状为(样本数, 1));prediction[0][0]:提取第一个样本的预测概率(例如输出0.75表示该商品有 75% 的概率畅销)。
2. NumPy 手动实现正向传播
若想深入理解底层运算,可手动实现正向传播:
import numpy as np
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 定义权重和偏置(示例值)
w1 = np.array([[1, 4], [3, 5], [2, 6]]) # 隐藏层权重:3个神经元 × 2个输入特征
b1 = np.array([[-1], [1], [2]]) # 隐藏层偏置:3个神经元
w2 = np.array([[7, 8, 9]]) # 输出层权重:1个神经元 × 3个隐藏层输出
b2 = np.array([[0]]) # 输出层偏置:1个神经元
# 输入数据
x = np.array([[200, 17]]) # 1个样本,2个特征
# 正向传播
z1 = np.dot(w1, x.T) + b1 # 隐藏层加权和:3×1
a1 = sigmoid(z1) # 隐藏层激活值:3×1
z2 = np.dot(w2, a1) + b2 # 输出层加权和:1×1
a2 = sigmoid(z2) # 输出层激活值(概率):1×1
print("预测为畅销品的概率:", a2[0][0])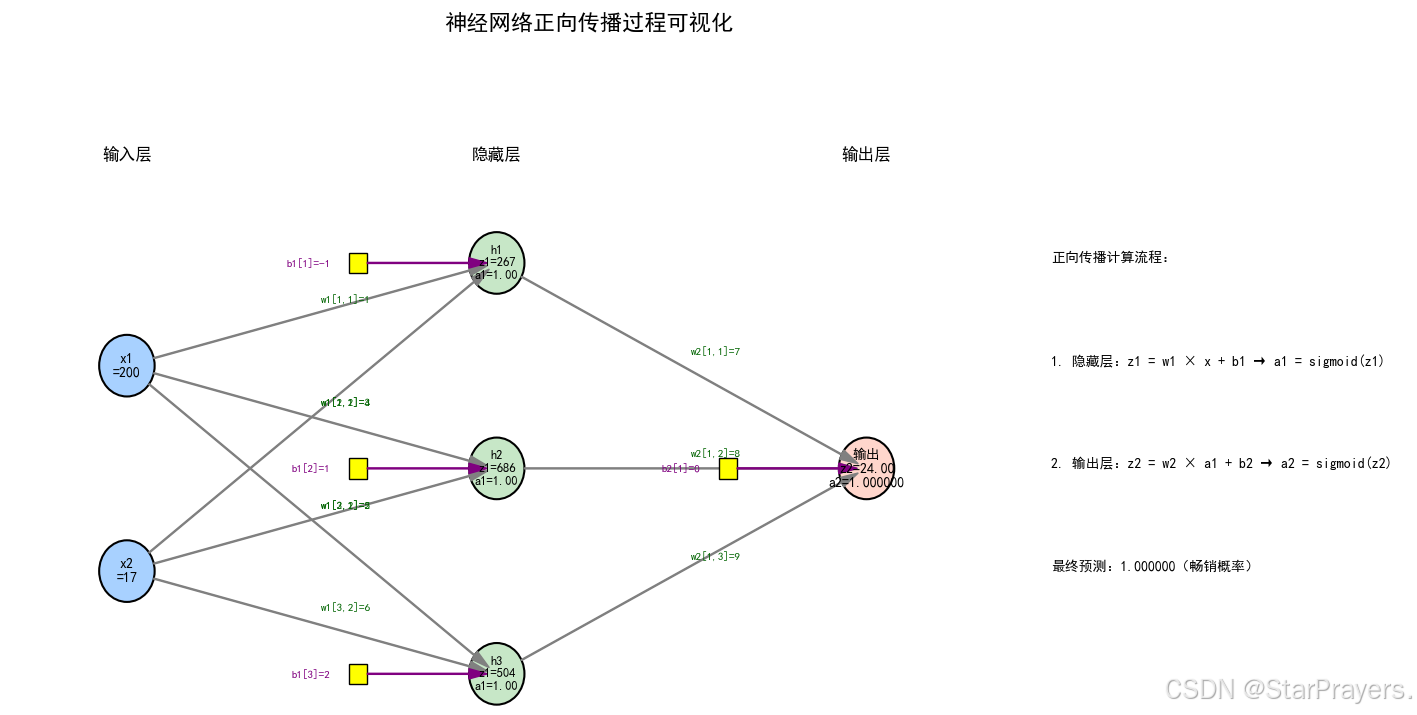
①激活函数定义
def sigmoid(z):
return 1 / (1 + np.exp(-z))- sigmoid 函数是神经网络中常用的激活函数,作用是将任意实数输入(
z)映射到(0, 1)之间的输出。 - 数学意义:为线性计算结果加入非线性变换,让网络能学习复杂的特征关系(如果没有激活函数,多层网络会退化为单层线性模型)。
- 这里用于隐藏层和输出层的激活,输出层的结果可直接作为 “畅销概率”(因为范围在 0-1 之间)。
②定义权重(Weight)和偏置(Bias)
权重和偏置是神经网络的 “参数”,决定了输入特征如何被处理。模型训练的本质就是调整这些参数,使预测结果更接近真实标签。
# 隐藏层权重:3个神经元 × 2个输入特征
w1 = np.array([[1, 4], [3, 5], [2, 6]]) w1是一个3×2的矩阵,对应隐藏层的 3 个神经元与输入层的 2 个特征之间的连接权重:- 第 1 行
[1, 4]:隐藏层第 1 个神经元与输入特征 1(如价格)、特征 2(如运费)的连接权重; - 第 2 行
[3, 5]:隐藏层第 2 个神经元与两个输入特征的连接权重; - 第 3 行
[2, 6]:隐藏层第 3 个神经元与两个输入特征的连接权重。
- 第 1 行
# 隐藏层偏置:3个神经元
b1 = np.array([[-1], [1], [2]]) b1是一个3×1的矩阵,每个元素对应隐藏层一个神经元的偏置:- 偏置的作用是 “微调” 神经元的输出,类似于线性方程
y = wx + b中的b,让模型更灵活(即使输入为 0,神经元也能有非 0 输出)。
- 偏置的作用是 “微调” 神经元的输出,类似于线性方程
# 输出层权重:1个神经元 × 3个隐藏层输出
w2 = np.array([[7, 8, 9]]) w2是一个1×3的矩阵,对应输出层的 1 个神经元与隐藏层的 3 个神经元之间的连接权重:[7, 8, 9]分别是输出层神经元与隐藏层第 1、2、3 个神经元的连接权重。
# 输出层偏置:1个神经元
b2 = np.array([[0]]) b2是一个1×1的矩阵,对应输出层神经元的偏置(这里取值为 0,仅为示例)。
③输入数据定义
x = np.array([[200, 17]]) # 1个样本,2个特征x是一个1×2的矩阵,表示 1 个商品样本的 2 个输入特征:- 例如
[200, 17]可表示 “价格 200 元,运费 17 元”(与前面 TensorFlow 示例的输入特征对应)。 - 注意形状是
(1, 2)(二维数组),而非(2,)(一维数组),因为神经网络通常处理批量样本(这里批量大小为 1)。
- 例如
④正向传播计算(核心步骤)
正向传播是数据从输入层经过隐藏层到输出层的计算过程,分为两步:加权和计算(线性变换)和激活函数处理(非线性变换)。
1. 隐藏层计算
# 隐藏层加权和:3×1
z1 = np.dot(w1, x.T) + b1 -
目的:计算隐藏层每个神经元的输入加权和(线性变换)。
-
运算拆解:
x.T:将输入x(1×2)转置为2×1的列向量(方便矩阵乘法);np.dot(w1, x.T):矩阵乘法,w1(3×2) ×x.T(2×1) = 结果(3×1),即每个隐藏层神经元的加权和(不含偏置);+ b1:加上隐藏层偏置b1(3×1),最终得到z1(3×1),每个元素对应隐藏层一个神经元的加权和。
举例:
-
隐藏层第 1 个神经元的
z1值 =1×200 + 4×17 + (-1)=200 + 68 - 1 = 267; -
隐藏层第 2 个神经元的
z1值 =3×200 + 5×17 + 1=600 + 85 + 1 = 686; -
隐藏层第 3 个神经元的
z1值 =2×200 + 6×17 + 2=400 + 102 + 2 = 504; -
因此
z1 = [[267], [686], [504]]。
# 隐藏层激活值:3×1
a1 = sigmoid(z1) - 目的:对加权和
z1应用 sigmoid 激活函数,得到隐藏层的输出(非线性变换)。 - 计算结果:由于
sigmoid(z)当z很大时趋近于 1(例如sigmoid(267)≈1,sigmoid(686)≈1,sigmoid(504)≈1),因此a1 ≈ [[1], [1], [1]](实际计算中会非常接近 1)。
2. 输出层计算
# 输出层加权和:1×1
z2 = np.dot(w2, a1) + b2 -
目的:计算输出层神经元的输入加权和(线性变换)。
-
运算拆解:
np.dot(w2, a1):矩阵乘法,w2(1×3) ×a1(3×1) = 结果(1×1),即输出层神经元的加权和(不含偏置);+ b2:加上输出层偏置b2(1×1),最终得到z2(1×1)。
举例(基于
a1≈[[1], [1], [1]]):z2 = 7×1 + 8×1 + 9×1 + 0 = 24。
# 输出层激活值(概率):1×1
a2 = sigmoid(z2) - 目的:对输出层加权和
z2应用 sigmoid 激活函数,得到最终的预测概率。 - 计算结果:
sigmoid(24)≈1(因为sigmoid(z)在z>10时已非常接近 1),因此a2≈[[1]]。
⑤输出预测结果
print("预测为畅销品的概率:", a2[0][0])a2[0][0]提取输出层的预测值(因为a2是1×1矩阵),结果约为1.0,表示该商品 “畅销的概率接近 100%”。
⑥总结:正向传播的核心逻辑
整个过程可用公式概括为:
- 隐藏层:
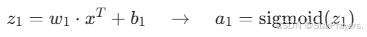
- 输出层:
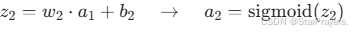
其中:
z表示加权和(线性变换),a表示激活值(非线性变换);- 权重
w和偏置b是模型从数据中学习的参数(这里为示例值,实际训练中会不断调整); - 最终输出
a2是预测概率,用于判断商品是否畅销。
六、性能优化:向量化 vs 循环
在数值计算中, 向量化(Vectorization) 比循环更高效(利用 CPU/GPU 的并行计算能力)。
循环实现(低效):
def dense_loop(w, b, a_prev):
units = w.shape[0]
a_out = np.zeros(units)
for i in range(units):
z = 0
for j in range(a_prev.shape[0]):
z += w[i, j] * a_prev[j]
z += b[i]
a_out[i] = sigmoid(z)
return a_out
--------------------------------------------------------
def dense_loop(w, b, a_prev):
# 步骤1:获取当前层的神经元数量(units)
units = w.shape[0]
# 步骤2:初始化输出激活值数组(全0)
a_out = np.zeros(units)
# 步骤3:遍历当前层的每个神经元
for i in range(units):
# 步骤4:初始化当前神经元的加权和z
z = 0
# 步骤5:遍历上一层的每个神经元,计算加权和(w[i,j] * a_prev[j])
for j in range(a_prev.shape[0]):
z += w[i, j] * a_prev[j]
# 步骤6:加上当前神经元的偏置b[i]
z += b[i]
# 步骤7:对z应用sigmoid激活函数,得到当前神经元的输出
a_out[i] = sigmoid(z)
# 步骤8:返回当前层所有神经元的激活值
return a_out向量化实现(高效):
def dense_vectorized(w, b, a_prev):
z = np.dot(w, a_prev) + b
a_out = sigmoid(z)
return a_out
--------------------------------------------------------
def dense_vectorized(w, b, a_prev):
# 步骤1:计算当前层所有神经元的加权和(线性变换)
z = np.dot(w, a_prev) + b
# 步骤2:对加权和应用sigmoid激活函数(非线性变换)
a_out = sigmoid(z)
# 步骤3:返回当前层的激活值
return a_out-
向量化通过矩阵运算一次性完成所有神经元的计算,速度远快于循环。
七、扩展:神经网络的进阶方向
这些基础内容可延伸到更复杂的领域:
- 卷积神经网络(CNN):处理图像、视频,通过卷积层提取空间特征(如人脸识别、自动驾驶的图像感知)。
- 循环神经网络(RNN):处理序列数据,如自然语言(机器翻译、情感分析)、时间序列(股票预测、气象预报)。
- Transformer:基于注意力机制的模型,在 NLP(ChatGPT)、计算机视觉(图像生成)中取得突破性成果。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)