
基于深度强化学习的微网P2P能源交易系统代码功能解析
环境仿真模块():构建微网能源生产、消费与交易的仿真环境强化学习算法模块:实现DDPG、PPO、VPG三种算法(core_*.py及主程序)工具支撑模块(utils目录):提供日志、并行计算、模型管理等辅助功能代码遵循OpenAI Gym环境规范设计交互接口,基于PyTorch实现神经网络计算,支持多进程并行训练,完整覆盖"环境建模-智能决策-实验验证"的研究流程。
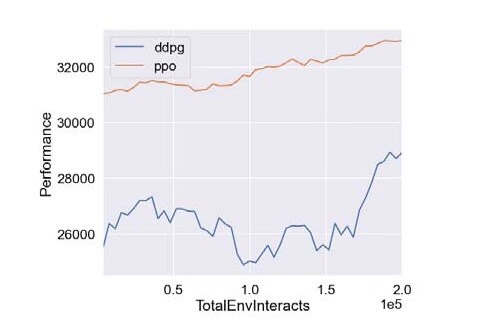
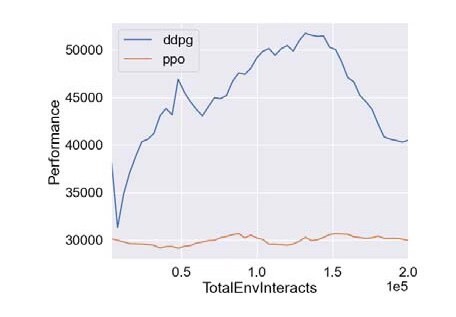
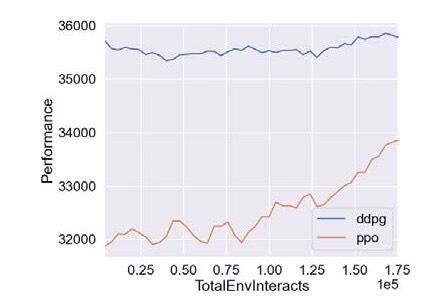
基于深度强化学习的微网P2P能源研究 摘要:代码主要做的是基于深度强化学习的微网P2P能源研究,具体为采用PPO算法以及DDPG算法对P2P能源模型进行仿真验证,代码对应的是三篇文献,内容分别为基于深度强化学习微网控制研究,多种深度强化学习优化效果对比,以及微网实施P2P经济效益评估 复现结果非常良好,结果图展示如下:
一、代码结构与核心组件概述
提交的代码库围绕"微网P2P能源交易"场景构建了完整的深度强化学习实验框架,整体采用模块化设计,包含三大核心组件:
- 环境仿真模块(
environment.py):构建微网能源生产、消费与交易的仿真环境 - 强化学习算法模块:实现DDPG、PPO、VPG三种算法(
core_*.py及主程序) - 工具支撑模块(
utils目录):提供日志、并行计算、模型管理等辅助功能
代码遵循OpenAI Gym环境规范设计交互接口,基于PyTorch实现神经网络计算,支持多进程并行训练,完整覆盖"环境建模-智能决策-实验验证"的研究流程。
二、环境仿真模块(environment.py)
该模块是系统的核心交互层,通过面向对象设计精确模拟微网系统的物理特性与交易规则,为强化学习代理提供标准化的状态观测与奖励反馈。
1. 基础模型设计
- 负荷模型(Load类)
- 功能:计算特定类型负荷的能源消耗量
- 核心逻辑:基于
usage_trends.csv的时间序列数据,通过"最大负荷×时段占比"计算实时能耗 - 关键方法:
getusage()返回单负荷能耗,gettotal_usage()计算同类负荷总能耗
- 电池模型(Battery类)
- 功能:模拟储能设备的充放电行为与容量管理
- 核心参数:最大容量(
maxcapacity)、放电系数(dischargefactor)、初始容量(initial_capacity) - 关键方法:
charge(amount):处理充电逻辑,包含溢出保护(超出容量部分无效)discharge(amount):处理放电逻辑,包含欠充保护(剩余容量不足时返回实际放电量)get_remaining():返回当前剩余容量
- 发电模型(Generation类)
- 功能:整合可再生能源发电数据
- 数据来源:太阳能数据(
Data/Solar/)与风能数据(Data/wind/) - 关键方法:
get_generated()返回指定时间步的总发电量
- 微网模型(Microgrid类)
- 功能:封装单微网的完整能源系统
- 组成结构:包含多个Load实例(负荷)、1个Battery实例(储能)、1个Generation实例(发电)
- 核心能力:
- 状态感知:
getbatteryremaining()、gettotalload()、gettotalgenerated() - 交易决策支持:
to_trade()计算供需差额(正数为盈余,负数为 deficit) - 能源调度:
supply()处理负荷满足逻辑,优先使用本地发电,不足时放电或购电
2. 环境交互接口(MicrogridEnv类)
作为Gym环境实现,该类定义了智能体与微网系统的交互规范:
- 状态空间(Observation Space)
- 维度:4维连续空间
- 组成:[电池剩余容量, 总负荷, 总发电量, 上一时刻电价]
- 范围:各维度均做归一化处理,映射至[0,1]区间便于网络学习
- 动作空间(Action Space)
- 维度:4维连续向量,具体含义:
- 动作类型(0-1:购买;1-2:出售;≥2:不交易)
- 目标微网索引(0-1代表其他两个微网)
- 交易能源量(kW·h)
- 交易价格(美分/kW·h)
- 约束:能源量不超过电池容量,价格需在成本与公共电网电价间
- 核心交互逻辑(step方法)
1. 动作解析:提取动作类型、目标微网、交易量和价格
2. 有效性校验:检查交易行为与自身供需状态是否匹配(如盈余时不能购买)
3. 交易执行:计算输电损耗(基于距离矩阵),更新双方电池容量
4. 状态更新:推进时间步,更新发电量、负荷需求等环境状态
5. 奖励计算:根据交易收益、供需平衡情况生成奖励信号
- 奖励机制设计
- 基础奖励:交易价格优于公共电网时的价差收益(购买时低价奖励,出售时高价奖励)
- 特殊奖励:实现完全供需平衡时+100奖励
- 惩罚项:
- 交易行为与状态冲突(如赤字时出售):-10
- 价格不合理(超出成本/电网价):-5
- 交易量超出实际能力:-3
三、强化学习算法模块
1. 算法核心框架(core_*.py)
三类算法均采用Actor-Critic架构,核心差异体现在策略更新方式:
- 通用组件
mlp():快速构建多层感知机,支持自定义隐藏层数量与神经元数- 网络结构:
- Actor网络:输入状态,输出连续动作(DDPG用Tanh限制范围,PPO/VPG用高斯分布建模)
- Critic网络:DDPG中输入"状态+动作"输出Q值;PPO/VPG中输入状态输出V值
- DDPG核心(core_DDPG.py)
- 双网络设计:主网络(
Actor/QFunction)与目标网络(ActorTarg/QFunctionTarg) - 目标网络更新:采用Polyak平均(
polyak=0.995)缓慢跟踪主网络参数 - 损失函数:Q网络为MSE损失,Actor网络为Q值梯度上升
- PPO核心(core_PPO.py)
- 单一网络结构:
ActorCritic同时输出策略分布与状态价值 - 关键损失:剪辑损失(
clip_ratio=0.2)限制策略更新幅度 - 优势估计:采用GAE-Lambda(
lam=0.97)减少优势估计方差
- VPG核心(core_vpg.py)
- 基础策略梯度实现:通过蒙特卡洛回报估计策略梯度
- 价值函数优化:独立的V网络,采用MSE损失拟合回报
2. 训练流程实现
- DDPG训练流程(main_DDPG.py)
1. 初始化:创建环境、Actor-Critic网络、经验回放池(ReplayBuffer)
2. 探索阶段:前10000步随机动作填充经验池
3. 交互循环: - 策略执行:添加高斯噪声(
act_noise=0.1)的探索动作 - 经验存储:将(s,a,r,s',done)存入回放池
- 网络更新:每50步采样100条经验,交替更新Q网络与Actor网络
4. 目标网络软更新:每次主网络更新后执行Polyak平均
- PPO训练流程(mainPPO.py)
1. 并行初始化:MPI多进程(默认4进程)创建环境副本
2. 轨迹收集:每个进程收集localstepsperepoch步数据存入PPOBuffer
3. 优势计算:使用GAE-Lambda估计优势函数并标准化
4. 策略优化: - 多轮更新(80次迭代)最小化剪辑损失
- KL散度监控(
target_kl=0.01)防止策略突变
5. 价值网络更新:同步优化V值拟合误差
- VPG训练流程(main_vpg.py)
1. 轨迹收集:单进程或多进程收集完整episode数据
2. 回报计算:基于蒙特卡洛方法计算折扣回报
3. 策略更新:单次梯度上升最大化累积回报
4. 价值更新:迭代优化V网络拟合回报值
四、工具支撑模块(utils目录)
1. 实验管理(logx.py)
Logger类:记录训练指标(回报、损失、参数数量等)至progress.txtEpochLogger:扩展Logger支持按epoch统计平均回报、最大/最小回报- 自动存档:实验参数(
config.json)与模型权重(pyt_save/)自动保存
2. 并行计算(mpi_tools.py)
- 基于MPI实现多进程数据并行
- 核心功能:
mpi_fork():创建指定数量的子进程mpiavggrads():平均各进程梯度sync_params():同步初始网络参数
3. 模型测试与可视化
test_policy.py:加载保存的模型,评估无探索策略的性能plot.py:解析日志文件,生成训练曲线(支持多算法对比)
4. 实验配置(run_utils.py)
setuploggerkwargs():生成带时间戳的日志路径ExperimentGrid:支持超参数网格搜索,批量执行实验
五、关键参数与配置
| 模块 | 核心参数 | 说明 | 默认值 |
|---|---|---|---|
| 微网环境 | NETWORK_PRICE |
公共电网电价(美分) | 19 |
| | 电池容量 | 各微网储能上限 | 500/300/400 |
| | 距离矩阵 | 微网间输电距离(km) | 3x3矩阵 |
| DDPG | gamma | 折扣因子 | 0.99 |
| | replay_size | 经验池容量 | 1e6 |
| | 学习率 | pilr=1e-3, qlr=1e-3 | 1e-3 |
| PPO | clip_ratio | 策略更新剪辑系数 | 0.2 |
| | trainpiiters | 策略训练迭代次数 | 80 |
| | 并行进程数 | MPI进程数量 | 4 |
六、代码特色与研究适配性
- 场景真实性:
- 引入输电损耗物理模型(travelloss方法)
- 基于实际负荷曲线(usage_trends.csv)和可再生能源数据建模
- 算法对比框架:
- 统一环境接口下实现三种主流算法
- 一致的评估指标(平均回报、交易成本、供需平衡率)
- 研究扩展性:
- 模块化设计便于替换算法组件
- 配置化参数支持快速调整实验方案
- 完整的日志系统支持结果可复现性
该代码库为"深度强化学习在微网P2P交易中的应用"研究提供了完整实验平台,可直接用于算法性能对比,也可通过扩展环境模型(如添加更多微网节点、复杂交易规则)支持更深入的研究探索。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 55
55 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)