
DSP原理及应用——TMS320DM6437架构与实战开发
C6000系列DSP的指令集设计融合了高性能计算与灵活性,适用于广泛的信号处理任务。理解其指令集结构是编写高效代码的第一步。本章深入剖析了C6000系列DSP的指令系统,从指令分类、常用指令到并行优化策略,再到编译器优化技巧,全面覆盖了DSP程序开发的核心知识。下一章将继续探讨TMS320DM6437核心功能模块的配置与使用,帮助开发者掌握GPIO、定时器、中断等关键外设的操作方法。

简介:《DSP原理及应用——TMS320DM6437》是一份深入讲解TMS320DM6437数字信号处理器的技术资料,内容涵盖其架构设计、指令系统、功能模块、程序开发与实际案例分析。该处理器由德州仪器推出,具备高性能、低功耗特性,适用于视频处理、图像处理和通信系统等领域。本书从第5章到第8章,详细解析了其超标量CPU架构、C6000指令集、GPIO与定时器模块、中断与流水线机制、以及应用程序开发流程。通过学习,开发者可以掌握TMS320DM6437的编程技巧,并将其应用于实际工程项目中。 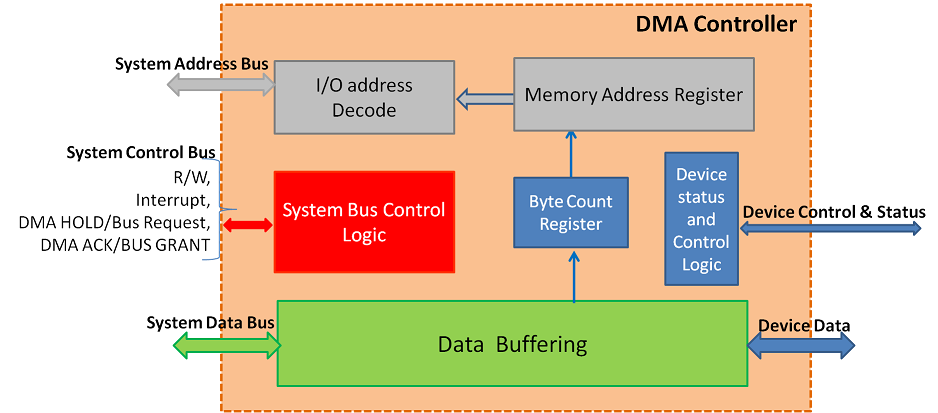
1. TMS320DM6437处理器架构详解
TMS320DM6437 是 Texas Instruments(TI)公司 C6000 系列高性能数字信号处理器(DSP)的重要成员,专为多媒体和实时信号处理应用设计。其架构融合了高性能 VLIW(超长指令字)CPU、多通道 DMA 控制器、丰富的外设接口以及高效的内存系统,能够实现复杂的算法处理和高速数据吞吐。
该处理器的核心由一个 C64x+ DSP 内核构成,支持 8 条并行指令执行,极大提升了单周期内的运算能力。内存系统采用分离式 L1/L2 高速缓存结构,L1 包括独立的程序与数据缓存,L2 作为统一缓存或 SRAM 使用,兼顾性能与灵活性。
此外,TMS320DM6437 集成了多种外设接口,如视频端口(VP)、EMAC、I²C、SPI、UART 等,适用于音视频采集、通信传输等嵌入式场景。其多通道 DMA 控制器可实现外设与内存之间的高速数据搬运,显著减轻 CPU 负担,提升系统整体效率。
2. C6000系列指令系统与优化
C6000系列DSP(数字信号处理器)以其高效的并行处理能力著称,其指令系统是实现高性能计算的核心。本章将深入解析C6000系列指令系统,涵盖指令分类、执行机制、并行优化策略以及编译器优化技巧,帮助开发者充分挖掘DSP的潜力,提升代码效率。
2.1 指令集概述
C6000系列DSP的指令集设计融合了高性能计算与灵活性,适用于广泛的信号处理任务。理解其指令集结构是编写高效代码的第一步。
2.1.1 C6000系列指令集分类
C6000系列指令集主要分为以下几类:
| 指令类别 | 功能描述 | 示例指令 |
|---|---|---|
| 数据传送指令 | 负责寄存器与内存之间的数据移动 | LDW , STW |
| 算术运算指令 | 实现加减乘除等基本数学运算 | ADD , MPY |
| 逻辑运算指令 | 位操作与逻辑判断 | AND , XOR |
| 控制流指令 | 控制程序执行顺序 | B , CALL |
| 条件执行指令 | 根据条件标志执行特定指令 | ADD .S1 A1, A2 |
| 特殊功能指令 | 操作协处理器、缓存、DMA等模块 | MV |
每类指令都有其特定的执行周期和资源占用,合理选择指令类型对性能优化至关重要。
2.1.2 指令格式与编码规则
C6000系列采用固定长度指令(32位),支持多操作并行执行(VLIW)。其基本指令格式如下:
31 27 26 24 23 19 18 16 15 0
+---------+--------+---------+--------+-----------+
| Opcode | Dest | Src1 | Src2 | Function |
+---------+--------+---------+--------+-----------+
- Opcode :操作码,决定指令类型
- Dest :目标寄存器编号
- Src1/2 :源寄存器编号
- Function :功能扩展字段,用于区分不同操作变体
例如,指令 ADD A1, A2, A3 表示将 A1 和 A2 相加,结果存入 A3,其编码会根据寄存器编号和操作码进行二进制表示。
2.2 常用指令解析
在实际开发中,开发者最常接触的是数据传送、算术运算和逻辑运算类指令。掌握这些指令的使用方式,是高效编写DSP程序的基础。
2.2.1 数据传送类指令
数据传送指令用于在寄存器和内存之间移动数据。典型指令包括:
LDW:从内存加载一个字(32位)到寄存器STW:将寄存器中的数据写入内存
LDW .D1 *A10++, A1 ; 从A10指向的地址加载数据到A1,A10自动递增
STW .D2 A2, *A11 ; 将A2的值写入A11指向的地址
逐行解析:
.D1和.D2表示指令执行在哪个数据通路(Data Path)上,C6000有多个并行数据通路。*A10++表示使用寄存器A10作为指针,读取后自动递增。- 指令后缀如
.D1、.L1表示指令执行单元,用于并行调度。
参数说明:
- A10 是地址寄存器,用于指向内存地址。
- A1 是目标寄存器,用于保存读取的数据。
- ++ 表示地址递增操作,常用于循环处理数组。
2.2.2 算术运算类指令
算术运算指令是数字信号处理的核心,包括加法、减法、乘法等。
ADD .L1 A1, A2, A3 ; A3 = A1 + A2
MPY .M1 A4, A5, A6 ; A6 = A4 * A5
SUB .L2 B1, B2, B3 ; B3 = B1 - B2
逐行解析:
ADD表示加法指令,.L1表示使用L1运算单元。MPY是乘法指令,.M1表示使用M1乘法单元。- 每个运算单元独立工作,允许并行执行。
参数说明:
- .L1/.M1/.L2 表示运算单元编号,合理分配运算资源可避免冲突。
- 使用多个运算单元时,需注意资源竞争问题。
2.2.3 逻辑运算与位操作指令
逻辑指令常用于状态判断和位操作,是控制流程的重要工具。
AND .L1 A1, A2, A3 ; A3 = A1 & A2
OR .L2 B1, B2, B3 ; B3 = B1 | B2
XOR .L1 A4, A5, A6 ; A6 = A4 ^ A5
SHL .S2 A7, 8, A8 ; A8 = A7 << 8
逐行解析:
AND执行按位与操作,常用于屏蔽位。OR用于设置位,XOR用于翻转位。SHL是左移指令,用于快速实现乘法操作。
参数说明:
- 8 表示移位位数,必须为常量或寄存器值。
- 移位操作常用于优化除法和乘法运算。
2.3 指令执行与并行优化
C6000系列DSP采用VLIW(Very Long Instruction Word)架构,支持多条指令并行执行,是其高性能的关键。
2.3.1 并行执行机制与VLIW架构
VLIW架构允许将多个独立操作打包成一条指令,从而在一个周期内完成多个操作。例如:
ADD .L1 A1, A2, A3 ; 加法操作在L1单元执行
MPY .M1 A4, A5, A6 ; 乘法操作在M1单元执行
执行流程如下图所示:
graph TD
A[指令1: ADD] --> B[执行在L1]
C[指令2: MPY] --> D[执行在M1]
B --> E[并行执行]
D --> E
说明:
- 每个执行单元(L、M、S、D)负责不同类型的操作。
- 合理安排指令到不同执行单元,可实现多指令并行执行。
2.3.2 指令调度与资源冲突避免
在并行执行中,资源冲突是影响性能的重要因素。例如,两个指令同时使用同一个寄存器或执行单元。
MPY .M1 A1, A2, A3 ; 使用M1单元
MPY .M1 A4, A5, A6 ; 再次使用M1单元,产生冲突
冲突分析:
- M1单元在同一周期只能执行一个操作。
- 第二条指令必须等待第一条完成,造成延迟。
优化策略:
- 指令重排 :将使用不同单元的指令交错执行。
- 资源分配优化 :使用
.M2单元替代.M1。 - 使用延迟槽 :插入无关指令填补等待周期。
2.4 编译器优化技巧
虽然手动优化能带来极致性能,但现代编译器如TI的C6x编译器也提供了丰富的优化选项,可显著提升代码效率。
2.4.1 编译选项对指令生成的影响
TI的C6x编译器支持多种优化等级,开发者可通过编译选项控制代码生成:
| 优化等级 | 描述 |
|---|---|
-O0 |
无优化,便于调试 |
-O1 |
基本优化,平衡调试与性能 |
-O2 |
中等优化,提升性能 |
-O3 |
高度优化,可能影响调试信息完整性 |
-O4 |
超级优化,适用于最终发布版本 |
示例编译命令:
cl6x -O3 -mv6740 -o output.obj source.c
参数说明:
- -O3 :启用高级优化。
- -mv6740 :指定目标处理器型号为TMS320DM6437。
- -o :指定输出文件。
优化内容包括:
- 自动指令并行化
- 寄存器分配优化
- 循环展开
- 内存访问优化
2.4.2 手动优化与内联函数使用
尽管编译器优化强大,但在关键路径上,手动优化仍是提升性能的有效方式。
使用内联汇编优化关键函数
inline void fast_add(int *a, int *b, int *c) {
_asm(" ADD .L1 *a++, *b++, *c++ ");
}
说明:
- inline 关键字告诉编译器尽可能将函数内联展开。
- _asm 引入汇编代码,实现更高效的加法操作。
使用C语言内建函数(Intrinsics)
TI提供C语言内建函数库(Intrinsics),可在C代码中直接调用DSP指令:
#include <ti/xdais/dm/isrc.h>
int main() {
int a = 0x1234, b = 0x5678;
int c = _mpy(a, b); // 使用MPY指令实现乘法
}
优势:
- 无需编写汇编代码,保留C语言可读性
- 可与编译器优化协同工作
- 支持类型检查和错误提示
总结
本章深入剖析了C6000系列DSP的指令系统,从指令分类、常用指令到并行优化策略,再到编译器优化技巧,全面覆盖了DSP程序开发的核心知识。下一章将继续探讨TMS320DM6437核心功能模块的配置与使用,帮助开发者掌握GPIO、定时器、中断等关键外设的操作方法。
3. 核心功能模块配置与使用
TMS320DM6437作为一款高性能数字信号处理器,其功能模块丰富、结构复杂。本章将围绕其核心外设模块的配置与使用进行深入讲解,包括GPIO接口、定时器模块、中断系统和流水线机制等关键部分。通过本章的学习,读者将掌握如何在实际项目中灵活配置和调用这些模块,为构建高效稳定的DSP系统打下坚实基础。
3.1 GPIO接口功能与配置方法
通用输入输出(GPIO)接口是嵌入式系统中最基础但最常用的硬件控制模块之一。TMS320DM6437提供了多个GPIO引脚,支持输入、输出、中断等多种功能模式,能够满足多种控制需求。
3.1.1 GPIO寄存器配置流程
TMS320DM6437的GPIO模块通过多个寄存器进行配置,包括方向寄存器(DIR)、数据输出寄存器(OUT_DATA)、数据输入寄存器(IN_DATA)、中断使能寄存器(INT_EN)等。
GPIO寄存器列表
| 寄存器名 | 功能描述 | 地址偏移 |
|---|---|---|
| DIR | 设置引脚方向:0为输入,1为输出 | 0x00 |
| OUT_DATA | 设置输出引脚的高/低电平 | 0x04 |
| IN_DATA | 读取输入引脚的状态 | 0x08 |
| INT_EN | 中断使能控制 | 0x10 |
| INT_TYPE | 设置中断类型(边沿触发/电平触发) | 0x14 |
| INT_POLARITY | 设置中断触发极性(上升沿/下降沿) | 0x18 |
| INT_STATUS | 中断状态寄存器,用于清除中断标志 | 0x1C |
配置流程说明
- 使能GPIO模块时钟 :在系统初始化阶段,需开启GPIO模块的时钟。
- 设置引脚方向 :通过写入DIR寄存器,设置引脚为输入或输出。
- 设置初始输出电平(如为输出) :通过OUT_DATA寄存器设置初始电平。
- 配置中断(如需) :设置INT_EN、INT_TYPE和INT_POLARITY寄存器以启用中断。
- 读取/写入引脚状态 :通过IN_DATA和OUT_DATA寄存器进行读写操作。
3.1.2 输入/输出模式设置与中断触发
示例代码:配置GPIO为输出并点亮LED
// 假设GPIO0的基地址为GPIO0_BASE
#define GPIO0_BASE 0x01C60000
// 定义寄存器偏移地址
#define GPIO_DIR (*(volatile unsigned int *)(GPIO0_BASE + 0x00))
#define GPIO_OUT (*(volatile unsigned int *)(GPIO0_BASE + 0x04))
void gpio_init_output() {
// 1. 设置GPIO0_7为输出模式
GPIO_DIR |= (1 << 7); // DIR寄存器第7位设为1
// 2. 设置GPIO0_7输出高电平(点亮LED)
GPIO_OUT |= (1 << 7); // OUT_DATA寄存器第7位设为1
}
代码逐行解读:
- 第6行:定义GPIO0的基地址为0x01C60000,这是TMS320DM6437的内存映射地址。
- 第9、10行:定义DIR和OUT_DATA寄存器的偏移地址。
- 第13行:函数
gpio_init_output()用于初始化GPIO0的第7位为输出。 - 第15行:
GPIO_DIR |= (1 << 7)将DIR寄存器的第7位置1,表示该引脚为输出模式。 - 第18行:
GPIO_OUT |= (1 << 7)将OUT_DATA寄存器的第7位置1,输出高电平,点亮LED。
示例代码:配置GPIO为输入并启用中断
#define GPIO_INT_EN (*(volatile unsigned int *)(GPIO0_BASE + 0x10))
#define GPIO_INT_TYPE (*(volatile unsigned int *)(GPIO0_BASE + 0x14))
#define GPIO_INT_POLARITY (*(volatile unsigned int *)(GPIO0_BASE + 0x18))
void gpio_init_input_with_irq() {
// 设置GPIO0_6为输入模式
GPIO_DIR &= ~(1 << 6); // DIR寄存器第6位清0
// 设置中断类型为边沿触发
GPIO_INT_TYPE &= ~(1 << 6); // 边沿触发
// 设置中断极性为下降沿触发
GPIO_INT_POLARITY &= ~(1 << 6); // 下降沿
// 使能GPIO0_6的中断
GPIO_INT_EN |= (1 << 6);
}
逻辑分析:
- 第6-9行:定义中断相关寄存器。
- 第12行:将GPIO0_6设置为输入模式。
- 第15行:设置为边沿触发中断。
- 第18行:设定为下降沿触发中断。
- 第21行:使能GPIO0_6的中断。
GPIO中断服务程序示例
#pragma interrupt_handler gpio_isr
void gpio_isr(void) {
// 清除中断标志
GPIO_INT_STATUS |= (1 << 6);
// 处理中断事件
// 例如:切换LED状态
GPIO_OUT ^= (1 << 7); // 翻转LED状态
}
参数说明:
GPIO_INT_STATUS |= (1 << 6):清除GPIO0_6的中断标志,防止重复中断。GPIO_OUT ^= (1 << 7):异或操作翻转LED状态。
3.2 定时器模块原理与使用
定时器是DSP系统中实现时间控制、周期任务调度的重要模块。TMS320DM6437内置多个定时器模块,支持自由运行、周期计数、看门狗等多种工作模式。
3.2.1 定时器结构与工作模式
TMS320DM6437的定时器模块通常包括以下关键组件:
- 计数器寄存器(TIMx_CNT) :用于保存当前计数值。
- 重载寄存器(TIMx_PRD) :设定计数上限或周期值。
- 控制寄存器(TIMx_CTL) :用于设置定时器模式、启动/停止等。
- 中断使能寄存器(TIMx_INT_EN) :控制是否启用中断。
- 时钟分频寄存器(TIMx_CLKDIV) :设置时钟分频系数。
工作模式分类
| 模式名称 | 描述说明 |
|---|---|
| 自由运行模式 | 计数器从0开始递增,直到溢出 |
| 周期计数模式 | 计数器从0到PRD循环计数,常用于周期性任务 |
| 单次计数模式 | 计数一次后停止,适用于一次性定时任务 |
| 看门狗模式 | 用于系统复位保护,防止程序跑飞 |
3.2.2 定时器中断与周期任务调度
示例代码:配置定时器产生周期中断
#define TIMER0_BASE 0x01C20000
#define TIMx_CTL (*(volatile unsigned int *)(TIMER0_BASE + 0x00))
#define TIMx_PRD (*(volatile unsigned int *)(TIMER0_BASE + 0x04))
#define TIMx_CNT (*(volatile unsigned int *)(TIMER0_BASE + 0x08))
#define TIMx_INT_EN (*(volatile unsigned int *)(TIMER0_BASE + 0x10))
void timer_init_periodic(int period_us) {
// 假设主频为600MHz,预分频为100,则每个计数为0.1us
int reload_value = period_us * 10; // 转换为计数值
// 设置重载值
TIMx_PRD = reload_value;
// 设置周期模式
TIMx_CTL |= (1 << 1); // BIT1为模式选择位
// 启动定时器
TIMx_CTL |= (1 << 0); // BIT0为启动位
// 使能中断
TIMx_INT_EN |= (1 << 0); // BIT0为中断使能位
}
逻辑分析:
- 第10行:计算重载值,假设每个计数为0.1μs,周期为100μs则为1000个计数。
- 第13行:设置定时器为周期模式。
- 第16行:启动定时器。
- 第19行:启用中断,定时器溢出时将触发中断。
定时器中断服务程序
#pragma interrupt_handler timer0_isr
void timer0_isr(void) {
// 执行周期任务
GPIO_OUT ^= (1 << 7); // 翻转LED状态,表示任务执行
}
参数说明:
GPIO_OUT ^= (1 << 7):每100μs翻转一次LED状态,实现闪烁效果。
3.2.3 定时器配置流程图(Mermaid格式)
graph TD
A[初始化定时器模块] --> B[设置预分频]
B --> C[设置周期值]
C --> D[选择工作模式]
D --> E[启动定时器]
E --> F{中断是否启用?}
F -->|是| G[注册中断服务程序]
F -->|否| H[仅使用轮询方式]
3.3 中断系统设计与处理机制
中断机制是DSP系统中实现异步事件响应的重要手段。TMS320DM6437支持多个中断源,并具备中断优先级管理和嵌套中断处理能力。
3.3.1 中断源分类与优先级设置
TMS320DM6437的中断系统包括以下几类中断源:
- 内部中断 :如定时器、DMA、串口等外设中断。
- 外部中断 :来自外部引脚的中断请求。
- 软件中断 :由程序触发的中断。
中断优先级寄存器(INTC_IPR)
| 位段 | 描述 |
|---|---|
| [31:0] | 每位对应一个中断源优先级,值越小优先级越高 |
设置中断优先级示例代码
#define INTC_IPR (*(volatile unsigned int *)0x01A40000)
void set_interrupt_priority(int irq_num, int priority) {
unsigned int mask = 0x0F << ((irq_num % 8) * 4);
unsigned int val = (priority & 0x0F) << ((irq_num % 8) * 4);
INTC_IPR &= ~mask;
INTC_IPR |= val;
}
代码分析:
- 第4行:定义中断优先级寄存器地址。
- 第6行:函数
set_interrupt_priority用于设置指定中断源的优先级。 - 第7-8行:构造屏蔽和设置值,更新INTC_IPR寄存器。
3.3.2 中断服务程序编写与嵌套处理
TMS320DM6437支持中断嵌套,即高优先级中断可以打断低优先级中断的执行。
中断嵌套流程图(Mermaid)
graph LR
A[主程序运行] --> B[低优先级中断触发]
B --> C[执行低优先级ISR]
C --> D[高优先级中断触发]
D --> E[暂停低级ISR,执行高级ISR]
E --> F[恢复低级ISR执行]
F --> G[返回主程序]
示例代码:中断服务程序嵌套处理
volatile int flag_high = 0;
volatile int flag_low = 0;
#pragma interrupt_handler high_isr
void high_isr(void) {
flag_high = 1; // 标记高优先级中断发生
}
#pragma interrupt_handler low_isr
void low_isr(void) {
flag_low = 1; // 标记低优先级中断发生
// 模拟长时间处理
for(int i=0; i<1000; i++);
}
逻辑分析:
- 当
low_isr正在执行时,若发生高优先级中断,系统会暂停low_isr,先执行high_isr。 - 执行完毕后,继续执行
low_isr剩余部分。
3.4 流水线机制提升执行效率
TMS320DM6437采用多级流水线架构,以提高指令执行效率。了解其流水线结构和优化技巧,有助于开发人员编写更高效的DSP程序。
3.4.1 流水线结构原理与阶段划分
C6000系列DSP的流水线通常分为以下阶段:
| 阶段 | 功能描述 |
|---|---|
| PG(Program Generate) | 指令获取地址 |
| PS(Program Setup) | 地址计算与指令预取 |
| PW(Program Wait) | 等待指令加载完成 |
| EX(Execute) | 执行指令,访问寄存器或内存 |
| WR(Write Back) | 写回运算结果 |
3.4.2 流水线冲突与延迟槽技术
由于流水线的并行特性,可能会出现资源冲突或数据依赖问题。TMS320DM6437采用 延迟槽(Delay Slot) 技术来优化这类问题。
示例代码:延迟槽应用
ADD A1, A2, A3 ; A1 = A2 + A3
NOP ; 延迟槽,等待上一条指令完成
LDW *A3, B1 ; 读取A3指向的数据到B1
解释:
ADD指令在EX阶段完成运算。NOP作为延迟槽,防止后续指令在结果未写回前使用A3。LDW使用A3地址时,确保其值已更新。
流水线冲突示意图(Mermaid)
sequenceDiagram
participant CPU
CPU->>CPU: ADD A1, A2, A3
CPU->>CPU: LDW *A3, B1 (冲突:A3尚未写回)
Note right of CPU: 数据依赖冲突
CPU->>CPU: NOP
CPU->>CPU: LDW *A3, B1 (安全执行)
通过合理插入NOP或其它无关指令,可以有效避免流水线冲突,提升执行效率。
本章总结
本章详细讲解了TMS320DM6437中几个核心功能模块的配置与使用方法,包括GPIO接口、定时器模块、中断系统和流水线机制。通过示例代码、寄存器配置流程、流程图和表格,帮助读者深入理解这些模块的工作原理与应用场景。下一章将继续深入DSP程序开发流程与调试优化技巧,进一步提升开发效率与系统性能。
4. DSP程序开发流程与调试优化
在数字信号处理器(DSP)的实际开发过程中,程序开发流程的规范性与调试优化的高效性直接决定了系统的性能表现与开发效率。TMS320DM6437作为TI C6000系列中面向多媒体处理的高性能定点DSP,其开发流程涵盖了从开发环境搭建、代码编写、编译链接到调试与性能优化的完整生命周期。本章将系统地讲解如何使用Code Composer Studio(CCS)进行工程构建与编译配置,深入探讨调试器的使用技巧与性能优化方法,重点分析单周期乘法累加指令(MAC)在关键算法中的应用,并提出针对内存访问、缓存管理、循环展开和数据对齐的优化策略,帮助开发者实现高效的DSP程序。
4.1 程序开发流程与编译器使用
TMS320DM6437的开发主要依赖于TI提供的集成开发环境——Code Composer Studio(CCS)。它集成了编辑器、编译器、调试器和性能分析工具,是构建和调试DSP程序的核心平台。
4.1.1 Code Composer Studio开发环境搭建
搭建CCS开发环境主要包括以下几个步骤:
-
安装CCS版本
推荐使用CCS v10或以上版本,兼容TMS320DM6437的开发套件(如DM6437 EVM板)。从TI官网下载并安装CCS。 -
安装编译器工具链
在安装过程中选择TI的C6000编译器(CGTools)安装包,确保包含支持TMS320DM6437的编译器版本。 -
配置目标板连接
使用XDS100v2或XDS200仿真器连接DM6437目标板,并在CCS中添加目标配置文件(*.ccxml)。 -
验证连接与设备识别
打开CCS,连接目标设备,确保CCS能够正确识别TMS320DM6437芯片及其内存映射。
// 示例:简单的LED控制程序,用于验证环境搭建是否成功
#include <c6x.h>
#define LED_REG (*(volatile unsigned int *)0x01C25000) // 假设LED寄存器地址
int main() {
LED_REG = 0xFF; // 点亮所有LED
while (1); // 停留在这里
}
代码解析:
- #include <c6x.h> :包含C6000系列DSP的寄存器定义头文件。
- LED_REG :指向一个假设的LED控制寄存器地址。
- main() 函数中写入0xFF点亮LED,并通过死循环保持程序运行。
- 该程序可用于验证开发环境是否能够成功编译、下载并运行到目标设备。
4.1.2 工程创建、编译与链接配置
在CCS中创建工程的基本流程如下:
-
创建新工程
- 选择“File → New → CCS Project”
- 输入工程名称,选择目标设备为“TMS320DM6437”
- 指定编译器为“TI C6000 Code Generation Tools” -
添加源文件
- 添加C源文件(如main.c)、头文件、启动文件(如boot.asm)和链接命令文件(*.cmd) -
配置链接脚本
链接脚本(.cmd文件)定义了内存段的映射关系,是DSP程序运行的关键配置文件。例如:
MEMORY
{
L2SRAM: o = 0x11800000, l = 0x00040000
DDR2: o = 0x80000000, l = 0x02000000
}
SECTIONS
{
.text : > L2SRAM
.stack : > L2SRAM
.bss : > L2SRAM
.data : > DDR2
}
参数说明:
- L2SRAM :用于存放程序代码和栈区。
- DDR2 :用于存储数据段,适合大量数据存储。
- .text :代码段,通常映射到高速缓存或内部SRAM。
- .data :初始化数据段,常用于外部DDR2内存。
- 编译与下载
- 点击Build按钮编译工程。
- 使用Debug按钮将程序下载到目标设备中。
4.2 调试工具与代码优化技巧
调试是DSP程序开发的关键环节,而性能优化则是提升系统效率的核心手段。
4.2.1 CCS调试器使用与断点设置
CCS内置的调试器提供了丰富的功能,包括:
- 源码级调试 :支持C语言级的单步执行、断点设置和变量观察。
- 寄存器查看 :可查看和修改CPU寄存器、外设寄存器的值。
- 内存窗口 :查看和修改内存内容,适合调试数据结构或DMA传输。
断点设置技巧:
- 软件断点 :在源代码行设置,适用于代码调试。
- 硬件断点 :在特定地址设置,适用于中断处理或DMA触发调试。
- 条件断点 :仅当某个条件满足时触发,适合调试复杂逻辑。
// 示例:使用断点调试DMA传输
void dma_transfer() {
// 启动DMA传输
DMA_start(0); // 设置断点于此,观察DMA状态
while(!DMA_isDone(0)); // 查看循环退出条件
}
逻辑分析:
- 在 DMA_start() 函数调用后设置断点,观察DMA是否成功启动。
- 在 while 循环中,可以查看DMA完成标志位是否被正确设置。
4.2.2 性能分析与代码热点识别
TI提供了Profile功能用于性能分析:
-
启用Profile
在CCS中打开“Profile”视图,选择“Start CPU Cycle Counting”以启用性能计数器。 -
识别热点函数
运行程序后,Profile视图将显示各函数的执行时间占比,帮助识别耗时函数。 -
优化建议
对耗时较高的函数,可考虑使用内联汇编、循环展开、数据对齐等手段优化。
示例:性能分析结果展示
| 函数名 | 调用次数 | 执行时间(cycles) | 占比(%) |
|---|---|---|---|
| filter_kernel | 1000 | 120000 | 45 |
| fft | 200 | 90000 | 34 |
| main | 1 | 10000 | 4 |
说明:
- filter_kernel 和 fft 是两个热点函数,合计占比79%,应优先优化。
4.3 单周期乘法累加指令应用
TMS320DM6437支持单周期MAC(Multiply-Accumulate)指令,是实现高效滤波和FFT运算的核心指令。
4.3.1 MAC指令在滤波算法中的应用
在FIR滤波器中,每个输出点都需要进行一系列乘加操作。使用MAC指令可以显著提高性能。
int filter(int *x, int *h, int N) {
int sum = 0;
for(int i = 0; i < N; i++) {
sum += x[i] * h[i]; // 可被优化为MAC指令
}
return sum;
}
优化后(使用内联汇编):
int filter_optimized(int *x, int *h, int N) {
int sum = 0;
asm(" .reg x0, h0, acc\n"
" .loop\n"
" ldw *x++, x0\n"
" ldw *h++, h0\n"
" mpy x0, h0, acc\n"
" add acc, sum\n"
" .endloop");
return sum;
}
逻辑分析:
- mpy :执行乘法操作。
- add :将结果累加到sum。
- 整个循环在单周期内完成,效率大幅提升。
4.3.2 优化卷积与FFT计算性能
在图像处理和通信系统中,卷积与FFT是常见运算。通过使用MAC指令与向量处理,可以实现高效并行计算。
// FFT计算核心循环(伪代码)
for (k = 0; k < N; k++) {
for (m = 0; m < logN; m++) {
twiddle = W[m]; // 旋转因子
temp = x[m] * twiddle;
x[m] = x[m] + temp;
x[m + N/2] = x[m] - temp;
}
}
优化建议:
- 将内层循环用MAC指令实现。
- 利用VLIW并行执行多个MAC指令。
- 使用TI提供的FFT库函数(如 rfft() )以提升性能。
4.4 优化策略与性能提升
在DSP开发中,优化是提升性能的关键。以下介绍几种常用的优化策略。
4.4.1 内存访问优化与缓存管理
TMS320DM6437具有多级存储结构,合理管理内存访问对性能影响巨大。
#pragma DATA_SECTION(buffer, ".ddr2") // 将buffer分配到DDR2内存
int buffer[1024];
说明:
- 使用 #pragma DATA_SECTION 将大数组分配到DDR2,避免占用L2缓存。
- 频繁访问的数据应尽量放在L2SRAM中以提高访问速度。
内存访问优化技巧:
- 使用预取指令( ldp )提前加载数据。
- 数据结构尽量紧凑,减少cache miss。
- 对于DMA传输,使用乒乓缓冲机制提高吞吐率。
4.4.2 循环展开与数据对齐技巧
循环展开(Loop Unrolling)是一种常见的优化技术,减少循环控制开销,提高指令并行性。
// 原始循环
for(i = 0; i < N; i++) {
a[i] = b[i] + c[i];
}
// 展开后的循环
for(i = 0; i < N; i += 4) {
a[i] = b[i] + c[i];
a[i+1] = b[i+1] + c[i+1];
a[i+2] = b[i+2] + c[i+2];
a[i+3] = b[i+3] + c[i+3];
}
说明:
- 循环展开减少了循环次数,提升了并行执行效率。
- 适合在VLIW架构下同时执行多个加法指令。
数据对齐优化:
- 使用 #pragma DATA_ALIGN 对齐数据结构,提高访问效率。
- 例如: #pragma DATA_ALIGN(arr, 8) 将数组arr按8字节对齐。
graph TD
A[开始优化] --> B[内存访问优化]
A --> C[循环展开]
A --> D[数据对齐]
B --> E[减少Cache Miss]
C --> F[提升并行执行效率]
D --> G[提高访问吞吐率]
总结:
- 合理的内存管理与优化策略能显著提升TMS320DM6437的性能。
- 开发者应结合具体应用场景,灵活使用上述优化手段。
5. DSP在典型应用中的实战分析
5.1 DSP在图像与视频处理中的应用
TMS320DM6437因其强大的数据处理能力,被广泛应用于图像与视频处理领域。其内部的高速DMA通道、多级缓存结构以及并行计算单元,使其非常适合进行图像采集、滤波、边缘检测等任务。
5.1.1 图像采集与显示流程
图像采集通常通过外部视频解码器(如TVP5146)接入,TMS320DM6437通过VPFE(Video Port Front End)接口获取原始图像数据。以下是一个图像采集流程的伪代码:
// 初始化视频端口
void Init_Video_Port() {
// 配置VPFE寄存器,设置输入格式为YUV422
VPFE_CTRL = 0x00000001; // 启动VPFE
VPFE_FMT = 0x00000003; // 设置为YUV422格式
}
// 启动DMA传输
void Start_DMA_Transfer() {
DMA_Setup(VIDEO_BUFFER_ADDR, DMA_MODE_CIRCULAR, FRAME_SIZE);
DMA_Start();
}
// 主函数调用
int main() {
Init_Video_Port();
Start_DMA_Transfer();
while(1) {
// 等待帧中断
WaitForFrameInterrupt();
// 图像处理逻辑
Process_Frame();
}
}
参数说明:
-VIDEO_BUFFER_ADDR:图像帧缓冲区起始地址
-DMA_MODE_CIRCULAR:DMA环形缓冲模式,适用于连续视频流
-FRAME_SIZE:单帧图像大小(单位:字节)
该流程通过中断方式控制图像采集的节奏,图像采集完成后进入图像处理阶段。
5.1.2 实时视频滤波与边缘检测算法实现
图像处理阶段可以实现均值滤波、高斯滤波或边缘检测等算法。以下是一个使用Sobel算子实现边缘检测的C语言伪代码:
void Sobel_Edge_Detection(unsigned char *src, unsigned char *dst, int width, int height) {
int Gx, Gy, i, j;
for(i = 1; i < height - 1; i++) {
for(j = 1; j < width - 1; j++) {
Gx = -src[(i-1)*width + (j-1)] + src[(i-1)*width + (j+1)]
-2*src[i*width + (j-1)] + 2*src[i*width + (j+1)]
-src[(i+1)*width + (j-1)] + src[(i+1)*width + (j+1)];
Gy = -src[(i-1)*width + (j-1)] -2*src[(i-1)*width + j] - src[(i-1)*width + (j+1)]
+ src[(i+1)*width + (j-1)] +2*src[(i+1)*width + j] + src[(i+1)*width + (j+1)];
dst[i*width + j] = (abs(Gx) + abs(Gy)) > 255 ? 255 : (abs(Gx) + abs(Gy));
}
}
}
说明:
-src是输入的灰度图像指针
-dst是输出的边缘检测图像指针
- 使用Sobel算子进行梯度计算,增强边缘信息
- 该函数可进一步使用C64x+的并行指令进行优化,如_dotp2指令加速卷积运算
此函数在TMS320DM6437中运行时,可以利用其VLIW架构并行执行多个算术运算,从而实现高效的边缘检测。
5.2 DSP在通信系统中的实战案例
TMS320DM6437在通信系统中也扮演着重要角色,尤其在QAM调制解调和OFDM信号处理方面具有显著优势。
5.2.1 QAM调制解调系统设计
QAM(正交幅度调制)是数字通信中常用的调制方式。TMS320DM6437可以实现16-QAM、64-QAM甚至更高阶的调制解调系统。
以下是一个简化的16-QAM调制过程:
// 16-QAM映射表
const short qam16_table[16][2] = {
{-3, -3}, {-3, -1}, {-3, 3}, {-3, 1},
{-1, -3}, {-1, -1}, {-1, 3}, {-1, 1},
{ 3, -3}, { 3, -1}, { 3, 3}, { 3, 1},
{ 1, -3}, { 1, -1}, { 1, 3}, { 1, 1}
};
// 调制函数
void QAM16_Modulate(unsigned char *bits, short *out, int len) {
for(int i = 0; i < len; i += 4) {
int index = (bits[i] << 3) | (bits[i+1] << 2) | (bits[i+2] << 1) | bits[i+3];
out[i/4*2] = qam16_table[index][0];
out[i/4*2+1] = qam16_table[index][1];
}
}
说明:
- 该函数将4bit数据映射为16-QAM信号的I/Q分量
- 可通过C64x+的向量指令优化映射过程,如使用_pack2、_unpackl4等指令加速处理
5.2.2 OFDM信号处理中的DSP实现
OFDM(正交频分复用)技术广泛应用于Wi-Fi、LTE等领域。TMS320DM6437可高效实现FFT/IFFT、信道估计与均衡等关键步骤。
以下是一个基于C67x DSP库的FFT处理流程:
#include <math.h>
#include <c6x.h>
#include <ti/dsplib/dsplib.h>
#define FFT_SIZE 256
void OFDM_Process(short *input, short *output) {
static short fft_buffer[FFT_SIZE * 2]; // 实部和虚部交替存储
static short twiddle[FFT_SIZE * 2]; // 旋转因子表
// 初始化旋转因子
DSPF_sp_cfftr2_dit(twiddle, FFT_SIZE);
// 执行FFT
memcpy(fft_buffer, input, FFT_SIZE * 2 * sizeof(short));
DSPF_sp_cfftr2_dit(fft_buffer, twiddle, FFT_SIZE);
// 输出结果
memcpy(output, fft_buffer, FFT_SIZE * 2 * sizeof(short));
}
说明:
- 使用TI官方DSPLIB库函数DSPF_sp_cfftr2_dit进行FFT运算
- 该函数适用于OFDM系统中的频域转换处理
- 可进一步使用DMA传输和流水线技术提升性能
5.3 综合项目案例分析
5.3.1 音频编码器实现(如G.729)
G.729是一种广泛应用于VoIP的语音压缩编码标准。TMS320DM6437凭借其强大的定点与浮点运算能力,非常适合实现G.729编码器。
以下是G.729编码流程的简化版本:
graph TD
A[输入语音信号] --> B[预处理与加窗]
B --> C[线性预测分析]
C --> D[码本搜索与激励信号生成]
D --> E[合成与误差计算]
E --> F[输出编码比特流]
说明:
- 每个模块均可通过C64x+的并行指令进行优化
- 关键函数如LPC分析、码本搜索可使用TI的语音编解码库(如G.729库)
5.3.2 实时图像压缩与传输系统设计
该系统包括图像采集、JPEG压缩、网络传输三个主要模块。TMS320DM6437负责JPEG压缩部分,压缩流程如下:
graph LR
A[原始图像] --> B[DCT变换]
B --> C[量化]
C --> D[熵编码]
D --> E[输出JPEG码流]
说明:
- DCT变换可使用C64x+的MAC指令加速
- 量化和熵编码阶段可使用循环展开和数据对齐优化
5.4 应用系统调试与问题定位
5.4.1 硬件与软件协同调试方法
使用TI的Code Composer Studio(CCS)进行调试时,可以结合硬件断点、数据监视窗口和实时分析工具(如RTA)进行联合调试。以下是一个典型的调试流程:
- 连接硬件设备 :使用JTAG或USB仿真器连接TMS320DM6437目标板
- 加载工程并编译 :在CCS中导入工程并编译生成.out文件
- 设置断点 :在关键函数入口或数据处理部分设置断点
- 查看寄存器与内存 :使用Memory Browser查看内存内容,Register窗口查看寄存器状态
- 实时分析 :使用RTA插件分析系统性能瓶颈
5.4.2 性能瓶颈分析与系统优化建议
常见性能瓶颈包括:
- 内存带宽限制 :可通过数据对齐、DMA预取优化
- 指令流水线阻塞 :优化指令顺序,减少跳转指令
- 资源冲突 :合理分配寄存器和功能单元
以下是一些优化建议:
- 使用 #pragma UNROLL 进行循环展开
- 使用 _nassert 宏帮助编译器优化
- 使用DMA异步传输减少CPU负载
- 合理使用L2缓存,减少外部总线访问
示例:使用循环展开优化图像处理函数
#pragma UNROLL(4) // 编译器展开4次循环
for(i = 0; i < width; i += 4) {
dst[i] = src[i] * 2;
dst[i+1] = src[i+1] * 2;
dst[i+2] = src[i+2] * 2;
dst[i+3] = src[i+3] * 2;
}
说明:
- 使用#pragma UNROLL可以减少循环控制开销
- 适合处理图像、音频等数据量大的场景
简介:《DSP原理及应用——TMS320DM6437》是一份深入讲解TMS320DM6437数字信号处理器的技术资料,内容涵盖其架构设计、指令系统、功能模块、程序开发与实际案例分析。该处理器由德州仪器推出,具备高性能、低功耗特性,适用于视频处理、图像处理和通信系统等领域。本书从第5章到第8章,详细解析了其超标量CPU架构、C6000指令集、GPIO与定时器模块、中断与流水线机制、以及应用程序开发流程。通过学习,开发者可以掌握TMS320DM6437的编程技巧,并将其应用于实际工程项目中。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)