
大模型基础知识:分布式训练架构详解!大模型学习
本文详细介绍了大模型分布式训练的硬件组成与架构设计。首先阐述了高性能计算集群的硬件组成和网络拓扑,重点分析了NVLink/NVSwitch技术解决GPU通信瓶颈。随后深入探讨了参数服务器架构及其同步/异步训练模式的优缺点,并详细讲解了去中心化架构中的集合通信技术和通信库选择。最后以PyTorch为例展示了分布式训练的实现方法,为读者提供了全面的大模型分布式训练知识体系。
简介
本文详细介绍了大模型分布式训练的硬件组成与架构设计。首先阐述了高性能计算集群的硬件组成和网络拓扑,重点分析了NVLink/NVSwitch技术解决GPU通信瓶颈。随后深入探讨了参数服务器架构及其同步/异步训练模式的优缺点,并详细讲解了去中心化架构中的集合通信技术和通信库选择。最后以PyTorch为例展示了分布式训练的实现方法,为读者提供了全面的大模型分布式训练知识体系。
分布式训练需要使用由多台服务器组成的计算集群(Computing Cluster),而集群的架构也需要根据分布式系统、大语言模型结构、优化算法等综合因素进行设计。分布式训练集群属于高性能计算集群(High Performance Computing Cluster,HPC),其目标是提供海量的计算能力。在由高速网络组成的高性能计算上构建分布式训练系统,主要有两种常见架构:参数服务器架构和去中心化架构。
本文介绍高性能计算集群的典型硬件组成,并在此基础上介绍分布式训练系统所采用的参数服务器架构和去中心化架构。
1、高性能计算集群
在大规模人工智能模型的训练过程中,往往需要借助高性能计算集群(HPC 集群)。这类集群就像一座超级工厂,里面有成百上千台服务器,每台服务器都装有多个计算加速设备(通常是 GPU),数量一般在 2 到 16 个之间。
这些服务器被整齐地放在一个个机柜(Rack)里。机柜里的服务器会通过架顶交换机(Top of Rack Switch,简称 ToR)连到网络上。如果机柜数量继续增加,就需要在不同的 ToR 交换机之间加一层骨干交换机(Spine Switch),形成类似树状的网络结构(多层树拓扑)。不过在这种结构下,机柜之间的数据交流(跨机柜通信)常常会成为瓶颈。
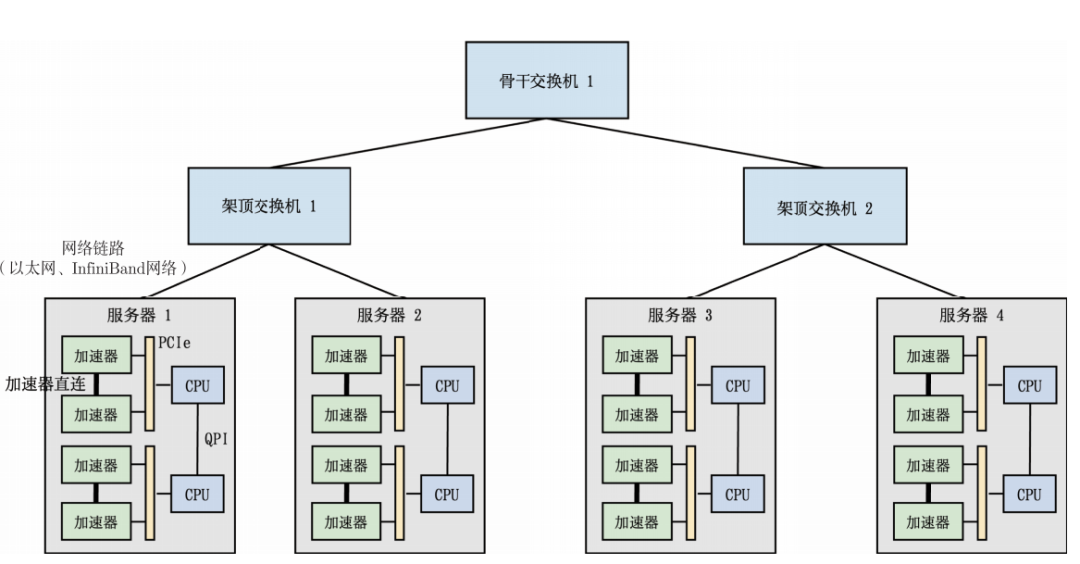
举个例子:GPT-3 这样一个拥有 1750 亿参数的大模型,如果参数都用 32 位浮点数存储,那么在一次训练迭代中,每个模型副本会产生大约 700GB 的梯度数据。如果用 1024 张 GPU 组成一个集群,跑 128 个模型副本,那么光是一次迭代就需要传输接近 90TB 的数据!如此庞大的数据量,对网络通信来说就是一次大堵车。
为了缓解这个问题,研究人员常常使用“胖树”(Fat-Tree)网络拓扑来提升带宽利用率,并且在硬件层面会采用 InfiniBand(IB)这种高速互联技术。单条 InfiniBand 链路的带宽可以达到 200Gbps 或 400Gbps。而像 NVIDIA 的 DGX 服务器,单机网络带宽就能提供 1.6Tbps,HGX 服务器甚至可以达到 3.2Tbps。
除了服务器之间的通信,服务器内部 GPU 之间的通信速度也很关键。如果 GPU 之间只是通过 PCIe 总线互联,带宽会受到很大限制。比如最新的 PCIe 5.0,带宽也只有 128GB/s,而相比之下,NVIDIA H100 GPU 使用的 HBM 显存带宽能达到 3350GB/s。为了解决内部通信瓶颈,NVIDIA 引入了 NVLink 和 NVSwitch 技术。
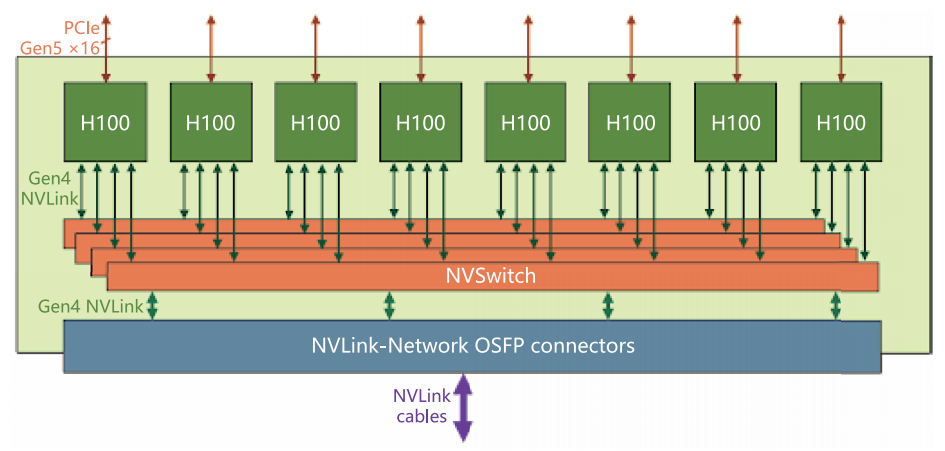
以 NVIDIA 的 HGX H100 8-GPU 服务器为例:每张 H100 GPU 都通过多个 NVLink 端口连接到 4 个 NVSwitch 上。NVSwitch 是一种无阻塞交换机,可以把所有 8 张 GPU 全部互联起来。这样一来,无论哪两张 GPU 之间通信,都能实现高达 900GB/s 的双向速度。换句话说,在服务器内部,GPU 之间的数据传输几乎没有障碍。
2 参数服务器架构
在分布式训练中,有一种常见的架构叫做 参数服务器(Parameter Server,简称 PS)架构。顾名思义,它把整个集群的服务器分成两类角色:
- 训练服务器(Worker):主要负责“算”,也就是执行模型的训练任务,需要强大的计算能力。
- 参数服务器(PS):主要负责“管”,即存储和更新模型参数,需要充足的内存和高速的网络通信能力。
可以把它想象成一个“工厂流水线”:
- 工人(训练服务器)负责干活(算梯度),
- 仓库管理员(参数服务器)负责统一收集结果、更新库存(更新参数)。
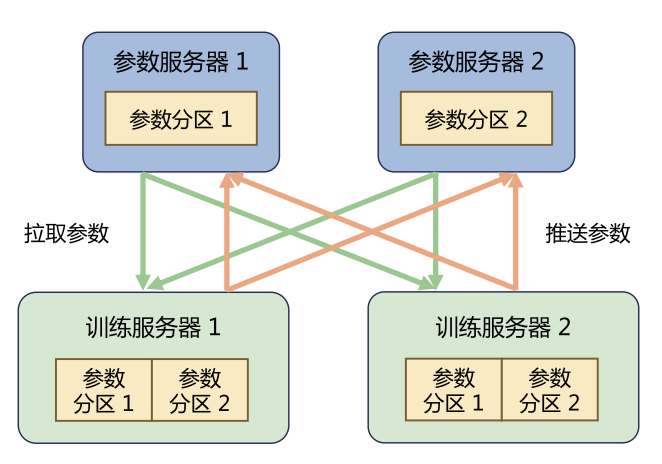
比如,有一个模型被分成两个部分(参数分区),那么就会用两个参数服务器分别管理这两部分参数。在训练过程中,每个训练服务器都会加载完整的模型,然后根据分配到的数据切片(Dataset Shard)做计算,得到的梯度会推送给对应的参数服务器。
接下来,参数服务器会做两件事:
- 把不同训练服务器上传的梯度进行处理(比如求平均),
- 更新模型参数,再把最新的参数发回给训练服务器。
这样,训练就可以一轮一轮地继续进行下去。
在这种架构下,分布式训练有两种常见模式:
- 同步训练
- 所有训练服务器算完一个小批次后,把梯度发给参数服务器。
- 参数服务器必须等所有梯度都到齐,再统一更新参数。
- 好处:结果更稳定,训练效果更好。
- 坏处:如果有一个训练服务器慢了(俗称“拖后腿”),大家都得等它,整体速度会变慢。
- 异步训练
- 每个训练服务器算完一个小批次,就直接把梯度发给参数服务器。
- 参数服务器不会等待所有服务器的结果,而是立刻用已有的梯度更新参数。
- 好处:训练速度快,没有等待机制。
- 坏处:因为大家“各算各的”,参数更新不够同步,训练过程可能会有波动。
总结来说,同步训练更稳,异步训练更快,实际用哪种方式,需要根据任务的规模和目标来决定。
3 去中心化架构
在分布式训练里,除了参数服务器这种“中心化”的架构,还有另一种思路:去中心化(Decentralized Network)架构。顾名思义,这种架构没有单一的中央服务器来协调一切,而是让所有节点直接互相通信、协作。
这样做的好处很明显:
- 避免单点瓶颈: 没有一个“管家”被所有人依赖。
- 更好扩展性 : 节点数量增多时,系统依旧能高效运行。
- 通信更高效 : 节点之间可以一边训练一边通信,减少等待时间和通信墙的影响。
在训练过程中,各个节点需要周期性地交换参数和梯度。这里用到的就是 集合通信(Collective Communication,CC) 技术。集合通信提供了一系列“通信原语”,可以理解为多台计算机协同工作时的“交流方式”。常见的包括:
-
Broadcast(广播)
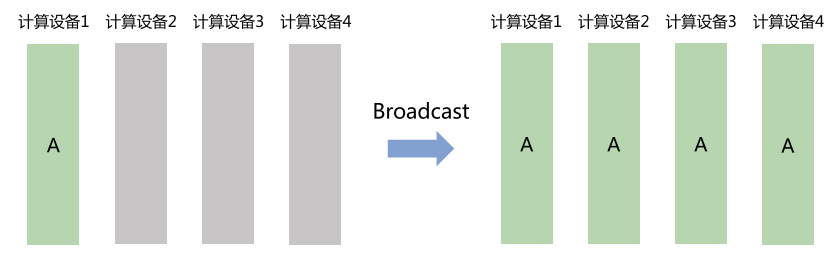
- 一台节点把自己的数据发给所有节点。
- 常用于模型参数的初始化。
- 类比:老师发讲义,每个学生都能拿到一份。
-
Scatter(分发)
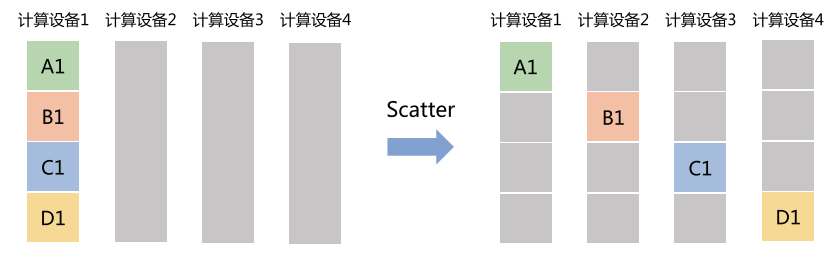
- 主节点把数据切分开来,分给不同节点。
- 类比:老师把大试卷分割成几份,分发给小组去做。
-
Reduce(归约)
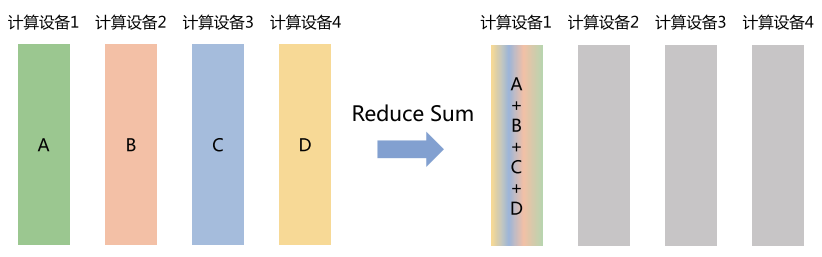
- 把各个节点的结果聚合在一起,比如求和、取最大值。
- 类比:每个小组交答案,老师统一计算平均分。
-
All Reduce(全归约)
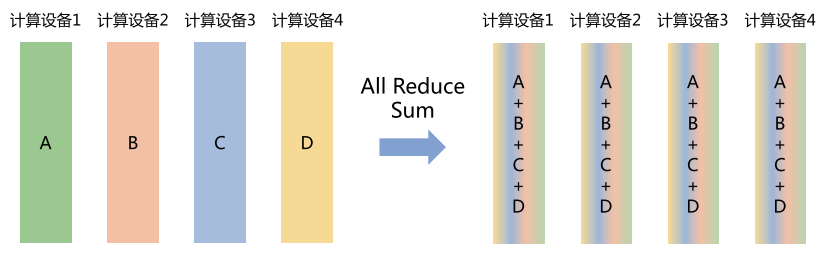
- 所有节点一起归约,并且每个节点都能拿到结果。
- 可以看作 “Reduce + Broadcast”。
- 类比:老师算出平均分后,把结果再告诉所有学生。
-
Gather(收集)
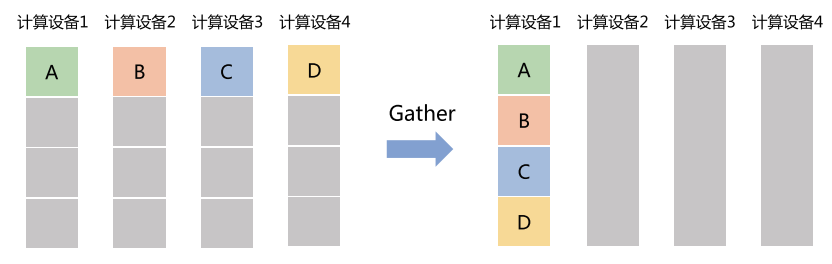
- 把所有节点的数据集中到一个节点上。
- 类比:小组作业收上来交给班长。
-
All Gather(全收集)
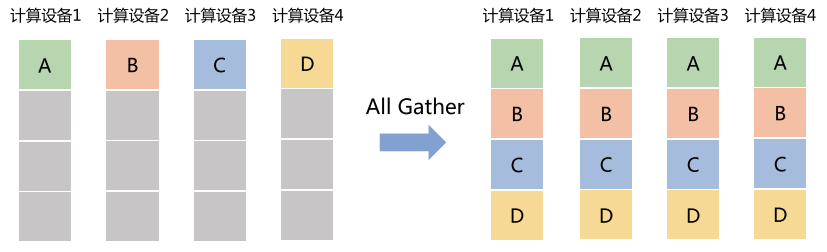
- 每个节点都收集到所有节点的数据。
- 类比:每个学生都拿到全班同学的作业副本。
-
Reduce Scatter(归约分发)
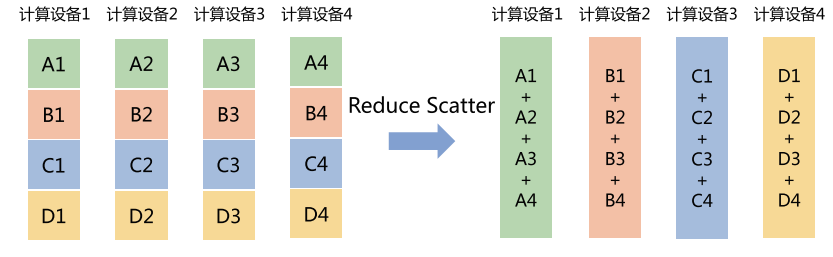
- 节点先把数据切分,分发给不同节点,然后在每个节点上进行归约运算。
- 类比:每个小组先做一部分题,再把结果交换并整合。
-
All to All(全对全)
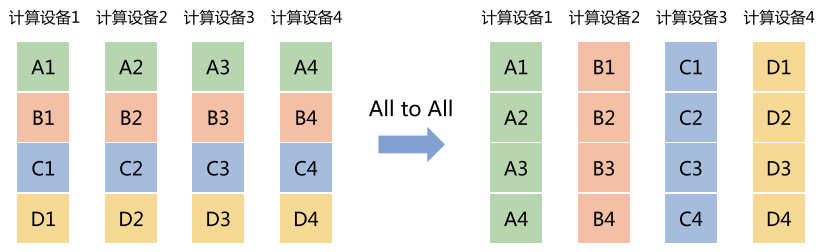
- 每个节点把数据切分后,分别发给其他所有节点。
- 类比:每个学生把自己笔记分章节抄一份,发给全班同学。
这些通信方式保证了模型在去中心化架构下依然能同步训练。
在实现层面,深度学习框架(比如 PyTorch)并不会直接操控网络硬件,而是依赖 通信库(Communication Library)。常用的有:
- MPI(Message Passing Interface):经典的并行计算通信库,主要用于 CPU 集群。
- GLOO:由 Facebook 开发,和 MPI 类似,支持点对点和集合通信,可以在 CPU 和 GPU 上用。
- NCCL(NVIDIA Collective Communications Library):NVIDIA 专为 GPU 设计的高性能通信库,和自家硬件深度优化,在 GPU 集群中表现最好。
一般来说:
- CPU 集群 → 使用 MPI 或 GLOO;
- GPU 集群 → 优先使用 NCCL。
这样,才能最大化地发挥硬件优势,让分布式训练既快又高效。
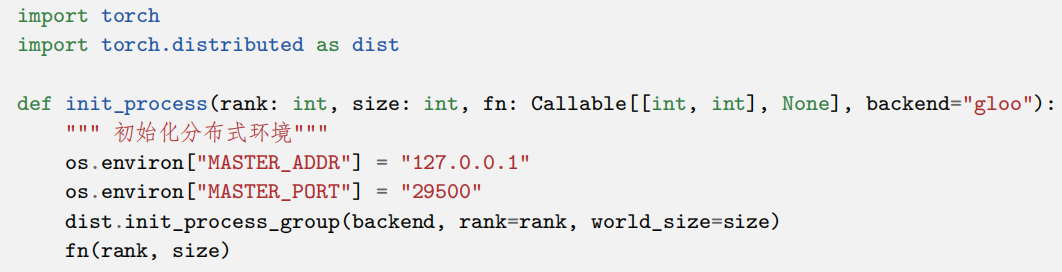
以 PyTorch 为例,介绍如何使用上述通信原语完成多计算设备间通信。先使用“torch.distributed”初始化分布式环境:
接下来使用“torch.multiprocessing”开启多个进程,本例中共开启了 4 个进程:

AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)