
从零开始的自然语言处理:使用字符级 RNN 对姓名进行分类
NLP From Scratch: Classifying Names with a Character-Level RNNhttps://docs.pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html构建并训练一个基本的字符级循环神经网络 (RNN) 来对单词进行分类字符级 RNN 将单词读取为一系列字符
NLP From Scratch: Classifying Names with a Character-Level RNN
https://docs.pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html
构建并训练一个基本的字符级循环神经网络 (RNN) 来对单词进行分类
字符级 RNN 将单词读取为一系列字符,并在每一步输出一个预测和“隐藏状态”,并将其之前的隐藏状态输入到下一步。我们将最终预测作为输出,即该单词所属的类别。 具体来说,我们将使用来自 18 种起源语言的数千个姓氏进行训练,并根据拼写预测姓名的来源语言。
一、准备 Torch Prearing Torch
根据您的硬件(CPU 或 CUDA)将 torch 设置为默认使用正确的设备使用 GPU 加速。
import torch
# Check if CUDA is available
device = torch.device('cpu')
if torch.cuda.is_available():
device = torch.device('cuda')
torch.set_default_device(device)
print(f"Using device = {torch.get_default_device()}")二、准备数据Preparing the Data
从此处https://download.pytorch.org/tutorial/data.zip下载数据并将其解压到当前目录。
data/names 目录中包含 18 个名为 [Language].txt 的文本文件。每个文件包含一组姓名,每行一个,大部分以罗马字母表示(但我们仍需要将其从 Unicode 转换为 ASCII)。
2.1 定义和清理数据
首先,我们需要将 Unicode 转换为纯 ASCII 以限制 RNN 输入层。具体方法是将 Unicode 字符串转换为 ASCII 并仅允许使用一小部分允许的字符。
import string
import unicodedata
# 定义模型允许处理的字符集合:包含所有大小写英文字母、空格、句号、逗号、分号、单引号,以及用于表示未收录字符的下划线
# 这里的下划线"_"将用来表示不在该集合中的字符(即未登录词,out-of-vocabulary)
allowed_characters = string.ascii_letters + " .,;'" + "_"
# 计算允许的字符总数,作为后续编码的维度依据
n_letters = len(allowed_characters)
# 将Unicode字符串转换为纯ASCII字符(过滤掉重音等附加符号)
def unicodeToAscii(s):
return ''.join(
# 遍历标准化后的字符串中的每个字符
c for c in unicodedata.normalize('NFD', s)
# 过滤条件1:排除Mark类非间距字符(如重音符号,category为'Mn')
if unicodedata.category(c) != 'Mn'
# 过滤条件2:仅保留在允许字符集合中的字符
and c in allowed_characters
)三、将名称转换为张量Turning Names into Tensors
3.1名称转换为张量
现在我们已经整理好了所有,接下来需要将它们转换为张量才能使用它们。
为了表示单个字母,我们使用大小为 <1 x n_letters> 的“独热向量”。
独热向量中除了当前字母的索引为 1 之外,其余部分都填充了 0,例如“b”= <0 1 0 0 0 ...>。
为了构成一个单词,我们将一堆这样的向量连接成一个二维矩阵 <line_length x 1 x n_letters>。 之所以多了一个维度,是因为 PyTorch 假设所有内容都是批量处理的——我们这里使用的批量大小为 1。
import torch # 注意:代码中使用了torch,需确保已导入
# 根据字符在允许字符集合中的位置返回其索引,例如"a"对应索引0
def letterToIndex(letter):
# 如果字符不在允许的集合中,返回下划线"_"的索引(代表未收录字符)
if letter not in allowed_characters:
return allowed_characters.find("_")
# 否则返回该字符在集合中的索引
else:
return allowed_characters.find(letter)
# 将一行文本转换为形状为<文本长度 x 1 x 字符总数>的张量
# 本质是生成由独热编码向量组成的数组(每个字符对应一个独热向量)
def lineToTensor(line):
# 初始化张量:维度1为文本长度,维度2为1(类似batch_size=1),维度3为字符总数
# 初始值全为0,后续会为每个位置的对应字符索引设为1(独热编码)
tensor = torch.zeros(len(line), 1, n_letters)
# 遍历文本中的每个字符及其位置索引
for li, letter in enumerate(line):
# 在张量的第li个位置(对应第li个字符),将该字符索引对应的位置设为1
# 形成独热编码:例如字符"a"在索引0,则tensor[li][0][0] = 1
tensor[li][0][letterToIndex(letter)] = 1
return tensor以下是一些如何使用 lineToTensor() 处理单个和多个字符串的示例。
print (f"The letter 'a' becomes {lineToTensor('a')}") #notice that the first position in the tensor = 1
print (f"The name 'Ahn' becomes {lineToTensor('Ahn')}") #notice 'A' sets the 27th index to 1
3.2将所有样本合并成一个数据
接下来,我们需要将所有样本合并成一个数据集,以便训练、测试和验证我们的模型。为此,我们将使用 Dataset 和 DataLoader 类来保存数据集。每个 Dataset 需要实现三个函数:__init__、__len__ 和 __getitem__。
from io import open
import glob # 用于查找符合特定模式的文件路径
import os # 用于处理文件路径和目录
import time # 用于记录时间
import torch
from torch.utils.data import Dataset # 导入PyTorch的数据集基类
# 自定义数据集类,继承自PyTorch的Dataset,用于加载和处理姓名数据
class NamesDataset(Dataset):
def __init__(self, data_dir):
# 初始化数据集,传入数据所在目录路径
self.data_dir = data_dir # 保存数据目录路径(用于数据溯源)
self.load_time = time.localtime() # 记录数据集加载时间(用于数据溯源)
labels_set = set() # 用集合存储所有类别标签(自动去重)
# 初始化存储数据的列表
self.data = [] # 存储原始姓名字符串
self.data_tensors = [] # 存储姓名对应的张量(经lineToTensor处理)
self.labels = [] # 存储每个姓名对应的类别标签(如国家/语言)
self.labels_tensors = [] # 存储标签对应的张量(类别索引)
# 获取数据目录下所有后缀为.txt的文件路径
text_files = glob.glob(os.path.join(data_dir, '*.txt'))
# 遍历每个文本文件(每个文件对应一个类别)
for filename in text_files:
# 从文件名中提取类别标签(例如"Chinese.txt"的标签为"Chinese")
label = os.path.splitext(os.path.basename(filename))[0]
labels_set.add(label) # 将标签添加到集合中(自动去重)
# 读取文件内容,按行分割为姓名列表(去除首尾空白并按换行符拆分)
lines = open(filename, encoding='utf-8').read().strip().split('\n')
# 遍历文件中的每个姓名
for name in lines:
self.data.append(name) # 保存原始姓名
# 将姓名转换为张量并保存(使用之前定义的lineToTensor函数)
self.data_tensors.append(lineToTensor(name))
self.labels.append(label) # 保存该姓名对应的标签
# 缓存标签的唯一列表和张量表示
self.labels_uniq = list(labels_set) # 将去重后的标签转为列表(固定顺序)
# 遍历所有标签,将每个标签转换为对应的索引张量
for idx in range(len(self.labels)):
# 查找标签在唯一列表中的索引,转为long类型张量(适合分类任务的标签格式)
temp_tensor = torch.tensor([self.labels_uniq.index(self.labels[idx])], dtype=torch.long)
self.labels_tensors.append(temp_tensor) # 保存标签张量
# 重写Dataset的__len__方法,返回数据集样本总数
def __len__(self):
return len(self.data)
# 重写Dataset的__getitem__方法,按索引返回样本数据
def __getitem__(self, idx):
# 获取索引对应的原始数据和张量
data_item = self.data[idx] # 原始姓名字符串
data_label = self.labels[idx] # 原始标签字符串
data_tensor = self.data_tensors[idx] # 姓名对应的张量
label_tensor = self.labels_tensors[idx] # 标签对应的索引张量
# 返回标签张量、数据张量、原始标签、原始数据(方便训练和调试)
return label_tensor, data_tensor, data_label, data_item
![]()
3.3将数据拆分为训练集和测试集
使用数据集对象可以让我们轻松地将数据拆分为训练集和测试集。这里我们创建了一个 80/20 的拆分, 但 torch.utils.data 提供了更多实用工具。这里我们指定了一个生成器,因为我们需要使用 与 PyTorch 默认的设备相同。
# 使用PyTorch的random_split将数据集按比例分割为训练集和测试集
# alldata: 待分割的完整数据集(此处为之前定义的NamesDataset实例)
# [.85, .15]: 分割比例,85%作为训练集,15%作为测试集
# generator: 用于控制随机分割的生成器,保证结果可复现
# torch.Generator(device=device): 在指定设备(如CPU/GPU)上创建随机数生成器
# manual_seed(2024): 设置随机种子为2024,确保每次运行分割结果完全一致
train_set, test_set = torch.utils.data.random_split(
alldata,
[.85, .15],
generator=torch.Generator(device=device).manual_seed(2024)
)
# 打印训练集和测试集的样本数量,验证分割结果
# len(train_set): 训练集样本数(总样本的85%)
# len(test_set): 测试集样本数(总样本的15%)
print(f"train examples = {len(train_set)}, validation examples = {len(test_set)}")现在我们有了一个包含 20074 个样本的基本数据集,每个样本都是标签和名称的配对。我们还将数据集拆分为训练集和测试集,以便验证我们构建的模型。
四、创建网络Creating the Network
在自动求导之前,在 Torch 中创建循环神经网络需要克隆某个层在多个时间步上的参数。这些层保存隐藏状态和梯度,而现在这些参数完全由计算图本身处理。这意味着您可以以非常“纯粹”的方式实现 RNN,就像常规的前馈层一样。
这个 CharRNN 类实现了一个包含三个组件的 RNN。首先,我们使用 nn.RNN 实现。接下来,我们定义一个层,将 RNN 隐藏层映射到输出。最后,我们应用一个 softmax 函数。与将每个层都实现为 nn.Linear 相比,使用 nn.RNN 可以显著提升性能,例如使用 cuDNN 加速的内核。它还简化了 forward() 中的实现。
import torch.nn as nn # 导入PyTorch神经网络模块
import torch.nn.functional as F # 导入PyTorch神经网络函数模块
# 定义字符级循环神经网络模型,继承自nn.Module(PyTorch所有模型的基类)
class CharRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
# 调用父类构造函数初始化
super(CharRNN, self).__init__()
# 定义RNN层:输入尺寸为input_size(字符独热向量维度),隐藏层尺寸为hidden_size
self.rnn = nn.RNN(input_size, hidden_size)
# 定义从隐藏层到输出层的全连接层:将隐藏层输出映射到输出尺寸output_size(类别数)
self.h2o = nn.Linear(hidden_size, output_size)
# 定义LogSoftmax层:对输出进行归一化,dim=1表示在类别维度上计算
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, line_tensor):
# 前向传播过程:输入为文本张量line_tensor(形状为<序列长度 x 1 x input_size>)
# 执行RNN计算:返回输出序列rnn_out和最后一个时间步的隐藏状态hidden
rnn_out, hidden = self.rnn(line_tensor)
# 取最后一个时间步的隐藏状态(hidden是元组,[0]为隐藏状态张量),通过全连接层映射到输出
output = self.h2o(hidden[0])
# 对输出应用LogSoftmax,得到归一化的类别概率分布(对数形式)
output = self.softmax(output)
return output # 返回最终的类别预测分布

之后,我们可以将张量传递给 RNN 以获得预测输出。随后,我们使用辅助函数 label_from_output 来为该类别导出文本标签。
def label_from_output(output, output_labels):
# 从模型输出中获取预测的标签及其索引
# output:模型的输出张量(形状通常为<1 x 类别数>,包含LogSoftmax后的概率)
# output_labels:所有可能的标签列表(如alldata.labels_uniq,与输出索引对应)
# topk(1)返回输出中最大值对应的数值和索引,取前1个(即预测概率最高的类别)
top_n, top_i = output.topk(1)
# 将索引张量转换为Python整数(top_i[0]取第一个维度的元素,item()转为标量)
label_i = top_i[0].item()
# 返回预测的标签字符串和对应的索引
return output_labels[label_i], label_i五、训练Training
现在,训练这个网络只需向它展示一些样本,让它进行猜测,并判断它是否正确。
我们通过定义一个 train() 函数来实现这一点,该函数使用小批量 (minibatches) 在给定数据集上训练模型。RNN 的训练方式与其他网络类似;因此,为了完整性,我们在这里引入了一种批量训练方法。循环 (for i in batch) 在调整权重之前,计算批次中每个项目的损失。此操作重复进行,直到达到指定的 epoch 数。
import random
import numpy as np
import time # 注意:代码中使用了time,需确保已导入
def train(rnn, training_data, n_epoch=10, n_batch_size=64, report_every=50, learning_rate=0.2, criterion=nn.NLLLoss()):
"""
在训练数据的批次上进行指定次数的迭代学习,并按设定阈值汇报训练进度
参数说明:
rnn: 待训练的CharRNN模型
training_data: 训练数据集(如之前分割的train_set)
n_epoch: 训练轮数(默认10轮)
n_batch_size: 批次大小(默认64,每批包含64个样本)
report_every: 每隔多少轮汇报一次训练损失(默认50轮)
learning_rate: 学习率(默认0.2)
criterion: 损失函数(默认NLLLoss,适合LogSoftmax输出的分类任务)
"""
# 记录损失值用于后续可视化
current_loss = 0 # 当前累计损失
all_losses = [] # 存储每轮的平均损失
rnn.train() # 将模型设为训练模式(启用 dropout 等训练特有的层)
# 定义优化器:使用随机梯度下降(SGD),优化模型参数
optimizer = torch.optim.SGD(rnn.parameters(), lr=learning_rate)
start = time.time() # 记录训练开始时间
print(f"training on data set with n = {len(training_data)}") # 打印训练集样本数量
# 迭代训练指定轮数
for iter in range(1, n_epoch + 1):
rnn.zero_grad() # 清零模型参数的梯度(避免累积上一轮的梯度)
# 创建小批次数据
# 由于每个姓名的长度不同,无法直接使用DataLoader,因此手动划分批次
batches = list(range(len(training_data))) # 生成样本索引列表
random.shuffle(batches) # 随机打乱索引,实现样本顺序随机化
# 按批次大小分割索引列表,得到多个批次的索引(最后一批可能不足n_batch_size)
batches = np.array_split(batches, len(batches) // n_batch_size)
# 遍历每个批次
for idx, batch in enumerate(batches):
batch_loss = 0 # 初始化当前批次的损失
# 遍历批次中的每个样本
for i in batch:
# 获取样本数据:标签张量、文本张量、原始标签、原始文本
(label_tensor, text_tensor, label, text) = training_data[i]
# 模型前向传播:输入文本张量,得到预测输出
output = rnn.forward(text_tensor)
# 计算当前样本的损失(预测输出与真实标签的差距)
loss = criterion(output, label_tensor)
batch_loss += loss # 累加批次内所有样本的损失
# 反向传播与参数优化
batch_loss.backward() # 计算损失对模型参数的梯度(反向传播)
# 梯度裁剪:限制梯度的最大范数为3,防止梯度爆炸
nn.utils.clip_grad_norm_(rnn.parameters(), 3)
optimizer.step() # 根据梯度更新模型参数
optimizer.zero_grad() # 清零优化器的梯度(避免累积)
# 累计当前批次的平均损失(除以批次大小)
current_loss += batch_loss.item() / len(batch)
# 记录本轮的平均损失(总损失除以批次数)
all_losses.append(current_loss / len(batches))
# 按设定间隔汇报训练进度
if iter % report_every == 0:
print(f"{iter} ({iter / n_epoch:.0%}): \t average batch loss = {all_losses[-1]}")
current_loss = 0 # 重置当前损失,为下一轮做准备
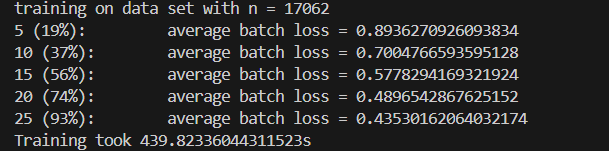
return all_losses # 返回每轮的平均损失列表,用于后续分析或绘图现在,我们可以用小批量训练数据集,训练周期数可指定。本例中,为了加快构建速度,我们减少了周期数。使用不同的参数可以获得更好的结果。

六、评价结果 Evaluating the Results
为了了解网络在不同类别上的表现,我们将创建一个混淆矩阵,针对每种实际语言(行)标明网络猜测的语言(列)。为了计算混淆矩阵,我们使用 evaluate() 方法在网络中运行大量样本,该方法与 train() 方法相同,只是没有使用反向传播。
import matplotlib.pyplot as plt # 注意:代码中使用了plt,需确保已导入
import matplotlib.ticker as ticker # 用于设置坐标轴刻度
def evaluate(rnn, testing_data, classes):
# 初始化混淆矩阵(混淆矩阵):行表示真实标签,列表示预测标签,尺寸为[类别数 x 类别数]
confusion = torch.zeros(len(classes), len(classes))
rnn.eval() # 将模型设为评估模式(关闭 dropout 等训练特有的层)
# 关闭梯度计算(评估阶段不需要反向传播,节省内存并加速计算)
with torch.no_grad():
# 遍历测试集中的每个样本
for i in range(len(testing_data)):
# 获取样本数据:标签张量、文本张量、原始标签、原始文本
(label_tensor, text_tensor, label, text) = testing_data[i]
# 模型前向传播,得到预测输出
output = rnn(text_tensor)
# 从输出中解析预测的标签及其索引
guess, guess_i = label_from_output(output, classes)
# 获取真实标签在类别列表中的索引
label_i = classes.index(label)
# 更新混淆矩阵:真实标签为label_i、预测标签为guess_i的位置计数+1
confusion[label_i][guess_i] += 1
# 归一化混淆矩阵:每行除以该行的总和,得到每个真实标签被预测为各类别的比例
for i in range(len(classes)):
denom = confusion[i].sum() # 第i行的总和(真实标签为i的样本总数)
if denom > 0: # 避免除以0(若某类别无测试样本)
confusion[i] = confusion[i] / denom
# 绘制混淆矩阵热图
fig = plt.figure() # 创建图形对象
ax = fig.add_subplot(111) # 添加子图
# 将混淆矩阵转换为numpy数组(若在GPU上需先移至CPU),并绘制热图
cax = ax.matshow(confusion.cpu().numpy())
fig.colorbar(cax) # 添加颜色条,显示数值与颜色的对应关系
# 设置坐标轴刻度和标签(类别名称)
ax.set_xticks(np.arange(len(classes)), labels=classes, rotation=90) # x轴为预测标签
ax.set_yticks(np.arange(len(classes)), labels=classes) # y轴为真实标签
# 强制每个刻度都显示(避免类别过多时标签被省略)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1)) # x轴每1个单位显示一个刻度
ax.yaxis.set_major_locator(ticker.MultipleLocator(1)) # y轴每1个单位显示一个刻度
# 显示热图
plt.show()
# 调用评估函数:使用训练好的rnn模型,在test_set上评估,类别列表为数据集的唯一标签
evaluate(rnn, test_set, classes=alldata.labels_uniq)
鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 41
41 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)