
InfiniBand 技术解析(5):通信的心脏 —— 深入剖析 Queue Pair 传输引擎
深入探讨了InfiniBand高性能的核心设计——队列对(QP)机制。文章对比传统TCP/IP网络的内核态切换、数据拷贝等性能瓶颈,详细解析QP通过双队列设计、硬件直驱、零拷贝和内核旁路等创新特性实现的高效通信流程。重点阐述了QP在RDMA操作中的关键作用,使远程内存直接访问成为可能,为AI训练等高性能计算场景提供重要支撑。该文揭示了InfiniBand打破传统网络性能桎梏的技术原理,为理解数据中
🚀 欢迎来到「数据中心网络与异构计算」专栏!
在这个算力定义未来的时代,我们正见证一场从底层网络到计算架构的深刻变革。本专栏将带您穿越技术迷雾,从当前困境出发,历经三次关键技术跃迁,最终抵达「数据中心即计算机」的终极愿景。
目录
在前四篇文章中,我们已将 InfiniBand 的"超级血管"框架逐步铺开:从它为何能成为高性能计算的核心互连技术,到解码硬件组件、网络结构的核心术语,再到子网管理器如何像"交通调度中心"让硬件有序协作。但这一切都还停留在"静态架构"层面 —— 就像一座城市搭好了道路与信号灯,却还没弄明白"血液"(数据)是如何被高效泵送到每个角落的。而 InfiniBand 中承担"心脏泵血"功能的,正是其最核心、最具革新性的设计 ——Queue Pair(QP,队列对)。它不仅是数据传输的"动力源泉",更通过"内核旁路""零拷贝"等设计,彻底打破了传统 TCP/IP 网络的性能桎梏,成为 IB 高性能的真正基石。
一、从传统网络瓶颈到硬件直驱:QP 的性能突破之道
要理解 QP 的价值,首先需要了解传统 TCP/IP 网络的性能瓶颈。在 TCP/IP 架构中,数据从应用发送到远程节点,需要经过复杂的软件路径:从用户态应用到内核态协议栈,再到网卡缓冲区,经过网络传输后,在接收端又要经过反向的类似路径。这一过程中存在两个主要性能瓶颈:
首先是内核态与用户态之间的切换开销。应用数据必须从用户空间拷贝到内核空间,接收时又要反向拷贝,每次切换与拷贝都会消耗宝贵的 CPU 时钟周期。其次是软件协议处理的延迟。TCP 的连接管理、流量控制、重传机制等都依赖内核软件实现,即使经过优化,单次数据传输的软件处理延迟仍然相当可观。
InfiniBand 的 QP 设计从根本上解决了这些痛点:它采用硬件直接接管数据传输全流程的架构,实现从用户态应用直接到 HCA 硬件,再到远程 HCA,最后到远程用户态应用的端到端路径。QP 作为应用与 HCA 之间的通信接口,成为硬件直驱的核心载体。
二、QP 架构深度解析:双队列构成的通信端点
2.1 工作模式
每一个CA实现数量多达对 Queue Pair(QP)。QP,顾名思义,是由发送队列(Send Queue,SQ)与接收队列(Receive Queue,RQ)组成的一对互补队列,二者共同构成一个独立的通信端点。每个 QP 都有唯一的标识符,远程节点通过"QP 号 + 目标地址"就能定位到具体的通信端点。
从功能上看,SQ 与 RQ 分工明确且紧密协同:
- SQ 负责向外发送数据,应用将待发送的数据、目标地址、操作类型等信息封装成工作请求(Work Request,WR),提交到 SQ 中;HCA 硬件会持续扫描 SQ,一旦发现新的 WR,就直接从应用内存中读取数据并发送到网络。
- RQ 则负责接收远程数据,应用需提前在 RQ 中提交接收缓冲区信息的 WR,HCA 接收到远程数据包后,会自动将数据写入指定的缓冲区。
关键在于:SQ 与 RQ 是用户态队列,完全由应用程序控制,无需经过内核。这种用户态直接访问的机制是实现高性能的关键。
2.2 报文序号
SQ生成的每个请求包都包含一个PSN,收到请求数据包后,RQ将验证数据包是否与期望的PSN (ePSN)一致。
与之对应的,RQ生成的每个响应包都包含一个PSN,该PSN将它与从远端SQ接收到的请求包关联,SQ收到每个响应包时, 将验证包的PSN是否与之前发出的请求相关联。
三、QP 工作流程详解:Send/Recv 的硬件直驱之路
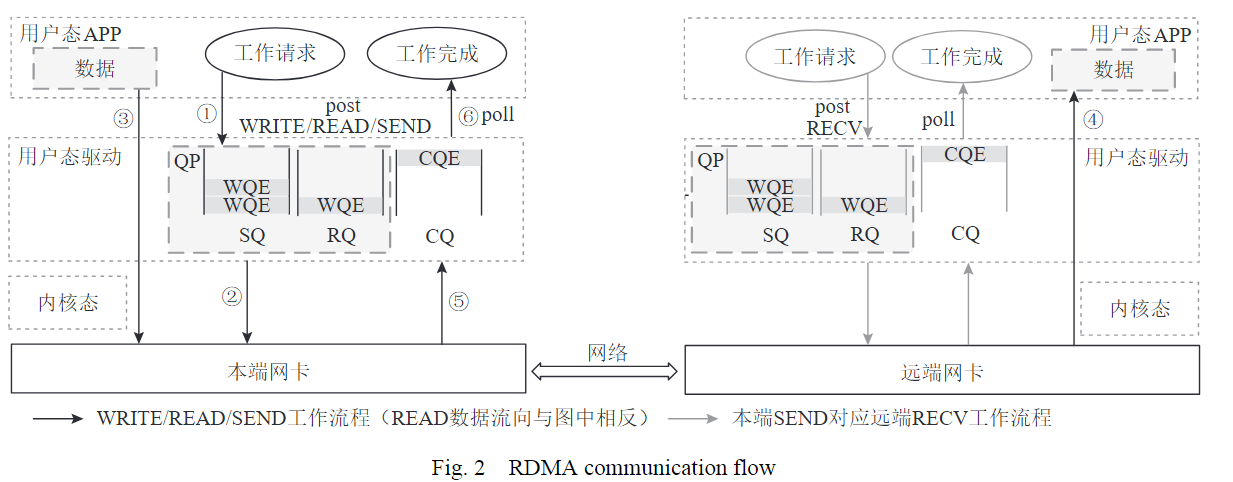
要理解 QP 的高效性,可以通过分析一次完整的 Send/Recv 通信流程来说明。假设服务器 A 要向服务器 B 发送数据,整个过程由 HCA 硬件主导,CPU 仅在关键环节参与:
1. 本端发送流程(WRITE/READ/SEND 通用逻辑,READ 数据流方向相反)
-
步骤①:APP 提交 “发送请求” 到 SQ用户态 APP 需要发送数据时,通过用户态驱动(如 Verbs API 的
ibv_post_send接口),将 “发送指令” 封装成 工作队列元素(work queue element,WQE),并提交到本地 QP 的 SQ(发送队列) 中。这一步完全在用户态完成,无需内核参与,避免了 “用户态→内核态” 的上下文切换开销。 -
步骤②:本端网卡处理 WQE:本端网卡(HCA)会主动轮询 SQ,检测并获取新的 WQE 。
-
步骤③:当检测到新的WQE后,通过 DMA 技术,直接从用户态 APP 的内存中读取待发送数据(无需拷贝到内核态),将数据封装成符合 InfiniBand 协议的报文(包含 LRH、GRH、BTH 等头部,以及 Payload 数据)。
2. 远端接收流程(对应本端 SEND)
-
步骤④:执行RDMA写操作,直接写入远端内存:远端网卡收到本端传输的 IB 报文后,解析报文头部(确认目标 QP、操作类型等),然后通过 DMA 直接将 Payload 数据写入远端用户态 APP 预先预留的内存缓冲区中(该缓冲区由远端 APP 通过类似 “
ibv_post_recv” 的操作提前注册到 RQ)。这一步同样是 “零拷贝”,数据直接从网卡到用户态内存,无需远端内核介入。 -
步骤⑤:远端网卡生成 CQE,通知操作完成远端网卡完成数据接收后,会生成 CQE(包含 “操作成功 / 失败”“传输字节数” 等信息),并将 CQE 放入与 QP 绑定的 CQ(完成队列) 中。
-
步骤⑥:发送端APP 轮询 CQ,获取完成通知远端用户态 APP 通过轮询 CQ(如调用
ibv_poll_cq接口),读取 CQE,得知 “数据已成功传输”,从而可以进行后续业务逻辑。
四、RDMA 操作:远程内存直接访问的创新范式
RDMA Read/Write 是 QP 架构中的创新特性,它实现了"通信即内存访问"的范式转变,让服务器能够直接读写远程服务器的内存,且无需对端 CPU 参与。
实现 RDMA 操作需要先通过内存区域(MR)注册机制建立安全访问权限。服务器将待访问的内存注册为 MR,HCA 为其生成远程密钥(R_Key)和远程虚拟地址(RVA)。获得这些访问凭证后,远程服务器就可以直接通过 RDMA 操作访问该内存区域。
在 AI 训练等高性能计算场景中,RDMA 的价值尤为突出:GPU 可通过 RDMA 直接访问其他节点的参数数据,无需 CPU 中转,大幅提升了计算资源的利用效率。
五、总结与展望
QP 通过双队列的通信端点设计、硬件直驱的工作流程、零拷贝和内核旁路特性,以及创新的 RDMA 操作,有效解决了传统网络的性能瓶颈,成为 InfiniBand 高性能的核心引擎。
理解 QP 的设计对于深入学习 InfiniBand 底层协议至关重要。下一篇文章我们将聚焦 InfiniBand 的分层架构,分析 QP 生成的数据如何在各协议层中封装和传输,揭示 IB 高性能的完整技术体系。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)