
详细Yolov8n和Yolo11n训练AgroPest-12
本文介绍了在FunHPC网站租用GPU服务器进行YOLOv8模型训练的过程。学生可免费使用一年,但需及时抢购显卡资源。作者分享了从创建conda环境、安装PyTorch和ultralytics库到训练模型的全流程,包括解决numpy版本冲突问题。重点说明了使用CPU/GPU训练的参数配置方法,并详细解释了YOLO命令行中各参数的含义(如task、mode、model等)。文章特别提醒初学者注意框架
在计算机视觉领域,YOLOv8以其高效的实时目标检测能力成为热门选择。然而,对于学生和研究者而言,GPU资源的获取往往是训练模型的第一道门槛。
FunHPC平台提供学生用户一年免费GPU服务器使用权,但需注意显卡资源需定时抢购。建议提前了解平台开放时间,并准备好账户信息以提高成功率。
本次我们使用的数据集为Kaggle上的AgroPest-12,它是一个精选数据集,包含 12 类农作物昆虫和害虫的图像,由此我们使用Yolov8n和Yolo11n模型在云服务器上训练,实现对12类农作物昆仲的精准识别。
租用服务器的网站 (学生认证免费使用一年,不过要看准时机抢显卡):https://www.funhpc.com![]() https://www.funhpc.com
https://www.funhpc.com
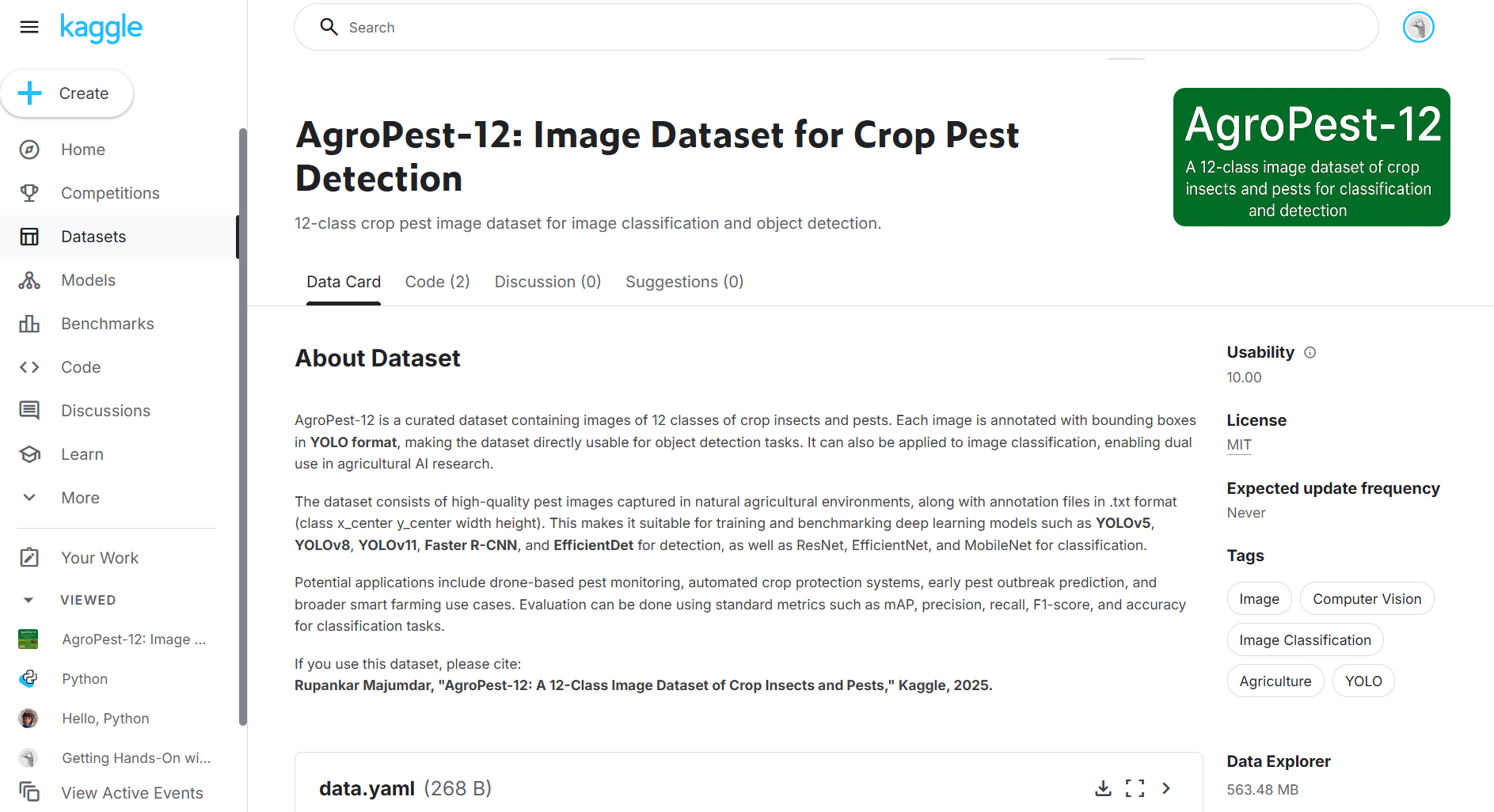

我抢的时候刷新两分钟出来显卡了,就直接创建一个了。
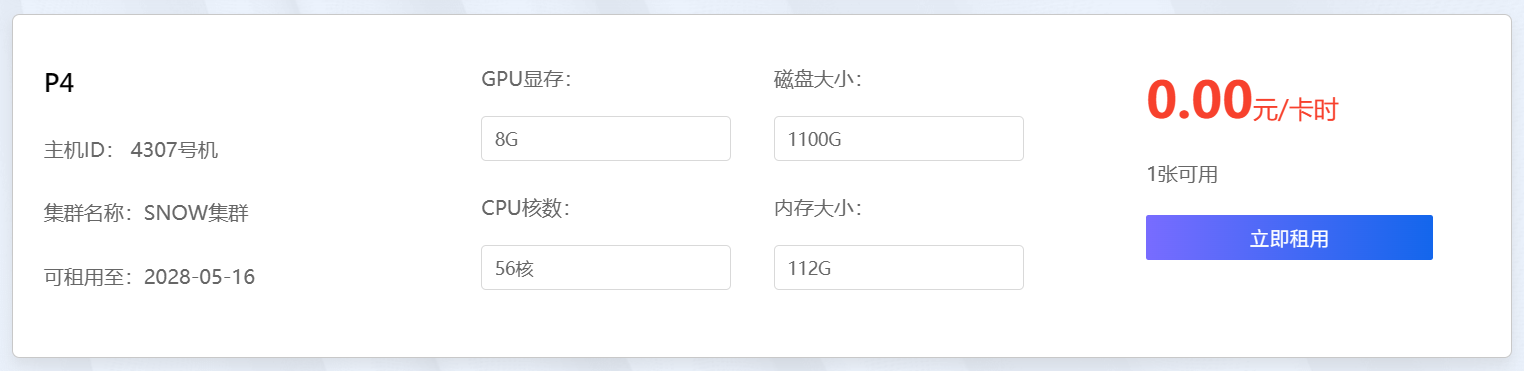
镜像我是随便选择的,我感觉都这个任务来看,选择哪一个都差不多,毕竟还要下载对应库的。(这是一个错误的选择,先往下看吧)
等实例运行…………
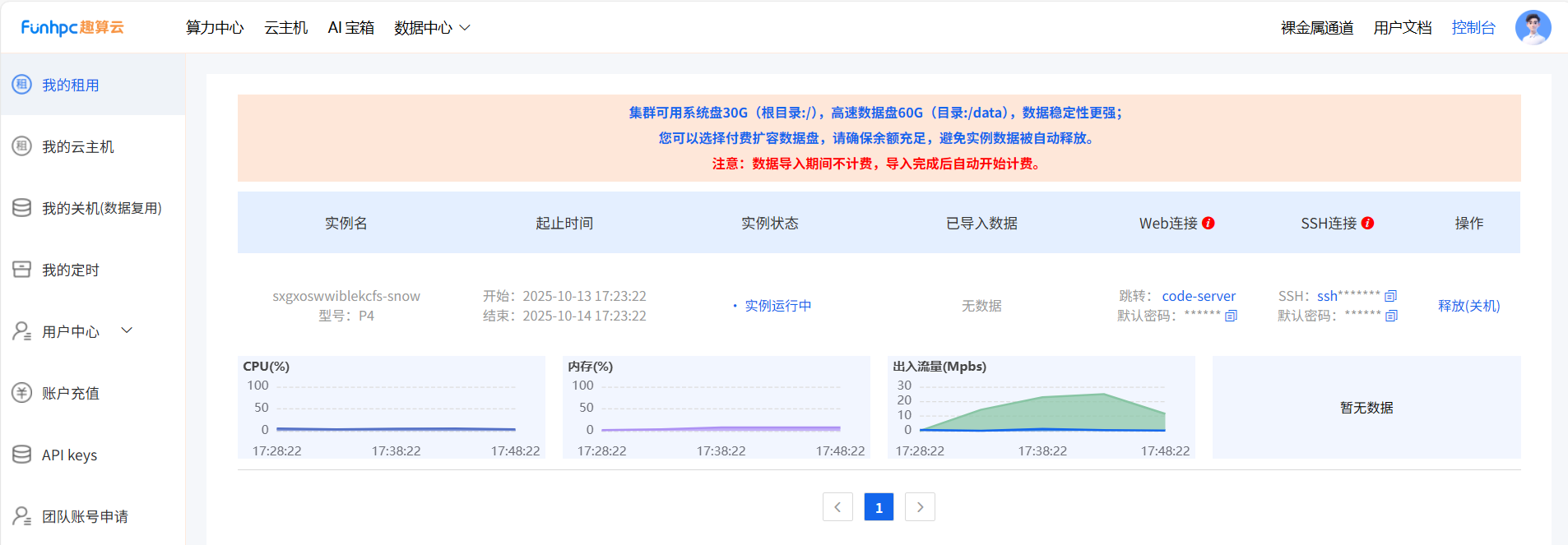
首先将训练所需要的文件上传,直接拖动上面就行,稍等几分钟就上传完了,文件简略结构:
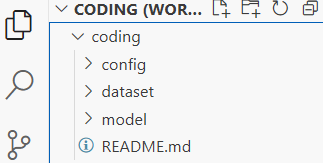
展开如下:
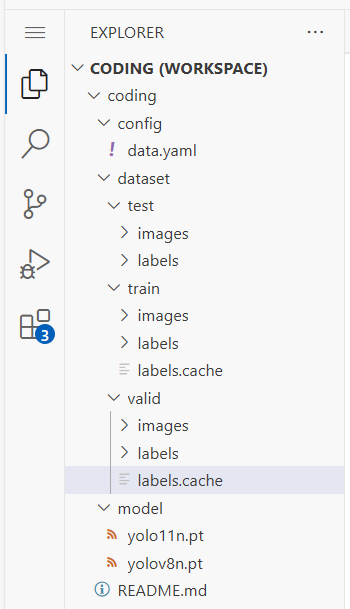
修改data.yaml文件中的文件路径:
# 最好写绝对路径,修改以下三行代码
train: /data/coding/dataset/train/images
val: /data/coding/dataset/valid/images
test: /data/coding/dataset/test/images
nc: 12 # 分类种数
names:
[
"Ants",
"Bees",
"Beetles",
"Caterpillars",
"Earthworms",
"Earwigs",
"Grasshoppers",
"Moths",
"Slugs",
"Snails",
"Wasps",
"Weevils",
]按照步骤打开Terminal终端:
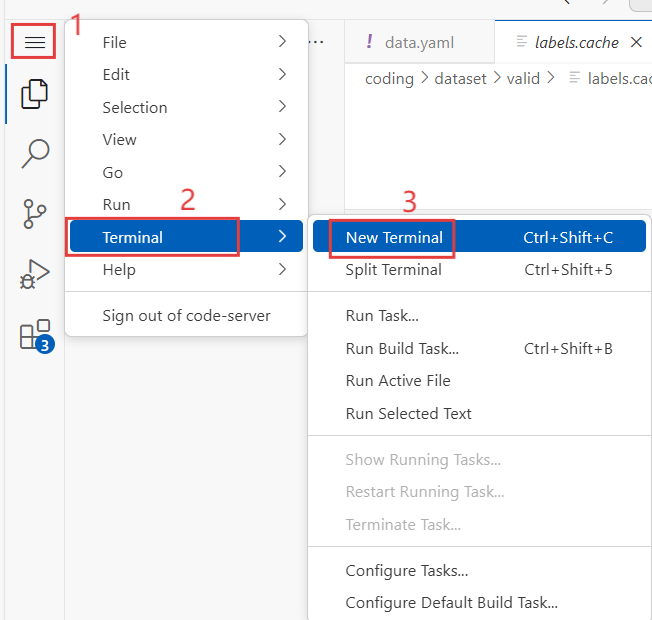
在打开的Terminal中输入:
conda env listenter运行,检查已有的conda环境
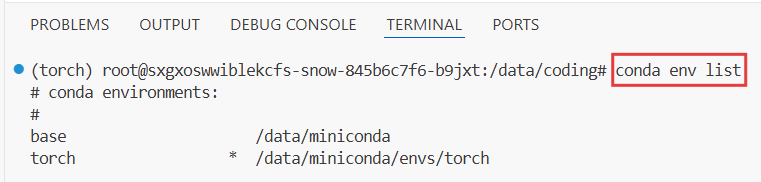
输入:
# 创建yolo环境
conda create -n yolo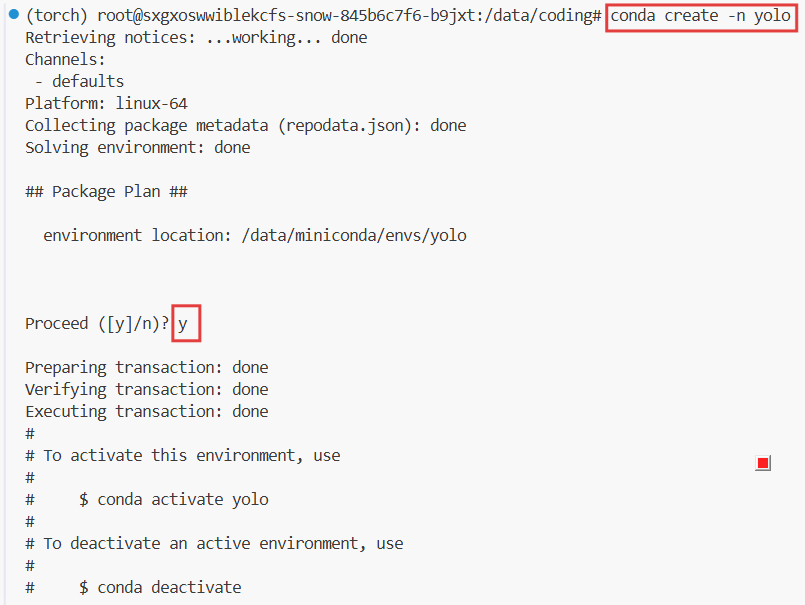
然后继续输入:
# 激活这个yolo环境
conda activate yolo切换到我们创建的yolo环境中了:

唉,由于之前随便选框架版本,导致不兼容,需要重新修改一下框架配置:
pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 \
--index-url https://download.pytorch.org/whl/cu121接下来我们下载ultralytics库:
pip install ultralytics时间一点点长,5分钟左右吧
先用cpu训练(device=cpu)两轮看看能不能跑通:
yolo task=detect mode=train model=./model/yolov8n.pt data=./config/data.yaml epochs=2 imgsz=320 device=cpu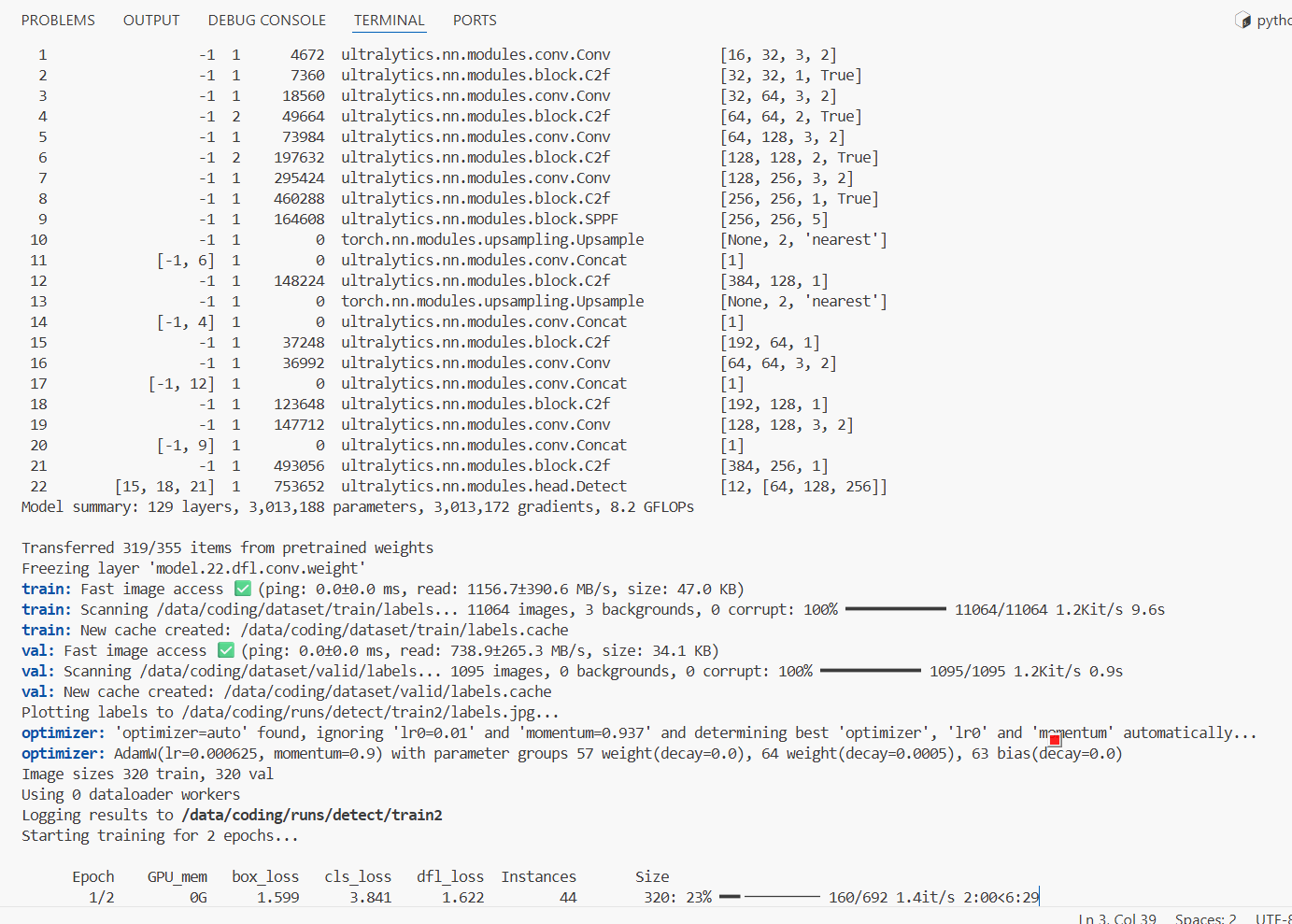
如果出现numpy版本出错:
RuntimeError: Numpy is not available就修改一下numpy的版本:
pip install --force-reinstall "numpy<2.0"使用GPU训练(device=0):
yolo task=detect mode=train \
model=./model/yolov8n.pt \
data=./config/data.yaml \
epochs=2 \
imgsz=320 \
device=0| 参数 | 说明 | 示例值 |
|---|---|---|
| yolo |
Ultralytics 官方命令行入口 |
固定写法 |
| task=detect | 指定任务类型:detect(检测)、segment(分割)、classify(分类)、pose(关键点) | |
| mode=train | 模式:train(训练)、val(验证)、predict(预测)、export(导出模型) | |
| model=./model/yolov8n.pt |
① 加载的 预训练权重 路径; |
|
| data=./config/data.yaml |
数据集配置文件,内含路径、类别数、类别名称 |
|
| epochs=2 |
训练轮数(整个数据集跑几遍) |
2(调试)-->300(正式) |
| imgsz=320 | 输入网络的 图片短边 尺寸(长边自动等比缩放) |
最好是32的倍数(640等) |
| device=0 | 训练设备 |
0:第 1 张 GPU; |
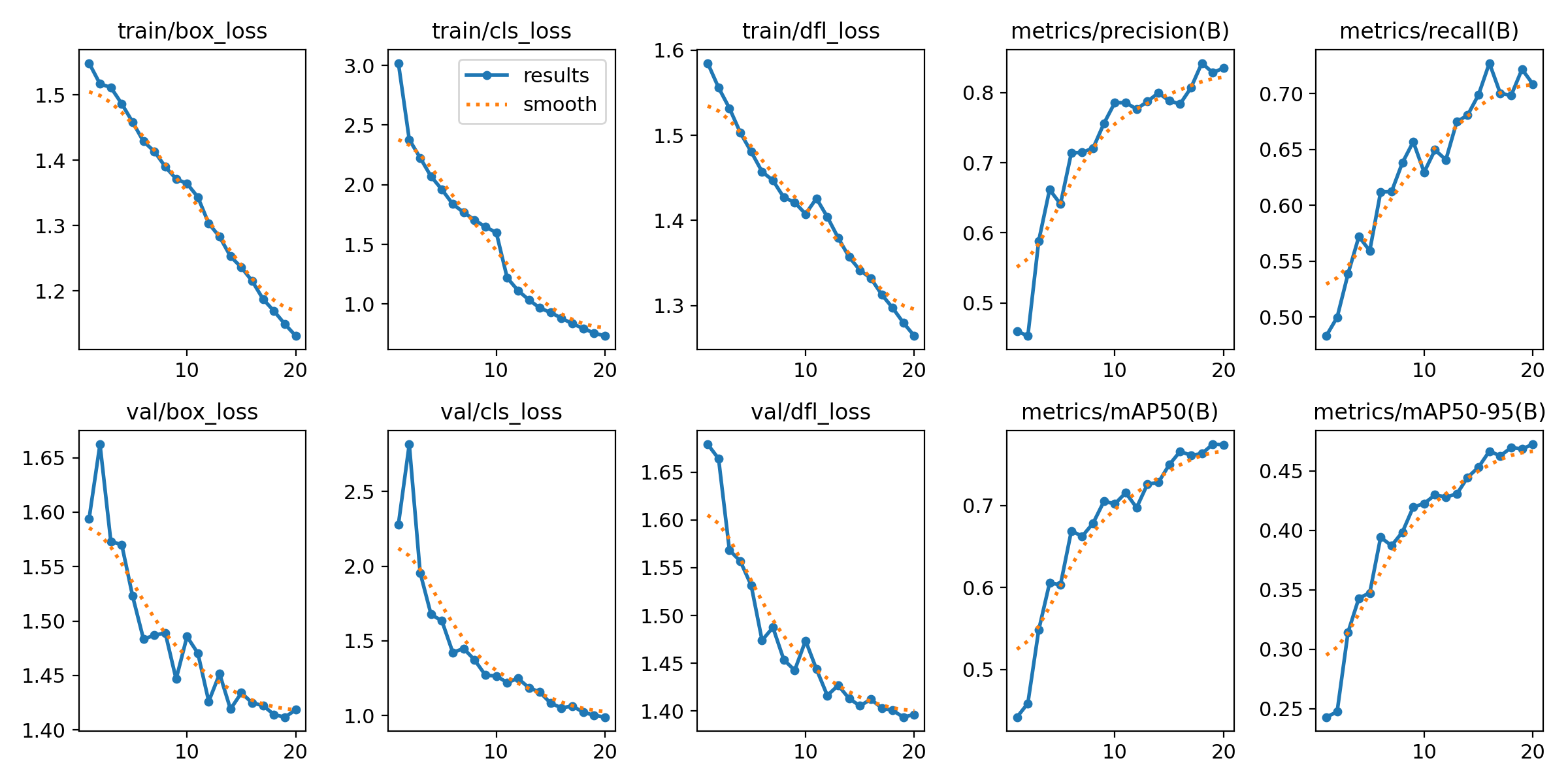
实际训练中,可多训练几论(如50、300轮),参数都可以修改的。最后在文件栏会自动生成一个runs文件夹,里面有很多数据以及可视化图表。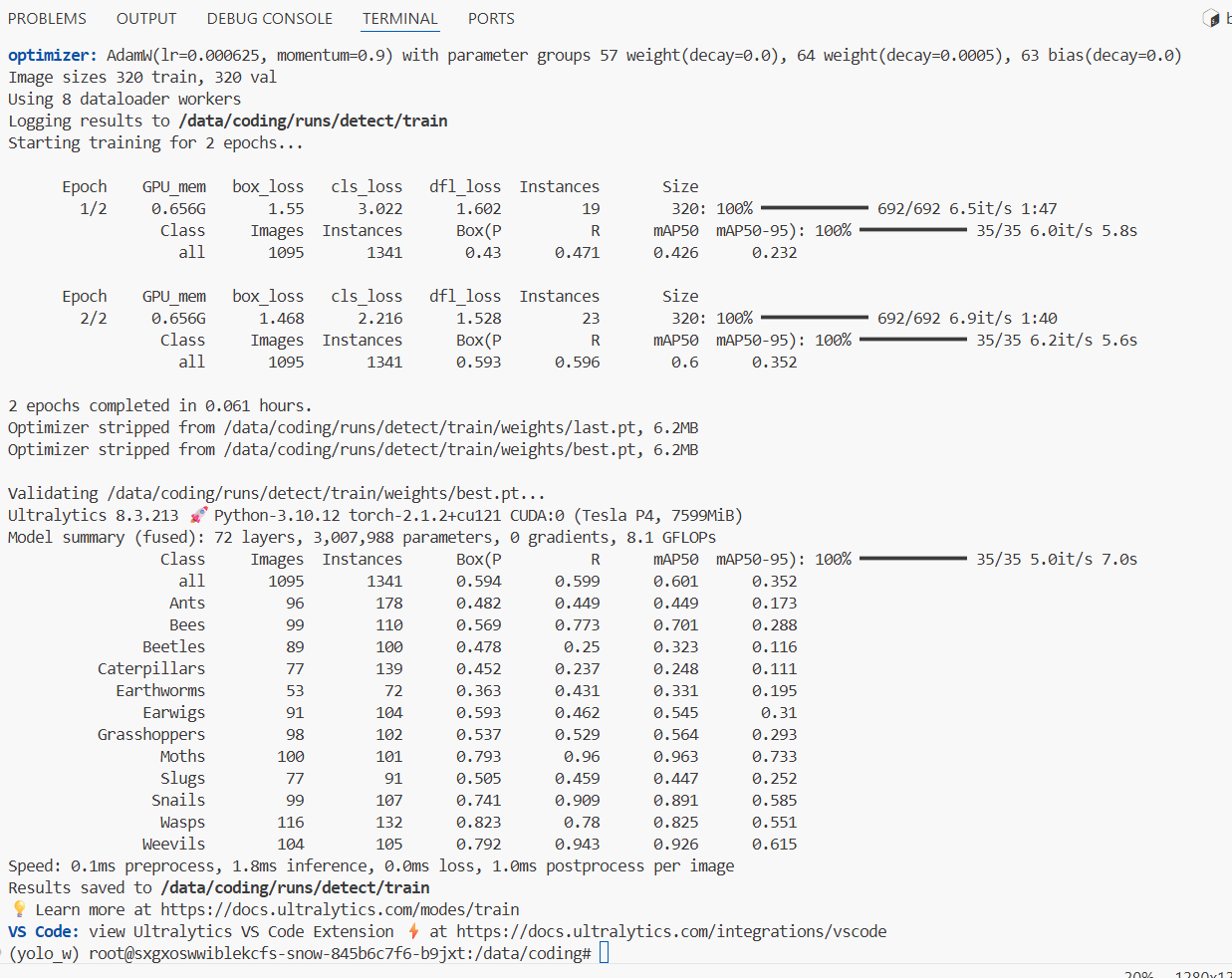
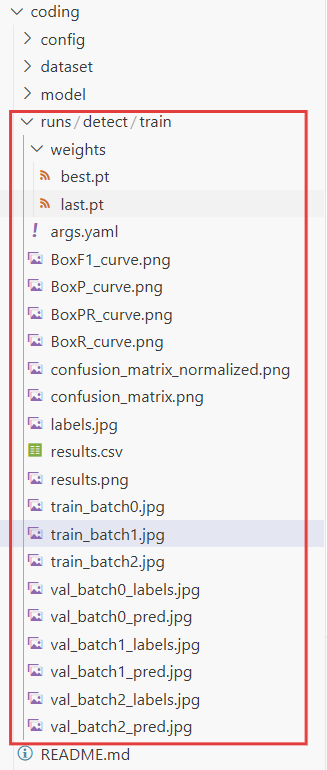
我这里是cpu训练20轮的结果,当然你要多训练几轮!
如有问题,请在评论区多多交流!!!
下期我们讲讲生成的图像是什么意思,该怎么理解?
掰掰咯

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)