
基于Hadoop+Spark的全球经济指标分析与可视化系统实践
本文介绍了一个基于Hadoop+Spark的全球经济指标分析与可视化系统。该系统利用Hadoop分布式存储和Spark高性能计算处理海量经济数据,采用Python/Java开发,支持Django/SpringBoot后端框架。系统功能包括GDP趋势分析、经济体对比、经济指标关联分析等,通过Vue+Echarts实现数据可视化。核心技术涵盖HDFS、SparkSQL、Pandas等大数据处理工具,结
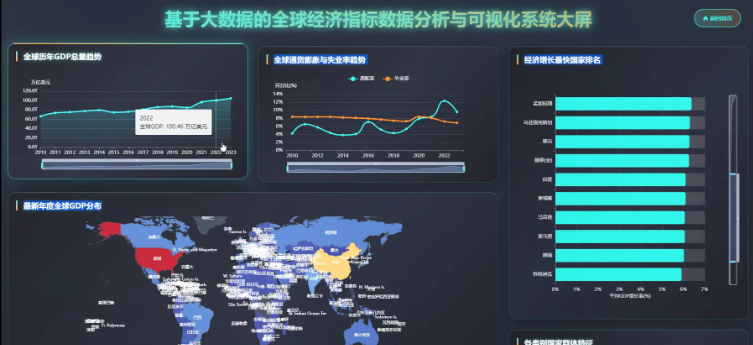
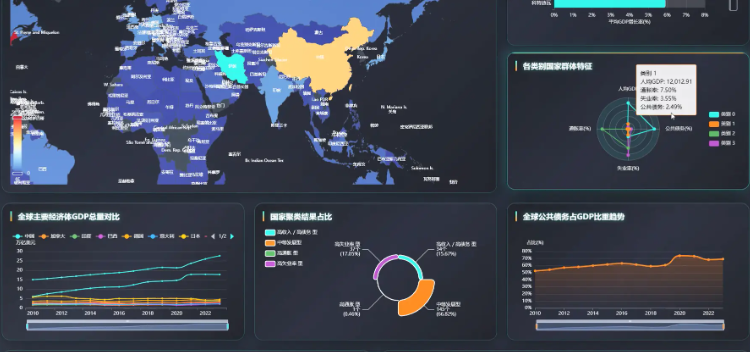
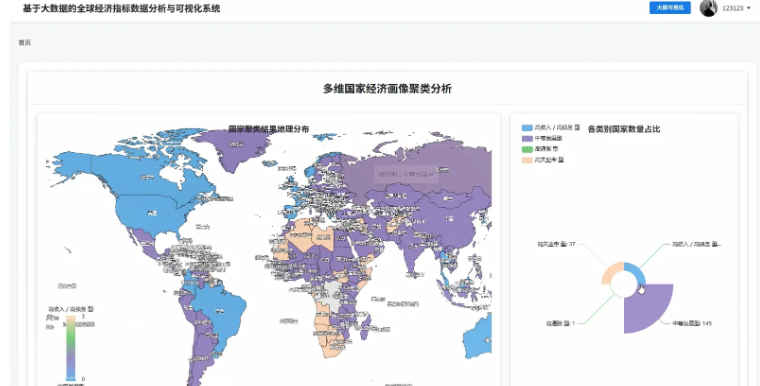
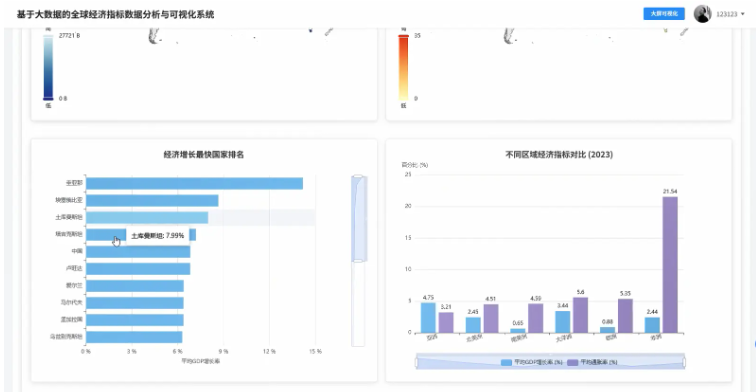
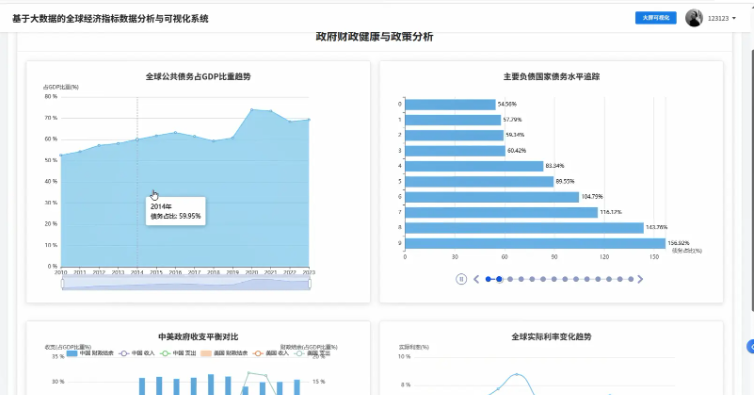
基于Hadoop+Spark的全球经济指标分析与可视化系统是一套专门针对大规模经济数据处理与分析的企业级解决方案,该系统充分利用Hadoop分布式文件系统的海量数据存储能力和Spark内存计算框架的高性能处理优势,实现对全球经济指标数据的深度挖掘和智能分析。系统采用Python作为主要开发语言,结合Django Web框架构建稳定的后端服务架构,通过Spark SQL和Pandas、NumPy等数据科学库实现复杂的经济数据计算和统计分析功能。前端采用Vue.js框架配合ElementUI组件库和Echarts可视化引擎,为用户提供直观友好的数据展示界面。系统核心功能包括全球GDP总量趋势分析、主要经济体对比分析、通胀失业率关联分析、政府财政健康度评估以及基于机器学习的国家经济画像聚类等多个维度的深度分析模块,通过HDFS存储世界银行等权威机构的海量经济数据,运用Spark的分布式计算能力实现TB级数据的快速处理和实时分析,最终通过MySQL数据库管理分析结果,为政策制定者、学术研究人员和金融分析师提供科学可靠的数据支撑和决策参考。
大数据框架:Hadoop+Spark(本次没用Hive,支持定制) 开发语言:Python+Java(两个版本都支持) 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持) 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy 数据库:MySQL

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)