
异构计算与 CUDA 概述
定位:基于 NVIDIA GPU 的完整计算平台(硬件 + 软件 + 工具链)。语言支持:CUDA C (ANSI C 扩展,新增关键字、API)平台系列Tegra → 嵌入式GeForce → 消费级图形、游戏Quadro → 专业图形工作站Tesla → 高性能计算(HPC)性能指标CUDA 核心数GPU 显存大小峰值计算能力 (GFLOPS)内存带宽CPU 程序:写主函数,顺序执行。CUDA
·
一、异构计算概念
- 定义:不同计算架构协同工作即为异构(CPU+GPU 最常见,CPU+FPGA、CPU+DSP 也常见)。
- 特点:
- GPU → 并行度高,适合大规模数据计算
- CPU → 控制逻辑强,适合复杂流程
- 应用复杂度高:需要开发者手动管理 计算分工、控制与数据传输。
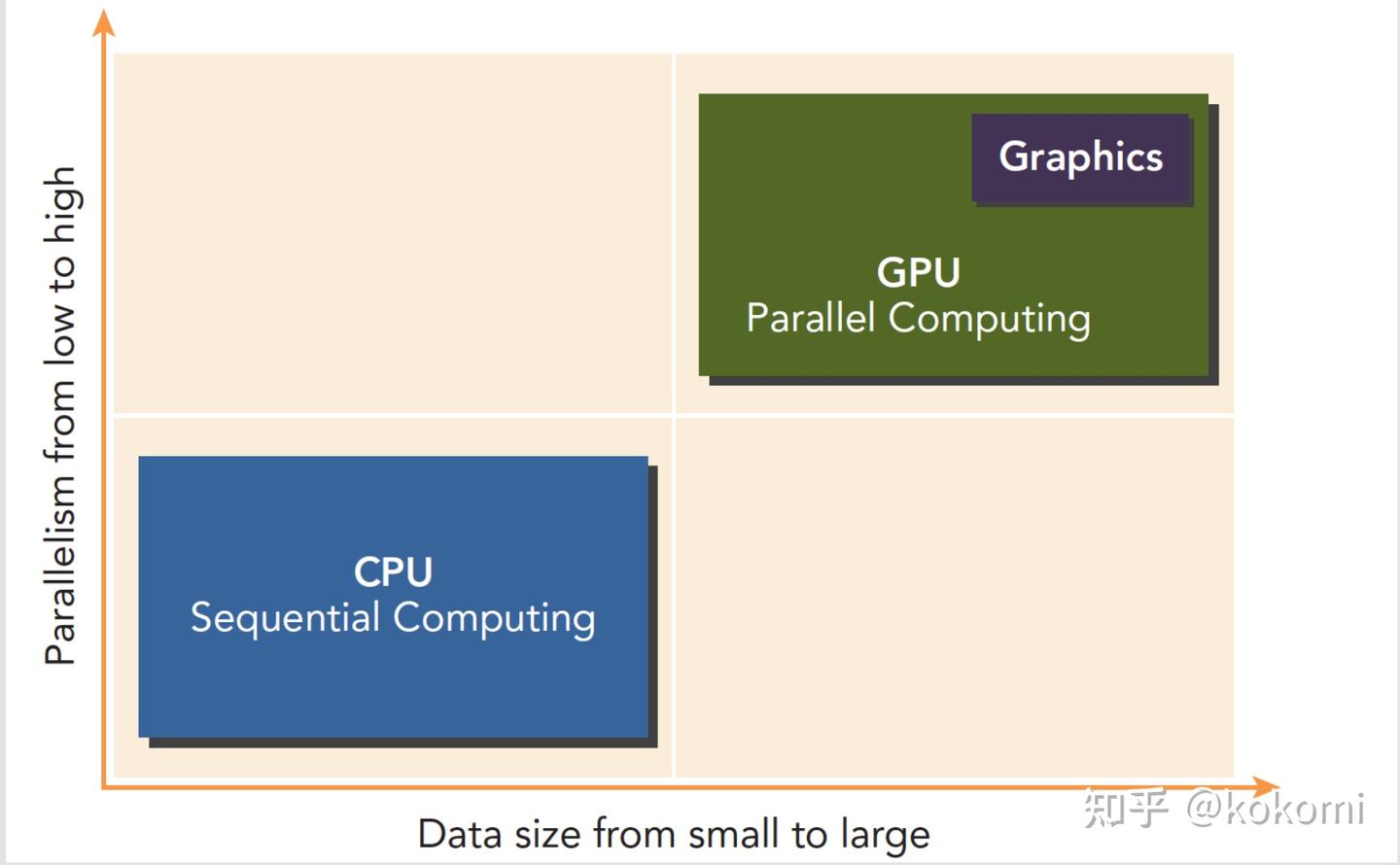
二、CPU 与 GPU 架构差异
- CPU:少量复杂核心,强调低延迟,适合复杂逻辑与串行任务。
- GPU:成百上千个轻量核心(SM 结构),强调高吞吐,适合数据并行。
- 通信方式:通过 PCIe 总线连接,数据传输可能成为性能瓶颈
三、CUDA 平台概述
- 定位:基于 NVIDIA GPU 的完整计算平台(硬件 + 软件 + 工具链)。
- 语言支持:CUDA C (ANSI C 扩展,新增关键字、API)
- 平台系列:
- Tegra → 嵌入式
- GeForce → 消费级图形、游戏
- Quadro → 专业图形工作站
- Tesla → 高性能计算(HPC)
- 性能指标:
- CUDA 核心数
- GPU 显存大小
- 峰值计算能力 (GFLOPS)
- 内存带宽
四、CUDA 架构 & 计算能力
- 计算能力 (Compute Capability) → 标记 GPU 架构代际
- 1.x Tesla
- 2.x Fermi
- 3.x Kepler
- 4.x Maxwell
- 5.x Pascal
- 6.x Volta
五、CUDA 编程模型
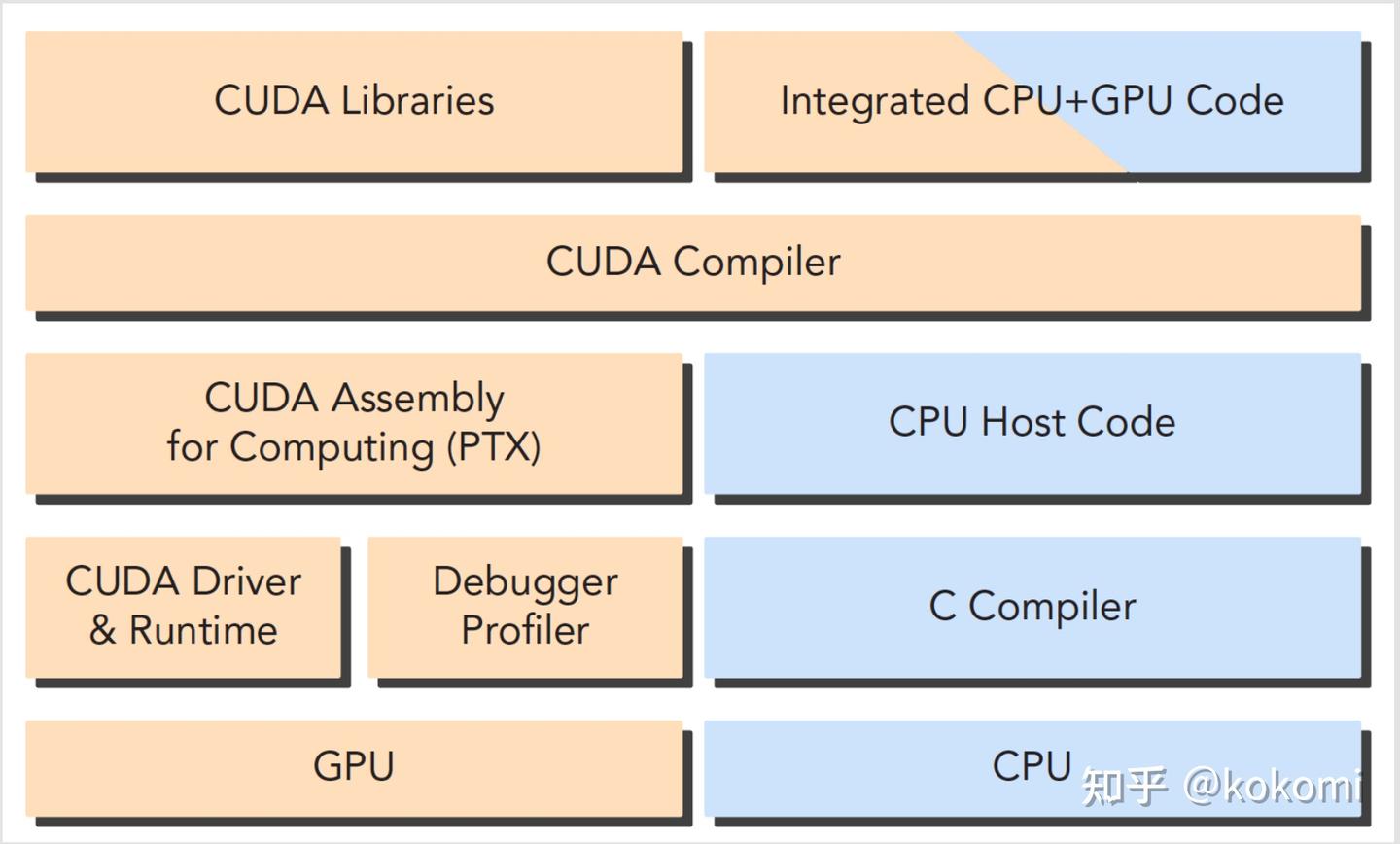
- 代码分两部分:
- Host 端(CPU):控制、数据传输
- Device 端(GPU):核函数计算
- 关键语法:
__global__→ 声明核函数<<<...>>>→ 启动核函数时配置执行参数cudaDeviceReset()→ 同步 GPU 与 CPU,保证 GPU 完成计算
- 典型程序流程:
- 分配 GPU 内存
- 主机 → 设备数据传输
- 执行核函数(GPU 计算)
- 设备 → 主机传回结果
- 释放内存
六、第一个CUDA程序:Hello World!
#include <stdio.h>普通的 C 头文件,说明CUDA C 是基于 C 的扩展,所以大部分 C 语法、库都能用。
__global__ void hello_world(void) {
printf("GPU: Hello world!\n");
}核函数(Kernel Function)
__global__:CUDA 关键字,告诉编译器这是一个“核函数”,即在 GPU 设备端执行。- 函数定义规则:
- 只能用
void返回值(通常不返回值,结果写进内存)。 - 可以带参数(后面学习数据传输时会用到)。
- 只能用
- 内容:这就是 GPU 干的活。在这里,简单地
printf,以后就换成矩阵加法、图像处理等。 - 重点理解:
- 写法很像普通函数,但运行在 GPU 上。
- 一个核函数会被 成千上万个线程同时执行(这里是 10 个线程)。
int main() {
printf("CPU: Hello world!\n");主机端代码(Host Code)
- 这是普通的 C 主程序,运行在 CPU 上。
- 作用:控制 GPU,做数据准备、调用核函数、取回结果。
- 在 CUDA 程序里,CPU 是“指挥官(host)”,GPU 是“士兵(device)”。
hello_world<<<1,10>>>();启动核函数
- CUDA 扩展语法
<<<...>>>,称为 执行配置(Execution Configuration)。- 格式:
kernel_name<<<numBlocks, threadsPerBlock>>>(args...);
-
- numBlocks:多少个线程块 (Block)
- threadsPerBlock:每个线程块多少个线程 (Thread)
- 在这个例子里:
<<<1,10>>>= 1 个 Block,每个 Block 有 10 个线程 → 总共 10 个线程并行执行。 - 结果:这行代码会让 GPU 同时启动 10 个线程,每个线程都执行一次
hello_world()。
cudaDeviceReset(); // 保证 GPU 输出完成同步与收尾
- 为什么要写?
CUDA 默认 CPU 和 GPU 异步执行 → CPU 把任务交给 GPU 后立刻往下跑,不会等 GPU 完成。
如果不加cudaDeviceReset(),CPU 可能在 GPU 打印前就退出,导致 GPU 的结果丢失。 - 这行函数会强制等待 GPU 完成,并清理 GPU 状态。
return 0;
}CUDA 程序通用蓝图(新手必须记住的 5 大步骤)
无论是 Hello World 还是复杂的矩阵运算,CUDA 程序几乎都遵循这个范式:
- 主机端准备 (CPU)
#include需要的库- 定义数据,分配 CPU 内存
- 分配 GPU 内存 (
cudaMalloc) - 把数据从 CPU 传给 GPU (
cudaMemcpy)
- 编写核函数 (GPU)
- 用
__global__修饰 - 核函数只描述 单个线程要干的事
- GPU 会有成千上万个线程一起跑这段代码
- 启动核函数
- 用
<<<gridDim, blockDim>>>配置线程数量 - Grid(网格) = 线程块的集合
- Block(线程块) = 线程的集合
- 每个线程用内置变量
threadIdx、blockIdx来确定自己负责的数据
- 收尾与结果传回
- GPU 执行完毕 → 把结果传回 CPU (
cudaMemcpy) - 释放 GPU 内存 (
cudaFree)
- 同步和错误处理
- 需要同步 (
cudaDeviceSynchronize或cudaDeviceReset) - 任何 CUDA API 调用后建议加错误检查
对比总结
- CPU 程序:写主函数,顺序执行。
- CUDA 程序:两部分 →
- Host 代码(控制 + 数据传输)
- Device 代码(核函数,海量线程并行)
- 思考模式变化:不再写“一个任务”,而是写“单个线程该干什么”,剩下交给 GPU 并行调度。
CPU(main) ----控制/数据----> GPU(核函数)
| |
|--- printf("CPU...") |--- 每个线程 printf("GPU...")
|--- 配置 <<<Grid,Block>>> |
|--- 同步等待 |
七、CPU vs GPU 线程模型
- CPU 线程:重量级,切换开销大
- GPU 线程:轻量级,成千上万,切换几乎无开销
- 设计差异:
- CPU → 降低延迟
- GPU → 提高吞吐量
八、性能关键点
- 数据局部性:
- 空间局部性(访问相邻数据)
- 时间局部性(数据复用频率)
- CUDA 性能模型:
- 线程层次结构(Grid、Block、Thread)
- 内存层次结构(寄存器、共享内存、全局内存)
九、CUDA 开发工具
- Nsight IDE(集成开发环境)
- CUDA-GDB(调试器)
- Visual Profiler / Nsight Systems(性能分析)
- CUDA-MEMCHECK(内存调试)
- GPU 管理工具

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)