【昇腾CANN训练营·算法篇】图计算的艺术:基于Ascend C实现GNN核心算子Scatter-Gather与消息传递
摘要:图神经网络(GNN)的核心计算范式是消息传递(Message Passing),通过边表(Edge Index)实现节点间的信息传递。关键操作为Gather(收集源节点特征)和Scatter(累加到目标节点),需使用原子操作避免写冲突。AscendC实现时采用边中心并行策略,性能优化重点包括:1)对边索引按目标节点排序以减少原子冲突;2)将稀疏图计算转化为SpMM。优化图数据局部性是提升GN
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

前言
在科学计算(如蛋白质预测 AlphaFold)和社交网络分析中,图神经网络 (GNN) 是绝对的主角。 GNN 的核心范式是 Message Passing(消息传递):
$$h_v^{(k)} = \text{Update} \left( h_v^{(k-1)}, \text{Aggregate} ( \{ h_u^{(k-1)} | u \in \mathcal{N}(v) \} ) \right)$$
翻译成人话就是:每个节点收集邻居的信息,更新自己。
在工程实现上,我们通常不使用邻接矩阵(太稀疏,浪费显存),而是使用 边表 (Edge Index, COO格式)。这意味着我们需要遍历每一条边,把源节点(Source)的信息“发”给目标节点(Target)。
这就涉及到了我们在第四十三期学过的两个原子操作的组合:先 Gather(抓取源节点特征),再 Scatter(累加到目标节点)。
一、 核心图解:信鸽传书
GNN 的计算过程就像是无数只信鸽在节点之间飞来飞去。
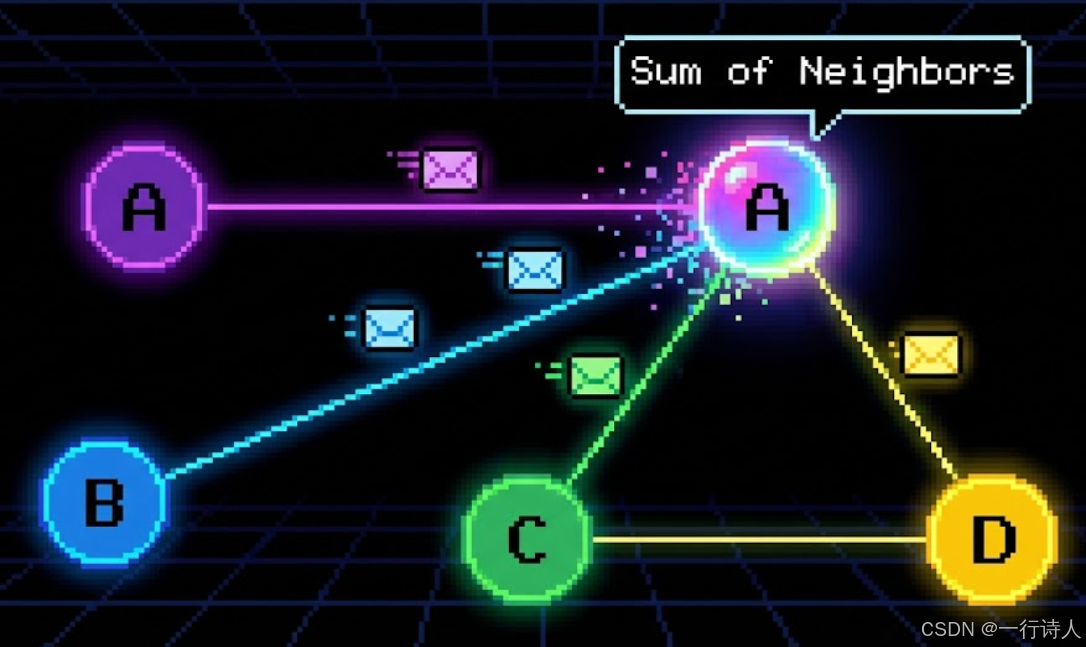
二、 算法映射:Scatter-Gather 范式
假设我们有 $N$ 个节点,$E$ 条边。 输入:
-
x: 节点特征矩阵 $[N, D]$。 -
edge_index: 边索引 $[2, E]$。第一行是 Source ID,第二行是 Target ID。
计算流程(以 $Sum$ 聚合为例):
-
Loop over Edges:遍历每一条边 $e = (u, v)$。
-
Gather: 根据 $u$ (Source ID) 从
x中读取特征 $h_u$。 -
Scatter: 将 $h_u$ 原子累加到
out[v](Target ID) 中。
三、 实战:Ascend C 实现 MessagePassing
3.1 Kernel 类定义
我们需要处理的是 以边为中心 (Edge-Centric) 的并行。
class KernelGNN {
public:
__aicore__ inline void Init(GM_ADDR x, GM_ADDR edge_index, GM_ADDR out,
uint32_t num_edges, uint32_t feature_dim) {
// ... Init ...
// Tiling 策略:通常按"边"的数量切分
// 每个 Core 处理一部分边
this->edgeLen = num_edges;
this->featDim = feature_dim;
}
__aicore__ inline void Process() {
// 循环处理边的分块
for (int i = 0; i < tileNum; i++) {
Compute(i);
}
}
};
3.2 Compute 核心逻辑
__aicore__ inline void Compute(int32_t i) {
// 1. 搬运 Edge Index 到 UB
// 假设一次处理 128 条边
LocalTensor<int32_t> srcIdx = inQueueSrc.DeQue<int32_t>();
LocalTensor<int32_t> dstIdx = inQueueDst.DeQue<int32_t>(); // 也就是 target node index
// 2. 准备特征 Buffer
LocalTensor<float> featLoc = tmpQueue.AllocTensor<float>();
// 3. Gather (收集源节点特征)
// 根据 srcIdx 从 xGm (Global Memory) 中抓取特征到 featLoc
// featLoc shape: [128, featDim]
// Ascend C Gather 接口示意 (具体参数视芯片版本)
// 如果没有直接的高阶 Gather,需要循环调用 DataCopy
Gather(featLoc, xGm, srcIdx, 128);
// 4. Message Computation (可选)
// 如果是 GCN,这里直接传特征。
// 如果是 GAT,这里需要算 Attention Score 并乘在 featLoc 上。
// Mul(featLoc, featLoc, attn_scores, ...);
// 5. Scatter (聚合到目标节点)
// 将 featLoc 的数据累加到 outGm 的 dstIdx 位置
// 必须开启原子加,因为不同的边可能指向同一个 target node
SetAtomicAdd<float>();
// Scatter 接口示意,将 featLoc 数据分散写回 outGm
Scatter(outGm, featLoc, dstIdx, 128);
SetAtomicNone();
// ... 资源释放 ...
}
四、 性能优化的“胜负手”
GNN 算子是典型的 Latency Bound(延迟受限)和 Bandwidth Bound(带宽受限),因为全是随机访存。
4.1 索引排序 (Sorting Indices)
如果 edge_index 是乱序的(如 Source: [1, 1000, 5]),Gather 效率极低。 优化策略:在 Host 侧或预处理阶段,对 edge_index 进行 Reordering(重排)。
-
按 Source 排序:优化
Gather效率(读连续)。 -
按 Target 排序:优化
Scatter效率(写连续,且减少原子冲突)。 通常推荐按 Target 排序,因为写冲突(Atomic Add)的代价比读延迟更高。
4.2 稀疏矩阵乘法 (SpMM)
如果图结构是静态的,可以将 Scatter-Gather 转化为 SpMM (Sparse Matrix-Matrix Multiplication)。 $A \times X = Y$ 其中 $A$ 是稀疏邻接矩阵,$X$ 是稠密特征矩阵。 利用 Cube 单元的稀疏计算能力(如果有)或者专门优化过的 SpMM Kernel,通常比通过 Vector 逐条边处理要快得多。
五、 总结
图计算是 AI 算子开发中“最狂野”的领域。
-
思维模式:从 Tensor 视角切换到 Graph 视角(点、边、邻居)。
-
核心操作:Gather(读邻居)+ Scatter(写中心)。
-
性能关键:局部性(Locality)。谁能把图数据排布得更紧凑,谁就能赢得性能。
掌握了 GNN 算子,你就有能力去优化 AlphaFold、推荐系统等前沿模型。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 22
22 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)