
昇腾 910B 部署 vLLM-ascend 实战:从环境踩坑到推理部署
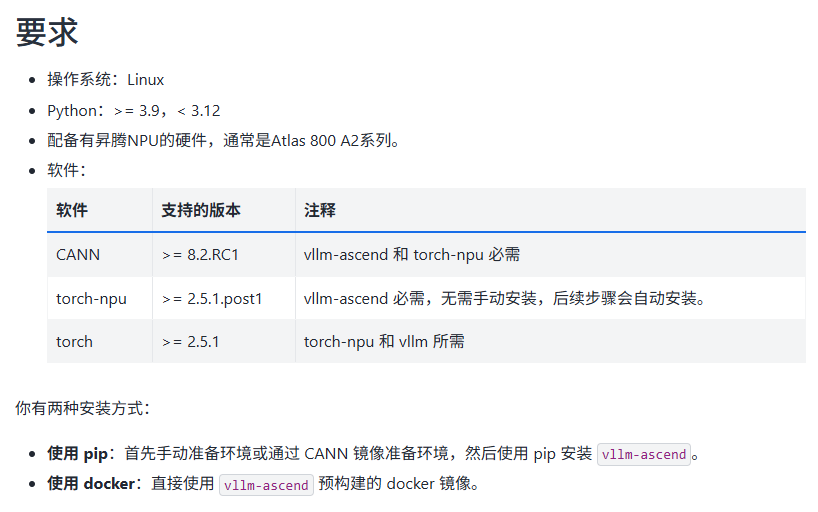
在昇腾 910B 平台上部署 vLLM-ascend 是一项涉及硬件、驱动、Python 版本和框架依赖的系统工程。核心实践经验总结如下环境选择至关重要:必须使用 Python >= 3.9 的环境(如 GitCode 的py3.11镜像)才能满足vllm的版本要求。依赖配置需手动介入:即使在预装 CANN 的镜像中,也需要为venv虚拟环境手动配置 CANN 工具链和环境变量。版本匹配是关键vl
昇腾 910B 部署 vLLM-ascend 实战:从环境踩坑到推理部署

写在最前面
版权声明:本文为原创,遵循 CC 4.0 BY-SA 协议。转载请注明出处。
vLLM 凭借 PagedAttention 已成为大模型推理的标准配置。要在国产昇腾 NPU 上高效运行 vLLM,则需要依赖 vllm-ascend 适配层。
通过一整个下午的尝试,在 GitCode 免费昇腾 910B 环境上部署成功了 vLLM-ascend。
本文详细记录了完整实战过程,重点剖析了环境选择、CANN 依赖配置、以及版本兼容性等关键问题,提供了一条可复现的高性能部署路径。
一、 核心挑战:为何选择 vLLM-ascend?
在国产算力平台上部署大模型,最大的挑战往往在于软件生态的适配效率。传统的部署方案(如手动转换 OM 模型、编写 ACL 接口)开发周期长、效率低下。
vLLM-ascend 的出现解决了这一痛点:它使开发者能继续使用熟悉的 vLLM Python 接口和 OpenAI 服务模式,同时在底层无缝调用昇腾 NPU 算力,实现了开发效率与运行性能的统一。
二、 部署实战:关键步骤与决策点
本文的部署侧重于详解 vLLM 模型迁移至昇腾平台的关键步骤,包括昇腾驱动适配、推理服务启动等。
步骤一:环境准备与“第一个关键决策”
我们使用 GitCode 提供的免费昇腾 Notebook 环境
https://gitcode.com/dashboard
图 1:通过 GitCode 仪表盘进入 Notebook 环境。
在选择“容器镜像”时,我们遇到了第一个关键决策点。
- 错误选项:
euler2.9-py38-torch2.1.0...镜像。 - 正确选项:
ubuntu22.04-py3.11-cann8.2.rc1...镜像。
图 2:选择正确的 py3.11 容器镜像。
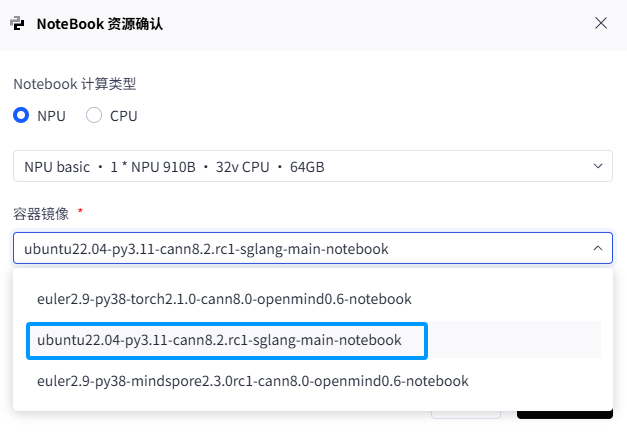
原因:
在后续的安装中我们发现,vllm 的 0.9.0 以上版本普遍要求 Python >= 3.9。而 euler2.9-py38… 镜像的 Python 3.8 环境无法满足这一核心依赖,会导致后续 pip install 失败。因此,选择 py3.11 镜像是成功部署 vLLM-ascend 的前提。(详细分析见第四章)
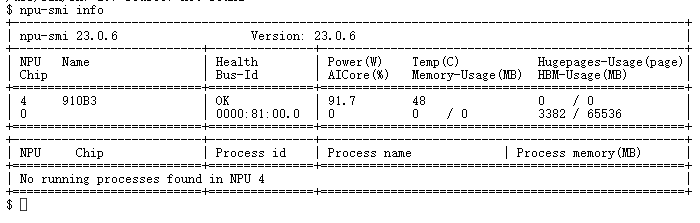
步骤二:NPU 环境“体检”
进入 py3.11 环境后,我们首先通过 npu-smi info 命令检查硬件状态,确保 Ascend 910B 被正确识别且状态为 OK。
图 3:npu-smi 命令显示 910B3 硬件状态正常,Health 状态为 OK。
步骤三:核心组件安装与“第二个关键决策”
在安装 vllm 之前,我们必须配置好对应的 CANN (Compute Architecture for Neural Networks) 工具包。
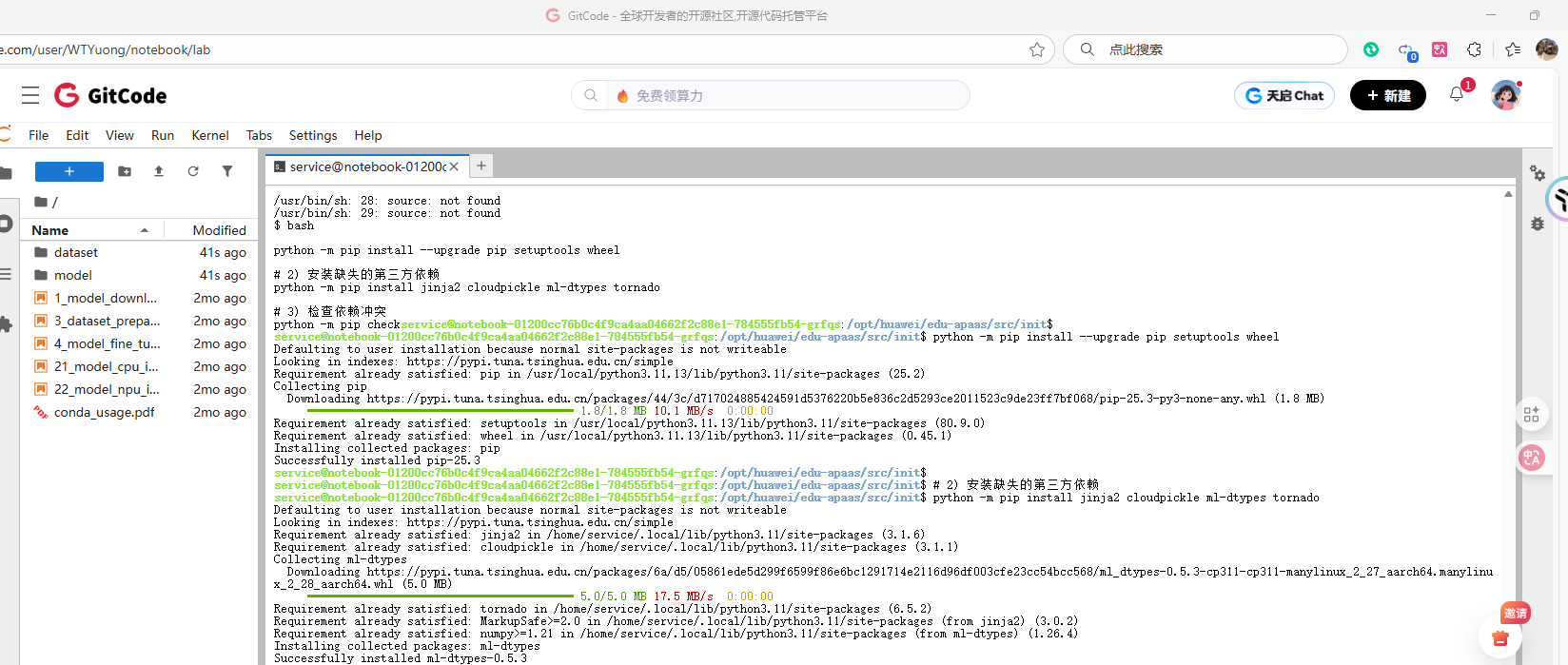
1. 关键踩坑点:bash 环境
GitCode Notebook 默认的执行环境并非标准 bash shell,直接运行 python -m venv ... 会导致 “no such option: -m” 错误。
解决方案:必须先在 Notebook Cell 中输入 bash 命令,进入一个真正的 shell 环境,后续所有安装命令都应在该 bash 环境下执行。
2. 配置虚拟环境与 CANN
我们首先创建一个独立的 Python 虚拟环境,并安装 CANN 8.2 RC1。
深度分析:
虽然我们的镜像名称中已包含 cann8.2.rc1,但在虚拟环境中,我们仍需手动安装或配置 CANN 相关的依赖和环境变量。这是因为 Python 虚拟环境(venv)默认是隔离的,vllm-ascend 在编译时需要能明确找到 CANN 的头文件和库。
以下命令展示了完整的安装流程:
- 进入 Bash:
bash - 创建****虚拟环境:
python -m venv vllm-ascend-env - 激活环境:
source vllm-ascend-env/bin/activate - 安装****CANN:下载
toolkit,kernels-910b,nnal三个包,并--full或--install安装。 - 设置****环境变量:
source /usr/local/Ascend/ascend-toolkit/set_env.sh。
图 4:安装 CANN 过程中,需要输入 “Y” 同意协议。
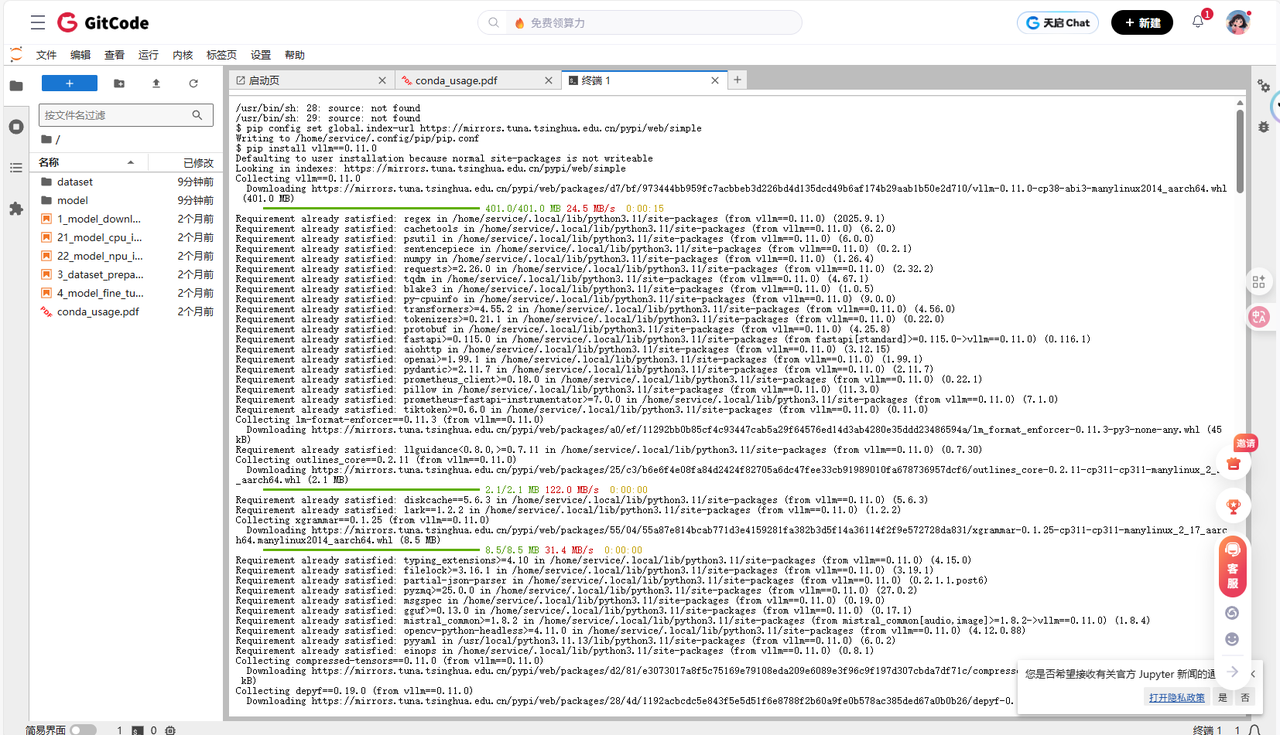
3. 安装 vLLM 与 vLLM-ascend
在配置好 CANN 和 Python 3.11 环境后,我们终于可以安装 vLLM 本体。
常见问题:
如果直接从 PyPI 安装 vllm-ascend 的较新版本(如 0.11.0rc1),可能会遇到 “No matching distribution found” 的错误。这是因为 PyPI 上的 vllm-ascend 包版本是有限的。
解决方案:
根据昇腾官方文档,我们选择安装经过验证的 0.9.1 版本。
Bash
# 配置 pip 源
pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
pip install --upgrade pip
# 安装 vllm 及其昇腾适配包
pip install vllm==0.9.1
pip install vllm-ascend==0.9.1
图 5:在 Python 3.11 环境下成功安装 vllm==0.9.1。
三、 环境测试:运行推理服务
安装完成后,我们使用一个简单的脚本来验证 vLLM-ascend 是否能成功调用 NPU 进行推理。
Python
import os
os.environ["VLLM_USE_V1"] = "1"
from vllm import LLM, SamplingParams
# 使用一个轻量级模型进行快速测试
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
# 配置采样参数
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# 加载模型 (注意:模型会下载到本地)
llm = LLM(model="Qwen/Qwen2.5-0.5B-Instruct")
# 执行推理
outputs = llm.generate(prompts, sampling_params)
# 打印结果for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
输出结果为:
INFO 02-18 08:49:58 __init__.py:28] Available plugins for group vllm.platform_plugins:
INFO 02-18 08:49:58 __init__.py:30] name=ascend, value=vllm_ascend:register
INFO 02-18 08:49:58 __init__.py:32] all available plugins for group vllm.platform_plugins will be loaded.
INFO 02-18 08:49:58 __init__.py:34] set environment variable VLLM_PLUGINS to control which plugins to load.
INFO 02-18 08:49:58 __init__.py:42] plugin ascend loaded.
INFO 02-18 08:49:58 __init__.py:174] Platform plugin ascend is activated
INFO 02-18 08:50:12 config.py:526] This model supports multiple tasks: {'embed', 'classify', 'generate', 'score', 'reward'}. Defaulting to 'generate'.
INFO 02-18 08:50:12 llm_engine.py:232] Initializing a V0 LLM engine (v0.7.1) with config: model='./Qwen2.5-0.5B-Instruct', speculative_config=None, tokenizer='./Qwen2.5-0.5B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=32768, download_dir=None, load_format=auto, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=npu, decoding_config=DecodingConfig(guided_decoding_backend='xgrammar'), observability_config=ObservabilityConfig(otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=0, served_model_name=./Qwen2.5-0.5B-Instruct, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=False, chunked_prefill_enabled=False, use_async_output_proc=True, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"splitting_ops":[],"compile_sizes":[],"cudagraph_capture_sizes":[256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":256}, use_cached_outputs=False,
Loading safetensors checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 5.86it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 5.85it/s]
INFO 02-18 08:50:24 executor_base.py:108] # CPU blocks: 35064, # CPU blocks: 2730
INFO 02-18 08:50:24 executor_base.py:113] Maximum concurrency for 32768 tokens per request: 136.97x
INFO 02-18 08:50:25 llm_engine.py:429] init engine (profile, create kv cache, warmup model) took 3.87 seconds
Processed prompts: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 8.46it/s, est. speed input: 46.55 toks/s, output: 135.41 toks/s]
Prompt: 'Hello, my name is', Generated text: " Shinji, a teenage boy from New York City. I'm a computer science"
Prompt: 'The president of the United States is', Generated text: ' a very important person. When he or she is elected, many people think that'
Prompt: 'The capital of France is', Generated text: ' Paris. The oldest part of the city is Saint-Germain-des-Pr'
Prompt: 'The future of AI is', Generated text: ' not bright\n\nThere is no doubt that the evolution of AI will have a huge'
四、性能加速
五、 深度复盘:Python 3.8 失败路径与依赖分析
在第二章中,我们强调了选择 py3.11 镜像的重要性。本章将详细复盘如果错选了 py3.8 镜像(euler2.9-py38...)会导致怎样的失败,以及如何定位问题根源。
1. 故障现象:pip install 失败
在 py38 环境中,尝试安装 vllm0.9.0 或 vllm-ascend0.9.0 时,pip 会直接报错:
ERROR: Could not find a version that satisfies the requirement vllm==0.9.0…
ERROR: No matching distribution found for vllm==0.9.0…
图 6:在 Py3.8 环境下安装 vllm 0.9.0 失败,提示找不到匹配版本。

2. 疑点排查:是镜像问题还是版本问题?
初始假设:这个报错最直观的猜想是,pip 配置的清华镜像(mirrors.tuna.tsinghua.edu.cn)索引不全或同步延迟。
排查验证:为了验证这个假设,我们绕过镜像,直接用 Python 查询 PyPI 官方 API,检查包是否存在。
Python
# 查询 PyPI 上的 vllm 所有版本import json
import urllib.request
data = json.load(urllib.request.urlopen('https://pypi.org/pypi/vllm/json'))
print(sorted(data['releases'].keys()))
图 7:直接查询 PyPI 证实,0.9.0 版本是真实存在的。

分析:
查询结果证实,PyPI 上明确存在 0.11.0 版本。同理,vllm-ascend 的 0.11.0rc1 版本也存在。这推翻了“镜像不同步”或“包不存在”的假设。
3. 定位根源:Python 版本不兼容
pip 在报告 “No matching distribution” 时,不仅会检查包名和版本号,还会检查当前环境(如 Python 版本、系统架构)是否满足包的元数据(requires_python)要求。
结论:
我们查阅 vllm 0.10.0 以上版本的 pyproject.toml 文件发现,其元数据中明确要求:
requires_python = “>=3.9, ❤️.12”
euler2.9-py38 镜像的 Python 3.8 环境不满足 >=3.9 的最低要求。因此,pip 判定 vllm==0.11.0 与当前环境不兼容,从而给出了“找不到版本”的错误。
复盘总结:这个踩坑过程清晰地表明,环境选择是部署的第一道关卡。对于 vllm-ascend 这类前沿框架,必须优先选择 Python 3.9+ 的基础环境。
4.报错: Failed to import from vllm._C
运行代码时报错
$ python example.py
INFO 11-12 19:04:16 [importing.py:53] Triton module has been replaced with a placeholder.
INFO 11-12 19:04:19 [__init__.py:243] No platform detected, vLLM is running on UnspecifiedPlatform
WARNING 11-12 19:04:20 [_custom_ops.py:21] Failed to import from vllm._C with ModuleNotFoundError("No module named 'vllm._C'")
Traceback (most recent call last):
File "/opt/huawei/edu-apaas/src/init/example.py", line 16, in <module>
llm = LLM(model="Qwen/Qwen2.5-0.5B-Instruct")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/service/.local/lib/python3.11/site-packages/vllm/utils.py", line 1161, in inner
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/home/service/.local/lib/python3.11/site-packages/vllm/entrypoints/llm.py", line 247, in __init__
self.llm_engine = LLMEngine.from_engine_args(
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/service/.local/lib/python3.11/site-packages/vllm/v1/engine/llm_engine.py", line 130, in from_engine_args
vllm_config = engine_args.create_engine_config(usage_context)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/service/.local/lib/python3.11/site-packages/vllm/engine/arg_utils.py", line 1098, in create_engine_config
device_config = DeviceConfig(device=self.device)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<string>", line 4, in __init__
File "/home/service/.local/lib/python3.11/site-packages/vllm/config.py", line 2119, in __post_init__
raise RuntimeError(
RuntimeError: Failed to infer device type, please set the environment variable `VLLM_LOGGING_LEVEL=DEBUG` to turn on verbose logging to help debug the issue.
[ERROR] 2025-11-12-19:04:22 (PID:180237, Device:-1, RankID:-1) ERR99999 UNKNOWN applicaiton exception
通过上网查询资料,发现大概率是pip包版本之间的冲突,使用如下命令可以进行检测是否有包版本与vllm相关包形成了冲突:
pip check
# 报错
$ pip check
op-compile-tool 0.1.0 requires getopt, which is not installed.
op-compile-tool 0.1.0 requires inspect, which is not installed.
op-compile-tool 0.1.0 requires multiprocessing, which is not installed.
opencv-python-headless 4.12.0.88 has requirement numpy<2.3.0,>=2; python_version >= "3.9", but you have numpy 1.26.4.
vllm 0.8.5.post1+empty has requirement xgrammar==0.1.18; platform_machine == "x86_64" or platform_machine == "aarch64", but you have xgrammar 0.1.23.
结果就是vllm、vllm-flash-attn、vllm-nccl-cu12这些包对应的torch版本为2.3.1,而我的torch是最新版本2.4.0,卸载掉重新安装好对应正确版本的包即可。
总结
在昇腾 910B 平台上部署 vLLM-ascend 是一项涉及硬件、驱动、Python 版本和框架依赖的系统工程。
核心实践经验总结如下:
- 环境选择至关重要:必须使用 Python >= 3.9 的环境(如 GitCode 的
py3.11镜像)才能满足vllm的版本要求。 - 依赖配置需手动介入:即使在预装 CANN 的镜像中,也需要为
venv虚拟环境手动配置 CANN 工具链和环境变量。 - 版本匹配是关键:
vllm和vllm-ascend的版本需要严格匹配,并选择 PyPI 上实际存在的版本(如0.9.1)进行安装。
通过遵循上述步骤,可以成功在昇腾 NPU 上搭建起 vLLM 高性能推理服务,为后续的性能调优和“0Day模型”适配打下坚实基础。
参考文档
- vLLM-ascend 官方安装指南
hello,我是 是Yu欸 。如果你喜欢我的文章,欢迎三连给我鼓励和支持:👍点赞 📁 关注 💬评论,我会给大家带来更多有用有趣的文章。
原文链接 👉 ,⚡️更新更及时。
欢迎大家点开下面名片,添加好友交流。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 32
32 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)