【Big Data】Apache Flink 分布式计算框架的崛起
在大数据处理领域,实时性与准确性的平衡始终是技术突破的核心方向。Apache Flink 作为当前最受关注的分布式计算框架之一,以 “流批一体” 的设计理念重新定义了大数据处理的范式。本文将从技术本质出发,系统解析 Flink 的诞生背景、架构设计、核心能力及实践方法,帮助技术开发人员全面掌握这一高性能计算框架。
Apache Flink是一个分布式计算框架,专注于无边界和有边界数据流的有状态计算。它既支持低延迟的实时流处理,又能提供高吞吐的批处理能力,实现了真正的流批统一。Flink的核心优势在于其原生流处理架构(Native Streaming)和Exactly-Once精确一次容错机制,使其在实时计算领域成为事实上的标准。随着Flink 2.0版本的发布,其云原生支持和流式湖仓架构进一步强化了其在大数据生态系统中的地位。Flink不仅解决了传统流处理框架在低延迟、高吞吐和精确一次保证方面的不足,还通过与Paimon等数据湖技术的深度集成,为实时数据处理提供了全新的可能性。

一、Flink的诞生背景与由来
1.1 大数据处理的困境
在Flink出现之前,大数据处理主要分为两种模式:离线批处理和实时流处理。这两种模式存在明显的互补性不足:
-
批处理模式:以Hadoop MapReduce为代表,处理静态数据集,延迟高(通常小时级),但吞吐量大,适合大规模数据分析。然而,它无法满足实时数据处理的需求,且难以应对数据的后续更新。
-
流处理模式:以Apache Storm为代表,处理动态数据流,延迟低(毫秒级),但吞吐量有限,且不支持复杂的状态管理和容错机制。更严重的是,它缺乏对乱序数据和事件时间的处理能力。
-
架构复杂性:企业通常需要同时维护批处理和流处理两套系统,通过流计算引擎(如Spark Streaming或Flink)将数据从流处理系统导出到批处理系统进行分析。这种架构虽然在一定程度上满足了需求,但带来了高昂的运维成本和数据一致性风险。
1.2 Flink的起源
Flink的前身是德国柏林工业大学(TU Berlin)发起的研究项目Stratosphere: Information Management on the Cloud,该项目于2010年获得德国研究基金会资助。Stratosphere项目的核心目标是设计一个能够同时处理批处理和流处理的统一计算引擎,这一理念后来成为Flink的核心设计哲学。
2014年4月,Stratosphere项目的代码被贡献给Apache软件基金会,成为Apache基金会孵化器项目。初期参与该项目的核心成员均是Stratosphere曾经的核心成员,包括柏林工业大学、柏林洪堡大学和哈索普拉特纳研究所的多位研究人员。2014年12月,该项目正式成为Apache软件基金会顶级项目,并更名为Flink(德语中意为"快"和"灵敏")。
1.3 阿里巴巴的推动
Flink的快速发展离不开阿里巴巴的贡献。2015年,阿里引入Flink并将其内部版本命名为Blink(意为"一眨眼,所有东西都计算好了!")。阿里对Flink进行了深度改造,解决了其在大规模数据场景下的性能瓶颈。2017年双11期间,Blink成功支持了全集团所有交易数据的实时计算任务,验证了Flink在大规模数据处理场景中的可行性。
2019年,阿里向Apache Flink社区贡献了Blink项目,涉及超过150万行核心代码。这一贡献极大促进了Flink社区的发展,使其在全球范围内获得广泛应用。阿里还收购了Flink的创始公司DataArtisans,并于之后更名为Ververica,进一步推动Flink的商业化发展。
二、Flink解决的核心问题
2.1 实时计算的低延迟与高吞吐
Flink通过原生流处理架构解决了传统流处理框架(如Spark Streaming)在低延迟和高吞吐之间的权衡问题:
-
低延迟:Flink采用逐条处理数据的方式,而非Spark Streaming的微批处理(Micro-batch)模式。这一设计使得Flink能够实现毫秒级的处理延迟,满足实时应用场景的需求。
-
高吞吐:Flink通过分布式架构和状态本地化存储(State Locality)优化,实现了每秒数十万条数据的处理能力。在阿里巴巴的生产环境中,Flink任务能够处理每天数万亿的事件,应用维护几TB大小的状态。
2.2 精确一次(Exactly-Once)保证
Flink解决了传统流处理框架在数据一致性方面的不足:
-
容错机制:Flink采用基于Chandy-Lamport算法的分布式快照(Checkpoint)机制,通过barrier同步状态快照,实现Exactly-Once语义 。这一机制在保证数据一致性的同时,显著降低了容错的性能开销。
-
状态管理:Flink支持大规模状态管理(如TB级状态),并通过状态TTL(Time-To-Live)机制实现状态的自动清理 。这种设计使得Flink能够处理复杂的有状态计算任务,如实时推荐、欺诈检测等。
2.3 流批统一
Flink解决了大数据处理中架构冗余的问题:
-
统一计算引擎:Flink将批处理视为有边界数据流的特例,提供统一的计算引擎处理所有数据 。这种设计简化了系统架构,降低了运维成本。
-
统一API:Flink提供DataStream API(流处理)和DataSet API(批处理),两者在底层共享相同的执行引擎 。这种设计使得开发人员能够使用相同的编程模型处理不同类型的计算任务。
三、Flink的架构设计
3.1 整体架构概览
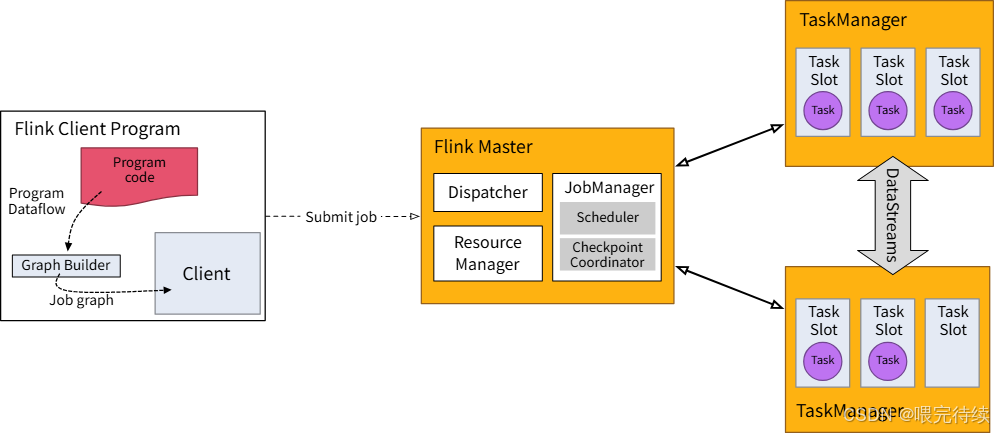
Flink采用主从架构,主要包括三个核心组件:JobManager、TaskManager和状态后端(StateBackend):
-
JobManager:负责作业的调度、Checkpoint协调和故障恢复。在高可用模式下,JobManager采用Raft协议实现主备切换,确保作业的持续运行 。
-
TaskManager:负责执行实际的计算任务,管理slot资源。每个TaskManager包含多个slot,每个slot可以执行一个子任务 。TaskManager通过反压机制(Backpressure)动态调整数据摄入速率,避免内存溢出。
-
状态后端:负责存储和管理任务状态。Flink支持多种状态后端,包括堆内内存、堆外内存和RocksDB等。状态后端的选择直接影响系统的性能和扩展性。
3.2 原生流处理引擎
Flink的核心竞争力在于其原生流处理引擎:
-
事件驱动模型:Flink采用事件驱动的处理模型,逐条处理数据,而非Spark Streaming的微批处理模式。这一设计使得Flink能够实现更低的处理延迟。
-
反压机制:Flink通过反压机制动态调整数据摄入速率,避免内存溢出。反压机制的核心是信用系统(Credit System),通过上下游算子之间的信用传递,实现流量控制 。
-
内存优化:Flink自动分配70%的堆空间用于数据处理,30%用于程序执行。这种内存管理策略显著提高了系统的吞吐量和稳定性。

3.3 Checkpoint容错机制
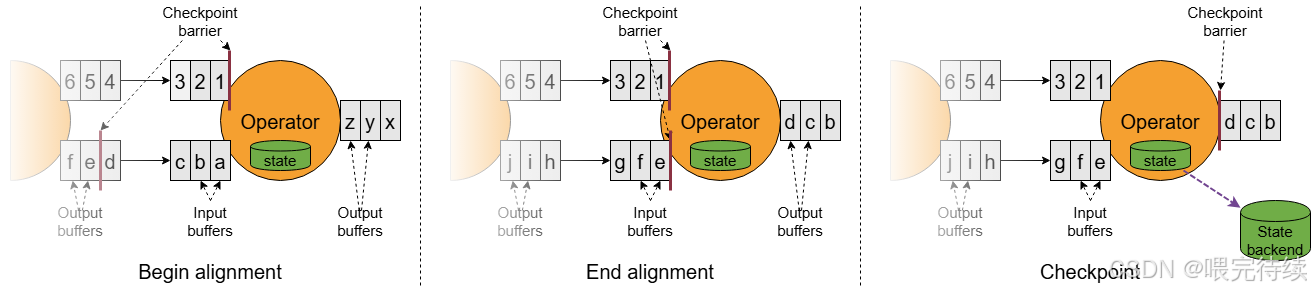
Flink的Checkpoint机制是其实现Exactly-Once语义的核心 :
-
异步快照算法:Flink采用基于Chandy-Lamport算法的异步改进版,通过barrier消息实现分布式快照 。barrier消息与普通数据共享同一通路,不会阻断数据的正常处理。
-
状态快照流程:Checkpoint协调器周期性触发快照,Source算子首先备份自身状态,然后生成barrier传递给下游算子 。下游算子收到barrier后触发自身状态快照,最终由Sink算子确认快照完成。
-
增量Checkpoint:Flink 2.0引入了增量Checkpoint机制,仅记录状态的变更部分,而非完整状态 。这一设计显著减少了Checkpoint的存储开销和恢复时间。
四、Flink的关键特性
4.1 事件时间处理与Watermark机制
Flink支持事件时间语义,能够处理乱序数据和延迟数据:
-
Watermark生成:Flink通过Watermark机制动态标记事件时间的进度 。Watermark的生成可以采用固定延迟(如
FixedAssigner)或基于统计的自适应延迟(BoundedOutOfOrderTimestamps)。 -
乱序处理:Flink允许设置最大允许的延迟时间(maxOutstandingEvents),超过该时间的事件将被视为迟到,不再参与计算 。这种设计使得Flink能够在处理乱序数据的同时保证结果的准确性。
-
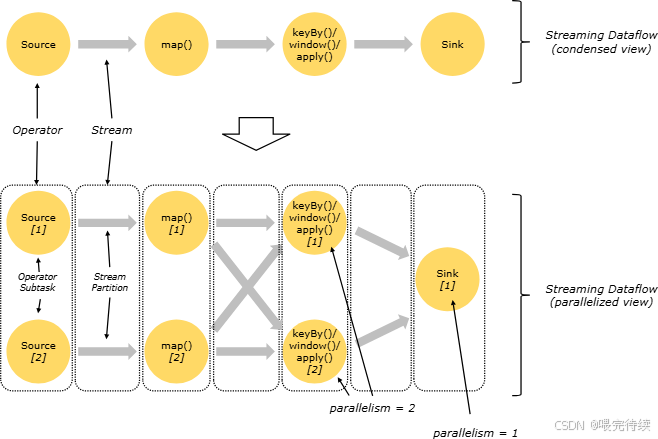
时间窗口操作:Flink支持滚动窗口、滑动窗口和会话窗口等多种窗口类型 。窗口操作可以基于事件时间、处理时间或注入时间,提供了灵活的时间语义处理能力 。
4.2 窗口操作与触发策略
Flink的窗口操作是其处理时间序列数据的核心能力:
-
触发策略:Flink支持三种触发策略:基于Watermark(事件时间)、基于元组个数(计数)和基于固定时间间隔(处理时间) 。用户还可以自定义触发策略,实现更复杂的窗口行为。
-
状态管理:Flink通过Keyed State和Operator State管理窗口聚合状态 。Keyed State与特定键关联,适用于按键分组的窗口操作;Operator State与算子实例关联,适用于全局窗口操作。
-
动态窗口:Flink支持动态窗口大小调整和窗口对齐,使得处理时间序列数据更加灵活 。在Flink SQL中,可以通过
TUMBLE、HOP和SESSION等函数定义不同类型的窗口 。
4.3 状态管理与容错机制
Flink的状态管理是其实现复杂流处理的核心能力:
-
状态后端:Flink支持多种状态后端,包括堆内内存、堆外内存和RocksDB等。状态后端的选择影响状态的存储位置和访问速度,进而影响系统的性能。
-
状态TTL:Flink支持状态TTL机制,能够自动清理过期状态 。状态TTL通过元数据标记状态的有效期,定期清理无效状态,避免状态无限增长。
-
容错机制:Flink的Checkpoint机制通过barrier同步状态快照,实现Exactly-Once语义 。在Flink 2.0中,增量Checkpoint和异步执行模型进一步降低了容错的性能开销。
五、Flink与同类产品对比
5.1 Flink vs Spark Streaming
| 特性 | Flink | Spark Streaming |
|---|---|---|
| 处理模式 | 原生流处理(Native Streaming)
3 |
微批处理(Micro-batch)
8 |
| 延迟 | 毫秒级
3 |
0.5-2秒
8 |
| 吞吐量 | 每秒数十万条
4 |
依赖批处理间隔
8 |
| 容错机制 | Checkpoint(Exactly-Once) | 批处理检查点(At-Least-Once)
8 |
| 状态管理 | 支持大规模状态(TB级)
4 |
依赖批处理状态
8 |
| 时间语义 | 支持事件时间、处理时间和注入时间 | 主要支持处理时间(最新支持事件时间)
8 |
| 窗口操作 | 支持滚动、滑动和会话窗口,可自定义触发策略 | 支持滚动和滑动窗口,触发策略有限
8 |
对比分析:Flink在低延迟和精确一次保证方面具有明显优势,适合实时应用场景;而Spark Streaming在批处理方面更为成熟,适合需要与Spark生态系统深度集成的场景。在吞吐量方面,两者都支持大规模数据处理,但Flink的原生流处理架构使其在高并发场景下表现更佳。
5.2 Flink vs Kafka Streams
| 特性 | Flink | Kafka Streams |
|---|---|---|
| 部署模式 | 需要独立集群
4 |
嵌入式部署(与Kafka集成) |
| 状态管理 | 支持多种状态后端(如RocksDB)
13 |
依赖Kafka日志存储
14 |
| 资源调度 | 支持动态资源分配 | 依赖Kafka分区数
14 |
| 容错机制 | Checkpoint(Exactly-Once) | 基于Kafka的补偿机制
14 |
| 扩展性 | 支持TB级状态,动态拆分
4 |
状态大小受限于Kafka分区数
14 |
| 适用场景 | 复杂流处理、大规模状态管理
4 |
微服务内实时处理、轻量级应用 |
对比分析:Kafka Streams以其轻量级和与Kafka的深度集成为优势,适合在微服务内实现简单的实时处理 ;而Flink提供了更强大的计算能力和更灵活的状态管理,适合处理复杂的流计算任务。在云原生支持方面,Flink 2.0的存算分离架构使其更适合大规模和动态扩展的场景。
5.3 Flink vs Samza
| 特性 | Flink | Samza |
|---|---|---|
| 处理模式 | 原生流处理
3 |
微批处理
8 |
| 状态管理 | 支持大规模状态
4 |
依赖Key-Value存储(如HBase)
4 |
| 容错机制 | Checkpoint(Exactly-Once) | 基于消息重放的容错
14 |
| 资源调度 | 支持动态资源分配 | 静态资源分配
14 |
| 时间语义 | 支持事件时间、处理时间和注入时间 | 主要支持处理时间
8 |
| 部署复杂度 | 较高(需独立集群)
4 |
较低(基于Kafka) |
对比分析:Samza以其与Kafka的深度集成和较低的部署复杂度为优势,适合在Kafka生态系统内实现简单的流处理 ;而Flink提供了更强大的计算能力和更灵活的状态管理,适合处理复杂的流计算任务。在云原生支持方面,Flink 2.0的存算分离架构使其更适合大规模和动态扩展的场景。
六、Flink的使用方法与最佳实践
6.1 部署与配置
Flink支持多种部署模式,包括Standalone、YARN、MESOS和Kubernetes等:
apiVersion: v1
kind: Pod
metadata:
name: flink-taskmanager
spec:
containers:
- name: flink
image: flink:2.0
resources:
limits:
memory: "8Gi"
cpu: "4"
requests:
memory: "4Gi"
cpu: "2"
env:
- name: TaskManager.memoryOffHeap.size
value: "2g"6.2 API使用示例
Flink提供了多种API,包括Java、Scala和Python等 :
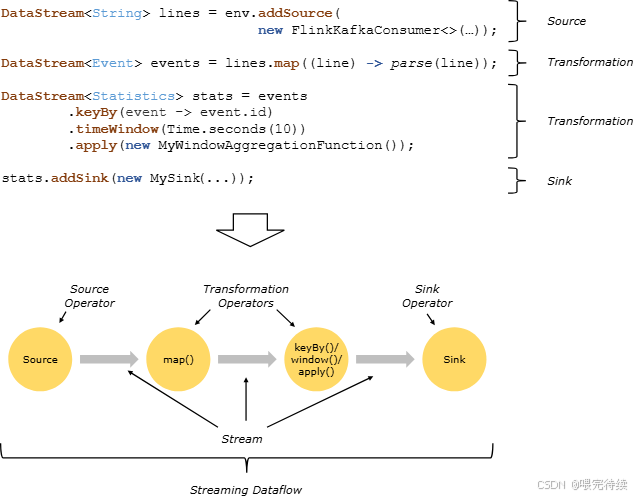
Java API实时表连接示例:
// 创建Flink环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 创建Kafka源表
tEnv.executeSql("CREATE TABLE kafka_source (\n" +
" user_id INT,\n" +
" item_id INT,\n" +
" event_time TIMESTAMP(3),\n" +
" event_type STRING,\n" +
" Watermark FOR event_time AS event_time - INTERVAL '5' SECONDS\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'user_events',\n" +
" 'properties.bootstrap.servers' = 'localhost:9092',\n" +
" 'format' = 'json'\n" +
")");
// 创建Paimon目标表
tEnv.executeSql("CREATE TABLE paimon sink (\n" +
" user_id INT,\n" +
" item_id INT,\n" +
" totalClicks BIGINT,\n" +
" PRIMARY KEY(user_id, item_id) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'paimon',\n" +
" 'path' = '/paimon-tables/userClicks',\n" +
" 'format' = 'parquet'\n" +
")");
// 执行实时表连接
tEnv.executeSql("INSERT INTO paimon sink\n" +
"SELECT user_id, item_id, COUNT(*) AS totalClicks\n" +
"FROM kafka_source\n" +
"WHERE event_type = 'click'\n" +
"GROUP BY TUMBLE(event_time, INTERVAL '1' HOUR), user_id, item_id");Python API实时表连接示例:
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment, EnvironmentSettings
# 创建Flink环境
env = StreamExecutionEnvironment.get_execution_environment()
env.set Parallelism(4)
t_env = StreamTableEnvironment.create(
env,
environment_settings=EnvironmentSettings.new实例()
.with_blinkPlanner()
.withStreamingTime特性()
.build())
# 添加Kafka连接器
t_env.execute_sql("""
CREATE TABLE kafka_source (
user_id INT,
item_id INT,
event_time TIMESTAMP(3),
event_type STRING,
Watermark FOR event_time AS event_time - INTERVAL '5' SECONDS
) WITH (
'connector' = 'kafka',
'topic' = 'user_events',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json'
)
""")
# 添加Paimon连接器
t_env.execute_sql("""
CREATE TABLE paimon_sink (
user_id INT,
item_id INT,
totalClicks BIGINT,
PRIMARY KEY(user_id, item_id) NOT ENFORCED
) WITH (
'connector' = 'paimon',
'path' = '/paimon-tables/userClicks',
0 'format' = 'parquet'
)
""")
# 执行实时表连接
t_env.execute_sql("""
INSERT INTO paimon_sink
SELECT user_id, item_id, COUNT(*) AS totalClicks
FROM kafka_source
WHERE event_type = 'click'
GROUP BY TUMBLE(event_time, INTERVAL '1' HOUR), user_id, item_id
""").wait()6.3 Checkpoint配置最佳实践
在生产环境中配置Checkpoint是确保Flink任务可靠性的关键:
// 设置Checkpoint模式为Exactly-Once
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 设置Checkpoint最小间隔为500ms
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 设置Checkpoint超时时间为60秒
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 设置最大并发Checkpoint数量为1
env.getCheckpointConfig()..setMaxConcurrentCheckpoints(1);
// 设置状态后端为RocksDB,支持大规模状态
env.setStateBackend(new RocksDBStateBackend("hdfs://namenode:8020/checkpoints", true));最佳实践:
-
定期Checkpoint:根据业务需求设置合理的Checkpoint间隔,通常在1-5分钟之间。
-
状态TTL配置:为大规模状态设置适当的TTL,避免状态无限增长:
// 设置状态TTL为1小时
env.getCheckpointConfig(). enableExternalizedCheckpoints(ExternalizedCheckpointConfig船舶模式.DELETE ON CANCELLATION);
env.getCheckpointConfig(). setCheckpointStorage("hdfs://namenode:8020/checkpoints");
env.getCheckpointConfig(). setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig(). setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig(). setCheckpointTimeout(60000);
env.getCheckpointConfig(). setMaxConcurrentCheckpoints(1);
env.setStateBackend(new RocksDBStateBackend("hdfs://namenode:8020/checkpoints", true));
env.getCheckpointConfig(). setCheckpointStorage("hdfs://namenode:8020/checkpoints");
env.getCheckpointConfig(). setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig(). setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig(). setCheckpointTimeout(60000);
env.getCheckpointConfig(). setMaxConcurrentCheckpoints(1);
env.setStateBackend(new RocksDBStateBackend("hdfs://namenode:8020/checkpoints", true));
env.getCheckpointConfig(). setCheckpointStorage("hdfs://namenode:8020/checkpoints");
env.getCheckpointConfig(). setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig(). setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig(). setCheckpointTimeout(60000);
env.getCheckpointConfig(). setMaxConcurrentCheckpoints(1);
envsetStateBackend(new RocksDBStateBackend("hdfs://namenode:8020/checkpoints", true));
env.getCheckpointConfig(). setCheckpointStorage("hdfs://namenode:8020/checkpoints");
env.getCheckpointConfig(). setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig(). setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig(). setCheckpointTimeout(60000);
env.getCheckpointConfig(). setMaxConcurrentCheckpoints(1);
envsetStateBackend(new RocksDBStateBackend("hdfs://namenode:8020/checkpoints", true));
env.getCheckpointConfig(). setCheckpointStorage("hdfs://namenode:8020/checkpoints");
env.getCheckpointConfig(). setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig(). setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig(). setCheckpointTimeout(60000);
env.getCheckpointConfig(). setMaxConcurrentCheckpoints(1);
envsetStateBackend(new RocksDBStateBackend("hdfs://namenode:8020/checkpoints", true));
env.getCheckpointConfig(). setCheckpointStorage("hdfs://namenode:8020/checkpoints");
env.getCheckpointConfig(). setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig(). setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig(). setCheckpointTimeout(60000);
env.getCheckpointConfig(). setMaxConcurrentCheckpoints(1);
envsetStateBackend(new RocksDBStateBackend("hdfs://namenode:8020/checkpoints", true));- Exactly-Once配置:确保数据源和数据接收器支持Exactly-Once语义,如Kafka消费者组:
// 配置Kafka消费者组支持Exactly-Once
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>(
"user_events",
new SimpleStringSchema(),
properties
);
kafkaSource.setCommit offsets true); // 启用Exactly-Once七、Flink的应用场景与价值
7.1 适用场景
Flink适用于多种实时计算场景:
-
实时推荐:通过实时分析用户行为数据,动态调整推荐策略,提高用户参与度和转化率。Flink能够处理每秒数万条的用户行为数据,并在毫秒级延迟内生成推荐结果。
-
实时风控:在金融领域,Flink能够实时监测交易事件,识别异常行为,防范欺诈风险。例如,银行可以使用Flink实时分析交易数据,检测异常模式并在几毫秒内触发警报。
-
实时监控:在物联网和工业监控领域,Flink能够实时处理传感器数据,监测设备状态,预测潜在故障。电力公司可以使用Flink实时分析电网数据,及时发现异常并采取措施。
-
实时ETL:Flink能够实时同步数据从源系统到目标系统,支持全增量一体化的数据集成 。例如,阿里巴巴使用Flink CDC(Change Data Capture)实时同步数据库变更到数据湖,实现分钟级的数据更新。
7.2 价值与优势
Flink为大数据平台带来了以下价值和优势:
-
简化架构:通过单一计算引擎替代Hadoop+Spark+Kafka Streams的组合,减少系统复杂性,降低运维成本。
-
提高时效性:支持实时数据摄入和查询,数据从采集到分析展示的流程不超过2秒,满足高实时性业务需求。
-
优化资源利用:通过状态本地化和内存优化,提高资源利用率,降低计算成本。
-
降低开发门槛:支持SQL查询和多种编程语言API(Java、Scala、Python等),开发人员无需掌握底层原理即可快速上手 。
-
提高查询性能:与Paimon等数据湖技术深度集成,支持高效的数据扫描和分析,提高实时查询性能。
八、Flink的未来发展趋势
8.1 云原生支持
Flink 2.0引入了存算分离状态管理,解决了容器化环境中本地磁盘限制和资源尖峰问题:
-
FORST状态后端:专为流处理设计,支持多路并行I/O和轻量级检查点,检查点效率提升50%以上,支持秒级TB级状态恢复。
-
Serverless集成:Flink与云原生平台(如AWS Kinesis、Google Pub/Sub)的深度集成,支持无服务器架构下的弹性扩缩容。
-
资源弹性调度:基于负载预测的在线迁移算法(如LPERS-Flink),减少调度滞后和性能波动,吞吐量提升约30% 。
8.2 流式湖仓架构
Flink与Paimon的深度集成将推动流式湖仓架构的发展:
-
分钟级数据更新:每一层数据都能实现分钟级别的更新,确保数据的新鲜度。在饿了么的案例中,Paimon实时中间层的应用使存储成本减少了约90%,Flink任务的资源开销也减少了大约50% 。
-
ACID事务支持:Paimon的CDC日志功能确保了数据变更的高效处理,支持ACID事务和高效查询。
-
生态扩展:与StarRocks、DataWorks等工具的集成将增强实时分析能力,但需解决元数据管理与权限控制问题 。
8.3 AI原生集成
Flink的低延迟和Exactly-Once特性使其成为实时AI流水线的理想选择:
-
实时特征工程:Flink SQL新增AI模型调用语法,支持动态调用LLM,实现特征工程与实时推理。
-
模型动态更新:通过状态管理机制,Flink可以支持机器学习模型的在线更新,实现模型效果的持续优化 。
-
流批融合训练:结合Flink的批处理能力,可以实现流批融合的机器学习模型训练,提高模型的准确性和泛化能力 。
8.4 性能优化
Flink将持续优化其性能和扩展性:
-
自适应批处理:Flink 2.0引入的自适应批处理机制,能够根据作业已完成的阶段信息,动态优化逻辑计划和物理计划。
-
增量Checkpoint:通过记录状态变更量,减少备份开销,加快快照过程,进而缩短快照周期,从而使得故障后回滚时间变短,加快故障恢复 。
-
零拷贝技术:通过Netty的Buffer管理实现堆外内存的零拷贝,降低内存复制带来的CPU周期消耗 。
九、总结与展望
9.1 Flink的技术地位
Apache Flink通过原生流处理架构和Exactly-Once容错机制,填补了传统批处理和流处理之间的空白,成为实时计算领域的事实标准。与Spark Streaming相比,Flink在低延迟和精确一次保证方面具有明显优势;与Kafka Streams相比,Flink提供了更强大的计算能力和更灵活的状态管理。
9.2 未来发展趋势
随着大数据技术的发展,Flink将在以下几个方向持续演进:
-
云原生支持:Flink 2.0的存算分离架构将使其在云环境中表现更加出色,支持大规模和动态扩展的场景。
-
流式湖仓:与Paimon的深度集成将推动流式湖仓架构的发展,实现分钟级数据更新,简化数据处理流程。
-
AI原生集成:Flink的低延迟和Exactly-Once特性将使其成为实时AI流水线的理想选择,支持实时特征工程和模型推理。
-
生态系统扩展:Flink将持续扩展其生态系统,与更多大数据组件(如Hive、Trino等)深度集成,提供更全面的数据处理解决方案 。
对于考虑使用Flink的企业,建议从小规模开始验证其性能和适用性,再逐步扩大应用范围。同时,应充分利用Flink与Kafka、Paimon等组件的集成,简化架构,降低运维成本。随着Flink 2.0的发布,其云原生支持和流式湖仓架构将进一步增强其在大数据生态系统中的地位,为企业提供更灵活、高效的实时数据处理解决方案。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)